 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Integration of Convolution and Attention for Vision Backbone
Nov 21, 2024Convolutions (Convs) and multi-head self-attentions (MHSAs) are typically considered alternatives to each other for building vision backbones. Although some works try to integrate both, they apply the two operators simultaneously at the finest pixel granularity. With Convs responsible for per-pixel feature extraction already, the question is whether we still need to include the heavy MHSAs at such a fine-grained level. In fact, this is the root cause of the scalability issue w.r.t. the input resolution for vision transformers. To address this important problem, we propose in this work to use MSHAs and Convs in parallel \textbf{at different granularity levels} instead. Specifically, in each layer, we use two different ways to represent an image: a fine-grained regular grid and a coarse-grained set of semantic slots. We apply different operations to these two representations: Convs to the grid for local features, and MHSAs to the slots for global features. A pair of fully differentiable soft clustering and dispatching modules is introduced to bridge the grid and set representations, thus enabling local-global fusion. Through extensive experiments on various vision tasks, we empirically verify the potential of the proposed integration scheme, named \textit{GLMix}: by offloading the burden of fine-grained features to light-weight Convs, it is sufficient to use MHSAs in a few (e.g., 64) semantic slots to match the performance of recent state-of-the-art backbones, while being more efficient. Our visualization results also demonstrate that the soft clustering module produces a meaningful semantic grouping effect with only IN1k classification supervision, which may induce better interpretability and inspire new weakly-supervised semantic segmentation approaches. Code will be available at \url{https://github.com/rayleizhu/GLMix}.
GeoGround: A Unified Large Vision-Language Model. for Remote Sensing Visual Grounding
Nov 16, 2024



Remote sensing (RS) visual grounding aims to use natural language expression to locate specific objects (in the form of the bounding box or segmentation mask) in RS images, enhancing human interaction with intelligent RS interpretation systems. Early research in this area was primarily based on horizontal bounding boxes (HBBs), but as more diverse RS datasets have become available, tasks involving oriented bounding boxes (OBBs) and segmentation masks have emerged. In practical applications, different targets require different grounding types: HBB can localize an object's position, OBB provides its orientation, and mask depicts its shape. However, existing specialized methods are typically tailored to a single type of RS visual grounding task and are hard to generalize across tasks. In contrast, large vision-language models (VLMs) exhibit powerful multi-task learning capabilities but struggle to handle dense prediction tasks like segmentation. This paper proposes GeoGround, a novel framework that unifies support for HBB, OBB, and mask RS visual grounding tasks, allowing flexible output selection. Rather than customizing the architecture of VLM, our work aims to elegantly support pixel-level visual grounding output through the Text-Mask technique. We define prompt-assisted and geometry-guided learning to enhance consistency across different signals. To support model training, we present refGeo, a large-scale RS visual instruction-following dataset containing 161k image-text pairs. Experimental results show that GeoGround demonstrates strong performance across four RS visual grounding tasks, matching or surpassing the performance of specialized methods on multiple benchmarks. Code available at https://github.com/zytx121/GeoGround
Text4Seg: Reimagining Image Segmentation as Text Generation
Oct 13, 2024
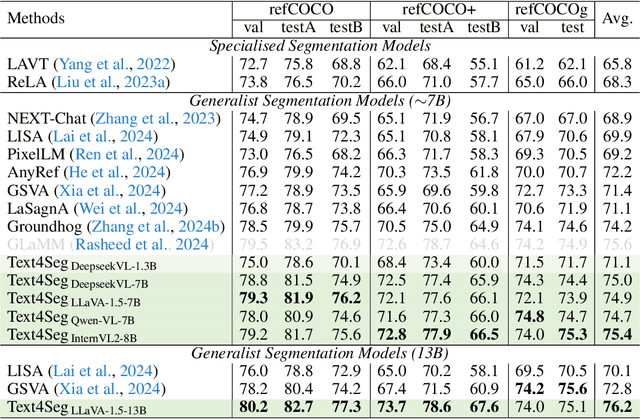
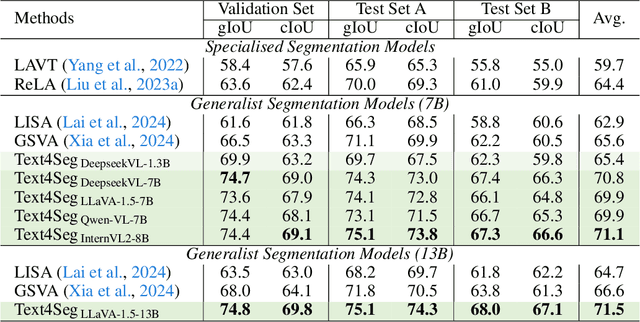
Multimodal Large Language Models (MLLMs) have shown exceptional capabilities in vision-language tasks; however, effectively integrating image segmentation into these models remains a significant challenge. In this paper, we introduce Text4Seg, a novel text-as-mask paradigm that casts image segmentation as a text generation problem, eliminating the need for additional decoders and significantly simplifying the segmentation process. Our key innovation is semantic descriptors, a new textual representation of segmentation masks where each image patch is mapped to its corresponding text label. This unified representation allows seamless integration into the auto-regressive training pipeline of MLLMs for easier optimization. We demonstrate that representing an image with $16\times16$ semantic descriptors yields competitive segmentation performance. To enhance efficiency, we introduce the Row-wise Run-Length Encoding (R-RLE), which compresses redundant text sequences, reducing the length of semantic descriptors by 74% and accelerating inference by $3\times$, without compromising performance. Extensive experiments across various vision tasks, such as referring expression segmentation and comprehension, show that Text4Seg achieves state-of-the-art performance on multiple datasets by fine-tuning different MLLM backbones. Our approach provides an efficient, scalable solution for vision-centric tasks within the MLLM framework.
ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation
Aug 09, 2024Open-vocabulary semantic segmentation requires models to effectively integrate visual representations with open-vocabulary semantic labels. While Contrastive Language-Image Pre-training (CLIP) models shine in recognizing visual concepts from text, they often struggle with segment coherence due to their limited localization ability. In contrast, Vision Foundation Models (VFMs) excel at acquiring spatially consistent local visual representations, yet they fall short in semantic understanding. This paper introduces ProxyCLIP, an innovative framework designed to harmonize the strengths of both CLIP and VFMs, facilitating enhanced open-vocabulary semantic segmentation. ProxyCLIP leverages the spatial feature correspondence from VFMs as a form of proxy attention to augment CLIP, thereby inheriting the VFMs' robust local consistency and maintaining CLIP's exceptional zero-shot transfer capacity. We propose an adaptive normalization and masking strategy to get the proxy attention from VFMs, allowing for adaptation across different VFMs. Remarkably, as a training-free approach, ProxyCLIP significantly improves the average mean Intersection over Union (mIoU) across eight benchmarks from 40.3 to 44.4, showcasing its exceptional efficacy in bridging the gap between spatial precision and semantic richness for the open-vocabulary segmentation task.
ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference
Jul 17, 2024



