 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention
Jun 11, 2024



In real-time speech communication systems, speech signals are often degraded by multiple distortions. Recently, a two-stage Repair-and-Denoising network (RaD-Net) was proposed with superior speech quality improvement in the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. However, failure to use future information and constraint receptive field of convolution layers limit the system's performance. To mitigate these problems, we extend RaD-Net to its upgraded version, RaD-Net 2. Specifically, a causality-based knowledge distillation is introduced in the first stage to use future information in a causal way. We use the non-causal repairing network as the teacher to improve the performance of the causal repairing network. In addition, in the second stage, complex axial self-attention is applied in the denoising network's complex feature encoder/decoder. Experimental results on the ICASSP 2024 SSI Challenge blind test set show that RaD-Net 2 brings 0.10 OVRL DNSMOS improvement compared to RaD-Net.
RaD-Net: A Repairing and Denoising Network for Speech Signal Improvement
Jan 09, 2024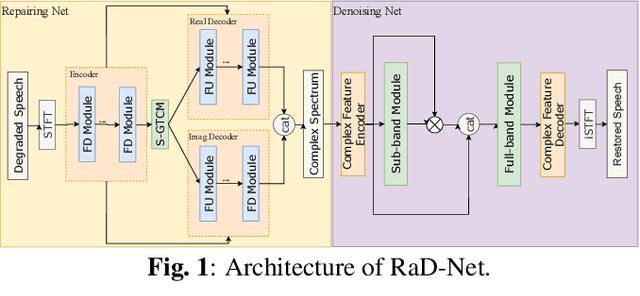
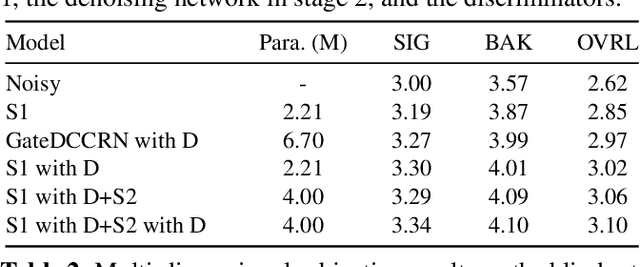
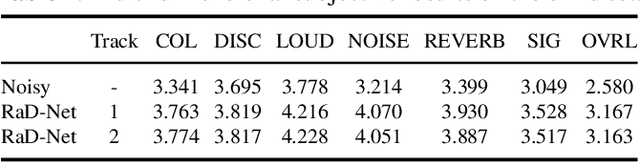
This paper introduces our repairing and denoising network (RaD-Net) for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. We extend our previous framework based on a two-stage network and propose an upgraded model. Specifically, we replace the repairing network with COM-Net from TEA-PSE. In addition, multi-resolution discriminators and multi-band discriminators are adopted in the training stage. Finally, we use a three-step training strategy to optimize our model. We submit two models with different sets of parameters to meet the RTF requirement of the two tracks. According to the official results, the proposed systems rank 2nd in track 1 and 3rd in track 2.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
An Exploration of Task-decoupling on Two-stage Neural Post Filter for Real-time Personalized Acoustic Echo Cancellation
Oct 07, 2023Deep learning based techniques have been popularly adopted in acoustic echo cancellation (AEC). Utilization of speaker representation has extended the frontier of AEC, thus attracting many researchers' interest in personalized acoustic echo cancellation (PAEC). Meanwhile, task-decoupling strategies are widely adopted in speech enhancement. To further explore the task-decoupling approach, we propose to use a two-stage task-decoupling post-filter (TDPF) in PAEC. Furthermore, a multi-scale local-global speaker representation is applied to improve speaker extraction in PAEC. Experimental results indicate that the task-decoupling model can yield better performance than a single joint network. The optimal approach is to decouple the echo cancellation from noise and interference speech suppression. Based on the task-decoupling sequence, optimal training strategies for the two-stage model are explored afterwards.
