 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack on Track: Bundle Adjustment for Dynamic Scene Reconstruction
Apr 20, 2025Traditional SLAM systems, which rely on bundle adjustment, struggle with highly dynamic scenes commonly found in casual videos. Such videos entangle the motion of dynamic elements, undermining the assumption of static environments required by traditional systems. Existing techniques either filter out dynamic elements or model their motion independently. However, the former often results in incomplete reconstructions, whereas the latter can lead to inconsistent motion estimates. Taking a novel approach, this work leverages a 3D point tracker to separate the camera-induced motion from the observed motion of dynamic objects. By considering only the camera-induced component, bundle adjustment can operate reliably on all scene elements as a result. We further ensure depth consistency across video frames with lightweight post-processing based on scale maps. Our framework combines the core of traditional SLAM -- bundle adjustment -- with a robust learning-based 3D tracker front-end. Integrating motion decomposition, bundle adjustment and depth refinement, our unified framework, BA-Track, accurately tracks the camera motion and produces temporally coherent and scale-consistent dense reconstructions, accommodating both static and dynamic elements. Our experiments on challenging datasets reveal significant improvements in camera pose estimation and 3D reconstruction accuracy.
AnyCam: Learning to Recover Camera Poses and Intrinsics from Casual Videos
Mar 30, 2025Estimating camera motion and intrinsics from casual videos is a core challenge in computer vision. Traditional bundle-adjustment based methods, such as SfM and SLAM, struggle to perform reliably on arbitrary data. Although specialized SfM approaches have been developed for handling dynamic scenes, they either require intrinsics or computationally expensive test-time optimization and often fall short in performance. Recently, methods like Dust3r have reformulated the SfM problem in a more data-driven way. While such techniques show promising results, they are still 1) not robust towards dynamic objects and 2) require labeled data for supervised training. As an alternative, we propose AnyCam, a fast transformer model that directly estimates camera poses and intrinsics from a dynamic video sequence in feed-forward fashion. Our intuition is that such a network can learn strong priors over realistic camera poses. To scale up our training, we rely on an uncertainty-based loss formulation and pre-trained depth and flow networks instead of motion or trajectory supervision. This allows us to use diverse, unlabelled video datasets obtained mostly from YouTube. Additionally, we ensure that the predicted trajectory does not accumulate drift over time through a lightweight trajectory refinement step. We test AnyCam on established datasets, where it delivers accurate camera poses and intrinsics both qualitatively and quantitatively. Furthermore, even with trajectory refinement, AnyCam is significantly faster than existing works for SfM in dynamic settings. Finally, by combining camera information, uncertainty, and depth, our model can produce high-quality 4D pointclouds.
DynSUP: Dynamic Gaussian Splatting from An Unposed Image Pair
Dec 01, 2024
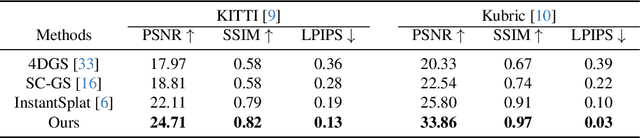
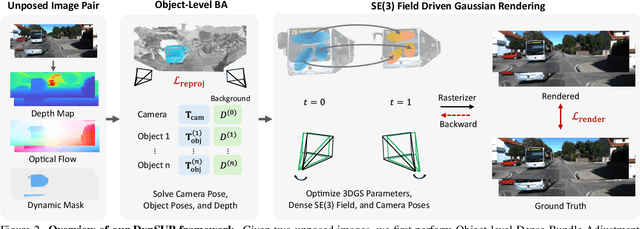
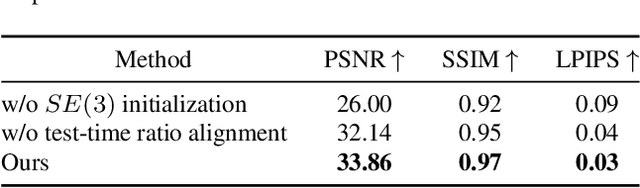
Recent advances in 3D Gaussian Splatting have shown promising results. Existing methods typically assume static scenes and/or multiple images with prior poses. Dynamics, sparse views, and unknown poses significantly increase the problem complexity due to insufficient geometric constraints. To overcome this challenge, we propose a method that can use only two images without prior poses to fit Gaussians in dynamic environments. To achieve this, we introduce two technical contributions. First, we propose an object-level two-view bundle adjustment. This strategy decomposes dynamic scenes into piece-wise rigid components, and jointly estimates the camera pose and motions of dynamic objects. Second, we design an SE(3) field-driven Gaussian training method. It enables fine-grained motion modeling through learnable per-Gaussian transformations. Our method leads to high-fidelity novel view synthesis of dynamic scenes while accurately preserving temporal consistency and object motion. Experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art approaches designed for the cases of static environments, multiple images, and/or known poses. Our project page is available at https://colin-de.github.io/DynSUP/.