Despite the success of large-scale pretrained Vision-Language Models (VLMs) especially CLIP in various open-vocabulary tasks, their application to semantic segmentation remains challenging, producing noisy segmentation maps with mis-segmented regions. In this paper, we carefully re-investigate the architecture of CLIP, and identify residual connections as the primary source of noise that degrades segmentation quality. With a comparative analysis of statistical properties in the residual connection and the attention output across different pretrained models, we discover that CLIP's image-text contrastive training paradigm emphasizes global features at the expense of local discriminability, leading to noisy segmentation results. In response, we propose ClearCLIP, a novel approach that decomposes CLIP's representations to enhance open-vocabulary semantic segmentation. We introduce three simple modifications to the final layer: removing the residual connection, implementing the self-self attention, and discarding the feed-forward network. ClearCLIP consistently generates clearer and more accurate segmentation maps and outperforms existing approaches across multiple benchmarks, affirming the significance of our discoveries.
Towards Vision-Language Geo-Foundation Model: A Survey
Jun 13, 2024



Vision-Language Foundation Models (VLFMs) have made remarkable progress on various multimodal tasks, such as image captioning, image-text retrieval, visual question answering, and visual grounding. However, most methods rely on training with general image datasets, and the lack of geospatial data leads to poor performance on earth observation. Numerous geospatial image-text pair datasets and VLFMs fine-tuned on them have been proposed recently. These new approaches aim to leverage large-scale, multimodal geospatial data to build versatile intelligent models with diverse geo-perceptive capabilities, which we refer to as Vision-Language Geo-Foundation Models (VLGFMs). This paper thoroughly reviews VLGFMs, summarizing and analyzing recent developments in the field. In particular, we introduce the background and motivation behind the rise of VLGFMs, highlighting their unique research significance. Then, we systematically summarize the core technologies employed in VLGFMs, including data construction, model architectures, and applications of various multimodal geospatial tasks. Finally, we conclude with insights, issues, and discussions regarding future research directions. To the best of our knowledge, this is the first comprehensive literature review of VLGFMs. We keep tracing related works at https://github.com/zytx121/Awesome-VLGFM.
RelayAttention for Efficient Large Language Model Serving with Long System Prompts
Feb 29, 2024