The NPU-Elevoc Personalized Speech Enhancement System for ICASSP2023 DNS Challenge
Mar 15, 2023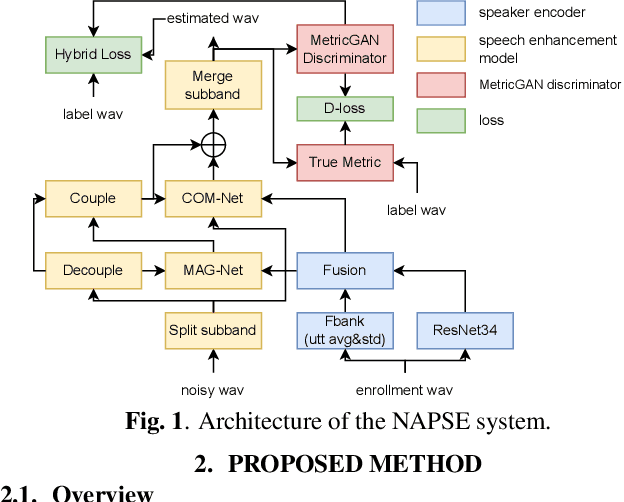

This paper describes our NPU-Elevoc personalized speech enhancement system (NAPSE) for the 5th Deep Noise Suppression Challenge at ICASSP 2023. Based on the superior two-stage model TEA-PSE 2.0, our system particularly explores better strategy for speaker embedding fusion, optimizes the model training pipeline, and leverages adversarial training and multi-scale loss. According to the results, our system is tied for the 1st place in the headset track (track 1) and ranked 2nd in the speakerphone track (track 2).
BagFormer: Better Cross-Modal Retrieval via bag-wise interaction
Dec 29, 2022



In the field of cross-modal retrieval, single encoder models tend to perform better than dual encoder models, but they suffer from high latency and low throughput. In this paper, we present a dual encoder model called BagFormer that utilizes a cross modal interaction mechanism to improve recall performance without sacrificing latency and throughput. BagFormer achieves this through the use of bag-wise interactions, which allow for the transformation of text to a more appropriate granularity and the incorporation of entity knowledge into the model. Our experiments demonstrate that BagFormer is able to achieve results comparable to state-of-the-art single encoder models in cross-modal retrieval tasks, while also offering efficient training and inference with 20.72 times lower latency and 25.74 times higher throughput.
Semantically Coherent Out-of-Distribution Detection
Aug 26, 2021
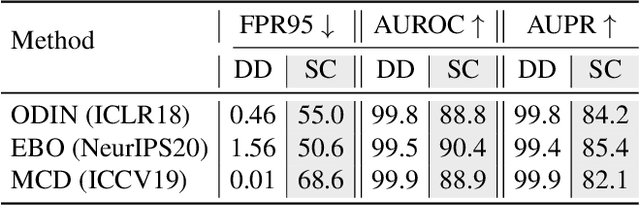
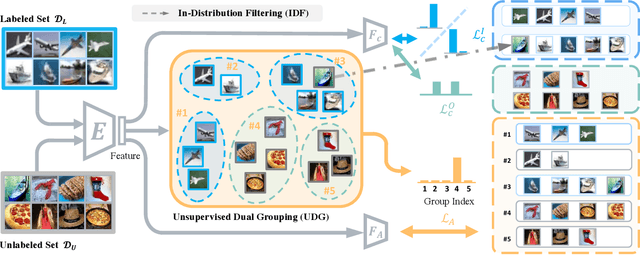
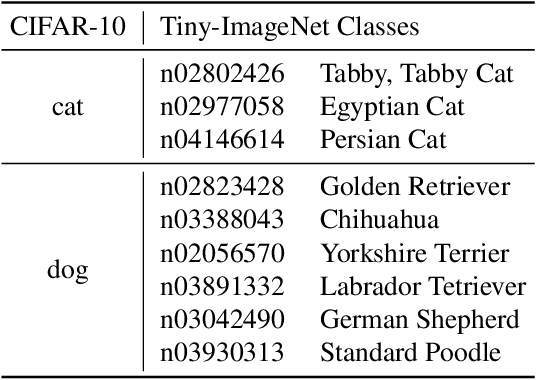
Current out-of-distribution (OOD) detection benchmarks are commonly built by defining one dataset as in-distribution (ID) and all others as OOD. However, these benchmarks unfortunately introduce some unwanted and impractical goals, e.g., to perfectly distinguish CIFAR dogs from ImageNet dogs, even though they have the same semantics and negligible covariate shifts. These unrealistic goals will result in an extremely narrow range of model capabilities, greatly limiting their use in real applications. To overcome these drawbacks, we re-design the benchmarks and propose the semantically coherent out-of-distribution detection (SC-OOD). On the SC-OOD benchmarks, existing methods suffer from large performance degradation, suggesting that they are extremely sensitive to low-level discrepancy between data sources while ignoring their inherent semantics. To develop an effective SC-OOD detection approach, we leverage an external unlabeled set and design a concise framework featured by unsupervised dual grouping (UDG) for the joint modeling of ID and OOD data. The proposed UDG can not only enrich the semantic knowledge of the model by exploiting unlabeled data in an unsupervised manner, but also distinguish ID/OOD samples to enhance ID classification and OOD detection tasks simultaneously. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on SC-OOD benchmarks. Code and benchmarks are provided on our project page: https://jingkang50.github.io/projects/scood.