LEAP-VO: Long-term Effective Any Point Tracking for Visual Odometry
Jan 03, 2024



Visual odometry estimates the motion of a moving camera based on visual input. Existing methods, mostly focusing on two-view point tracking, often ignore the rich temporal context in the image sequence, thereby overlooking the global motion patterns and providing no assessment of the full trajectory reliability. These shortcomings hinder performance in scenarios with occlusion, dynamic objects, and low-texture areas. To address these challenges, we present the Long-term Effective Any Point Tracking (LEAP) module. LEAP innovatively combines visual, inter-track, and temporal cues with mindfully selected anchors for dynamic track estimation. Moreover, LEAP's temporal probabilistic formulation integrates distribution updates into a learnable iterative refinement module to reason about point-wise uncertainty. Based on these traits, we develop LEAP-VO, a robust visual odometry system adept at handling occlusions and dynamic scenes. Our mindful integration showcases a novel practice by employing long-term point tracking as the front-end. Extensive experiments demonstrate that the proposed pipeline significantly outperforms existing baselines across various visual odometry benchmarks.
Leveraging Neural Radiance Fields for Uncertainty-Aware Visual Localization
Oct 10, 2023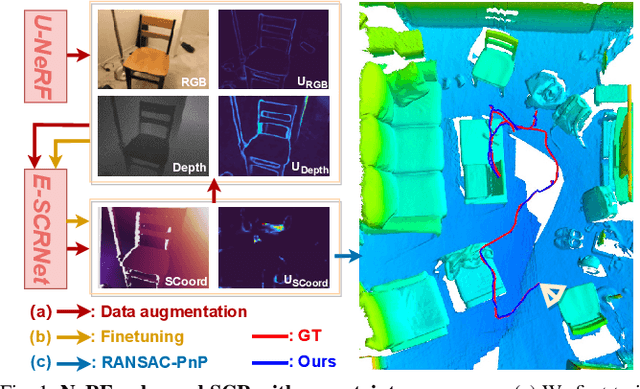



As a promising fashion for visual localization, scene coordinate regression (SCR) has seen tremendous progress in the past decade. Most recent methods usually adopt neural networks to learn the mapping from image pixels to 3D scene coordinates, which requires a vast amount of annotated training data. We propose to leverage Neural Radiance Fields (NeRF) to generate training samples for SCR. Despite NeRF's efficiency in rendering, many of the rendered data are polluted by artifacts or only contain minimal information gain, which can hinder the regression accuracy or bring unnecessary computational costs with redundant data. These challenges are addressed in three folds in this paper: (1) A NeRF is designed to separately predict uncertainties for the rendered color and depth images, which reveal data reliability at the pixel level. (2) SCR is formulated as deep evidential learning with epistemic uncertainty, which is used to evaluate information gain and scene coordinate quality. (3) Based on the three arts of uncertainties, a novel view selection policy is formed that significantly improves data efficiency. Experiments on public datasets demonstrate that our method could select the samples that bring the most information gain and promote the performance with the highest efficiency.
Uncertainty-Driven Dense Two-View Structure from Motion
Feb 12, 2023This work introduces an effective and practical solution to the dense two-view structure from motion (SfM) problem. One vital question addressed is how to mindfully use per-pixel optical flow correspondence between two frames for accurate pose estimation -- as perfect per-pixel correspondence between two images is difficult, if not impossible, to establish. With the carefully estimated camera pose and predicted per-pixel optical flow correspondences, a dense depth of the scene is computed. Later, an iterative refinement procedure is introduced to further improve optical flow matching confidence, camera pose, and depth, exploiting their inherent dependency in rigid SfM. The fundamental idea presented is to benefit from per-pixel uncertainty in the optical flow estimation and provide robustness to the dense SfM system via an online refinement. Concretely, we introduce our uncertainty-driven Dense Two-View SfM pipeline (DTV-SfM), consisting of an uncertainty-aware dense optical flow estimation approach that provides per-pixel correspondence with their confidence score of matching; a weighted dense bundle adjustment formulation that depends on optical flow uncertainty and bidirectional optical flow consistency to refine both pose and depth; a depth estimation network that considers its consistency with the estimated poses and optical flow respecting epipolar constraint. Extensive experiments show that the proposed approach achieves remarkable depth accuracy and state-of-the-art camera pose results superseding SuperPoint and SuperGlue accuracy when tested on benchmark datasets such as DeMoN, YFCC100M, and ScanNet. Code and more materials are available at http://vis.xyz/pub/dtv-sfm.