Progressive Representative Labeling for Deep Semi-Supervised Learning
Aug 13, 2021



Deep semi-supervised learning (SSL) has experienced significant attention in recent years, to leverage a huge amount of unlabeled data to improve the performance of deep learning with limited labeled data. Pseudo-labeling is a popular approach to expand the labeled dataset. However, whether there is a more effective way of labeling remains an open problem. In this paper, we propose to label only the most representative samples to expand the labeled set. Representative samples, selected by indegree of corresponding nodes on a directed k-nearest neighbor (kNN) graph, lie in the k-nearest neighborhood of many other samples. We design a graph neural network (GNN) labeler to label them in a progressive learning manner. Aided by the progressive GNN labeler, our deep SSL approach outperforms state-of-the-art methods on several popular SSL benchmarks including CIFAR-10, SVHN, and ILSVRC-2012. Notably, we achieve 72.1% top-1 accuracy, surpassing the previous best result by 3.3%, on the challenging ImageNet benchmark with only $10\%$ labeled data.
Webly Supervised Image Classification with Metadata: Automatic Noisy Label Correction via Visual-Semantic Graph
Oct 12, 2020
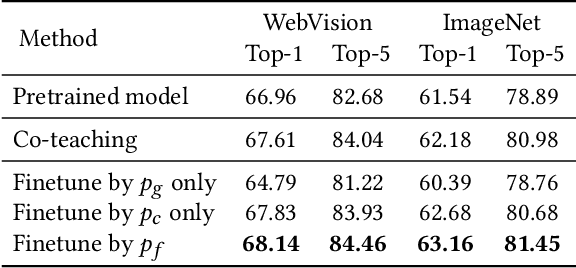
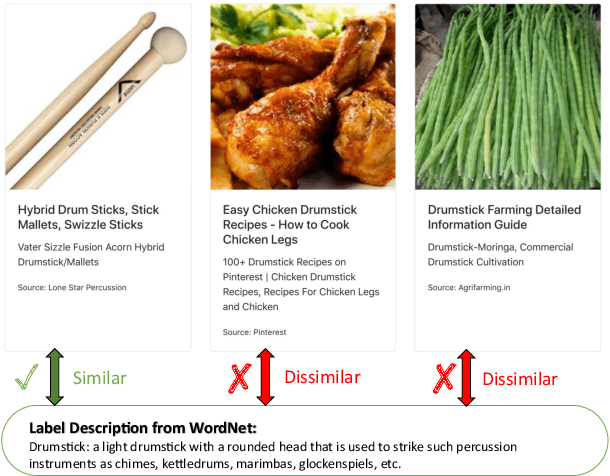
Webly supervised learning becomes attractive recently for its efficiency in data expansion without expensive human labeling. However, adopting search queries or hashtags as web labels of images for training brings massive noise that degrades the performance of DNNs. Especially, due to the semantic confusion of query words, the images retrieved by one query may contain tremendous images belonging to other concepts. For example, searching `tiger cat' on Flickr will return a dominating number of tiger images rather than the cat images. These realistic noisy samples usually have clear visual semantic clusters in the visual space that mislead DNNs from learning accurate semantic labels. To correct real-world noisy labels, expensive human annotations seem indispensable. Fortunately, we find that metadata can provide extra knowledge to discover clean web labels in a labor-free fashion, making it feasible to automatically provide correct semantic guidance among the massive label-noisy web data. In this paper, we propose an automatic label corrector VSGraph-LC based on the visual-semantic graph. VSGraph-LC starts from anchor selection referring to the semantic similarity between metadata and correct label concepts, and then propagates correct labels from anchors on a visual graph using graph neural network (GNN). Experiments on realistic webly supervised learning datasets Webvision-1000 and NUS-81-Web show the effectiveness and robustness of VSGraph-LC. Moreover, VSGraph-LC reveals its advantage on the open-set validation set.
Webly Supervised Image Classification with Self-Contained Confidence
Aug 27, 2020

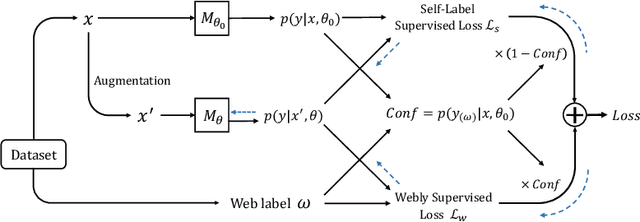
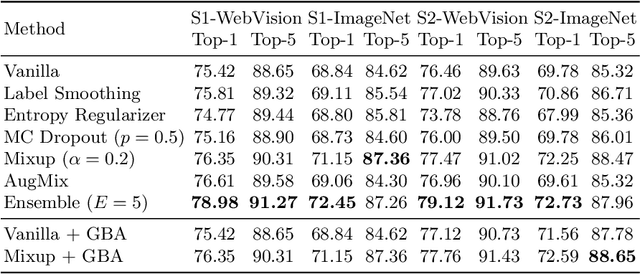
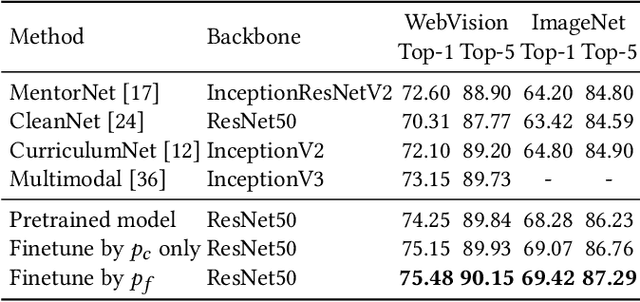
This paper focuses on webly supervised learning (WSL), where datasets are built by crawling samples from the Internet and directly using search queries as web labels. Although WSL benefits from fast and low-cost data collection, noises in web labels hinder better performance of the image classification model. To alleviate this problem, in recent works, self-label supervised loss $\mathcal{L}_s$ is utilized together with webly supervised loss $\mathcal{L}_w$. $\mathcal{L}_s$ relies on pseudo labels predicted by the model itself. Since the correctness of the web label or pseudo label is usually on a case-by-case basis for each web sample, it is desirable to adjust the balance between $\mathcal{L}_s$ and $\mathcal{L}_w$ on sample level. Inspired by the ability of Deep Neural Networks (DNNs) in confidence prediction, we introduce Self-Contained Confidence (SCC) by adapting model uncertainty for WSL setting, and use it to sample-wisely balance $\mathcal{L}_s$ and $\mathcal{L}_w$. Therefore, a simple yet effective WSL framework is proposed. A series of SCC-friendly regularization approaches are investigated, among which the proposed graph-enhanced mixup is the most effective method to provide high-quality confidence to enhance our framework. The proposed WSL framework has achieved the state-of-the-art results on two large-scale WSL datasets, WebVision-1000 and Food101-N. Code is available at https://github.com/bigvideoresearch/SCC.