Webly Supervised Image Classification with Metadata: Automatic Noisy Label Correction via Visual-Semantic Graph
Oct 12, 2020
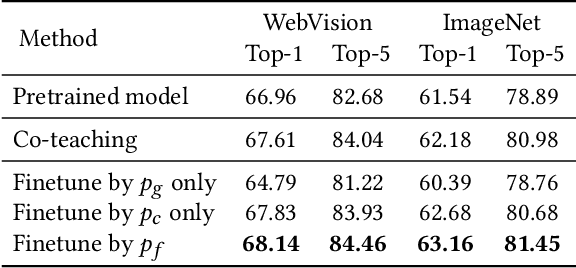
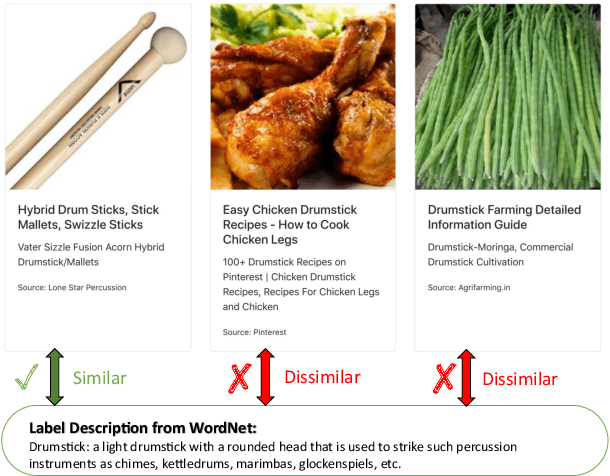
Webly supervised learning becomes attractive recently for its efficiency in data expansion without expensive human labeling. However, adopting search queries or hashtags as web labels of images for training brings massive noise that degrades the performance of DNNs. Especially, due to the semantic confusion of query words, the images retrieved by one query may contain tremendous images belonging to other concepts. For example, searching `tiger cat' on Flickr will return a dominating number of tiger images rather than the cat images. These realistic noisy samples usually have clear visual semantic clusters in the visual space that mislead DNNs from learning accurate semantic labels. To correct real-world noisy labels, expensive human annotations seem indispensable. Fortunately, we find that metadata can provide extra knowledge to discover clean web labels in a labor-free fashion, making it feasible to automatically provide correct semantic guidance among the massive label-noisy web data. In this paper, we propose an automatic label corrector VSGraph-LC based on the visual-semantic graph. VSGraph-LC starts from anchor selection referring to the semantic similarity between metadata and correct label concepts, and then propagates correct labels from anchors on a visual graph using graph neural network (GNN). Experiments on realistic webly supervised learning datasets Webvision-1000 and NUS-81-Web show the effectiveness and robustness of VSGraph-LC. Moreover, VSGraph-LC reveals its advantage on the open-set validation set.
Webly Supervised Image Classification with Self-Contained Confidence
Aug 27, 2020

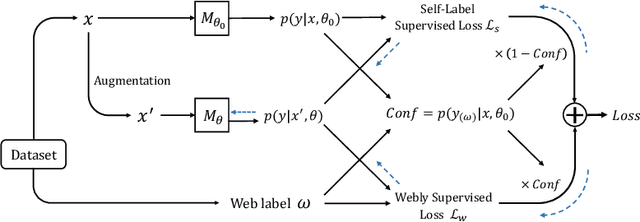
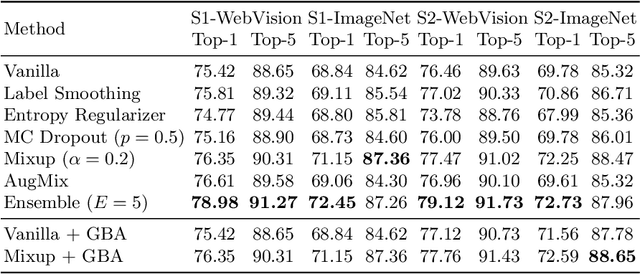
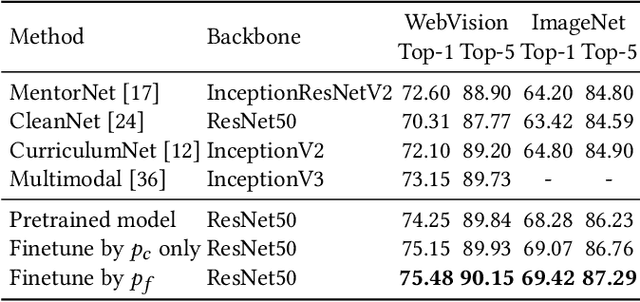
This paper focuses on webly supervised learning (WSL), where datasets are built by crawling samples from the Internet and directly using search queries as web labels. Although WSL benefits from fast and low-cost data collection, noises in web labels hinder better performance of the image classification model. To alleviate this problem, in recent works, self-label supervised loss $\mathcal{L}_s$ is utilized together with webly supervised loss $\mathcal{L}_w$. $\mathcal{L}_s$ relies on pseudo labels predicted by the model itself. Since the correctness of the web label or pseudo label is usually on a case-by-case basis for each web sample, it is desirable to adjust the balance between $\mathcal{L}_s$ and $\mathcal{L}_w$ on sample level. Inspired by the ability of Deep Neural Networks (DNNs) in confidence prediction, we introduce Self-Contained Confidence (SCC) by adapting model uncertainty for WSL setting, and use it to sample-wisely balance $\mathcal{L}_s$ and $\mathcal{L}_w$. Therefore, a simple yet effective WSL framework is proposed. A series of SCC-friendly regularization approaches are investigated, among which the proposed graph-enhanced mixup is the most effective method to provide high-quality confidence to enhance our framework. The proposed WSL framework has achieved the state-of-the-art results on two large-scale WSL datasets, WebVision-1000 and Food101-N. Code is available at https://github.com/bigvideoresearch/SCC.