Practical large language model (LLM) services may involve a long system prompt, which specifies the instructions, examples, and knowledge documents of the task and is reused across numerous requests. However, the long system prompt causes throughput/latency bottlenecks as the cost of generating the next token grows w.r.t. the sequence length. This paper aims to improve the efficiency of LLM services that involve long system prompts. Our key observation is that handling these system prompts requires heavily redundant memory accesses in existing causal attention computation algorithms. Specifically, for batched requests, the cached hidden states (i.e., key-value pairs) of system prompts are transferred from off-chip DRAM to on-chip SRAM multiple times, each corresponding to an individual request. To eliminate such a redundancy, we propose RelayAttention, an attention algorithm that allows reading these hidden states from DRAM exactly once for a batch of input tokens. RelayAttention is a free lunch: it maintains the generation quality while requiring no model retraining, as it is based on a mathematical reformulation of causal attention. Code is available at \url{https://github.com/rayleizhu/vllm-ra}.
Panoptic Video Scene Graph Generation
Nov 28, 2023
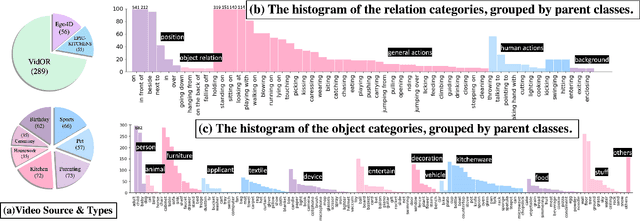
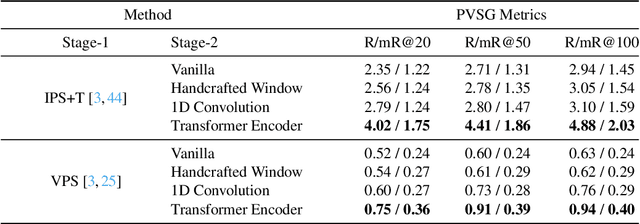
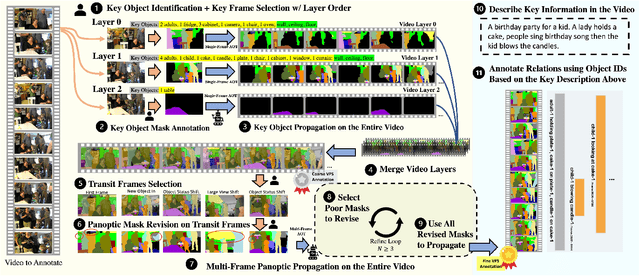
Towards building comprehensive real-world visual perception systems, we propose and study a new problem called panoptic scene graph generation (PVSG). PVSG relates to the existing video scene graph generation (VidSGG) problem, which focuses on temporal interactions between humans and objects grounded with bounding boxes in videos. However, the limitation of bounding boxes in detecting non-rigid objects and backgrounds often causes VidSGG to miss key details crucial for comprehensive video understanding. In contrast, PVSG requires nodes in scene graphs to be grounded by more precise, pixel-level segmentation masks, which facilitate holistic scene understanding. To advance research in this new area, we contribute the PVSG dataset, which consists of 400 videos (289 third-person + 111 egocentric videos) with a total of 150K frames labeled with panoptic segmentation masks as well as fine, temporal scene graphs. We also provide a variety of baseline methods and share useful design practices for future work.
SmooSeg: Smoothness Prior for Unsupervised Semantic Segmentation
Oct 27, 2023



Unsupervised semantic segmentation is a challenging task that segments images into semantic groups without manual annotation. Prior works have primarily focused on leveraging prior knowledge of semantic consistency or priori concepts from self-supervised learning methods, which often overlook the coherence property of image segments. In this paper, we demonstrate that the smoothness prior, asserting that close features in a metric space share the same semantics, can significantly simplify segmentation by casting unsupervised semantic segmentation as an energy minimization problem. Under this paradigm, we propose a novel approach called SmooSeg that harnesses self-supervised learning methods to model the closeness relationships among observations as smoothness signals. To effectively discover coherent semantic segments, we introduce a novel smoothness loss that promotes piecewise smoothness within segments while preserving discontinuities across different segments. Additionally, to further enhance segmentation quality, we design an asymmetric teacher-student style predictor that generates smoothly updated pseudo labels, facilitating an optimal fit between observations and labeling outputs. Thanks to the rich supervision cues of the smoothness prior, our SmooSeg significantly outperforms STEGO in terms of pixel accuracy on three datasets: COCOStuff (+14.9%), Cityscapes (+13.0%), and Potsdam-3 (+5.7%).
Diverse Cotraining Makes Strong Semi-Supervised Segmentor
Aug 18, 2023



Deep co-training has been introduced to semi-supervised segmentation and achieves impressive results, yet few studies have explored the working mechanism behind it. In this work, we revisit the core assumption that supports co-training: multiple compatible and conditionally independent views. By theoretically deriving the generalization upper bound, we prove the prediction similarity between two models negatively impacts the model's generalization ability. However, most current co-training models are tightly coupled together and violate this assumption. Such coupling leads to the homogenization of networks and confirmation bias which consequently limits the performance. To this end, we explore different dimensions of co-training and systematically increase the diversity from the aspects of input domains, different augmentations and model architectures to counteract homogenization. Our Diverse Co-training outperforms the state-of-the-art (SOTA) methods by a large margin across different evaluation protocols on the Pascal and Cityscapes. For example. we achieve the best mIoU of 76.2%, 77.7% and 80.2% on Pascal with only 92, 183 and 366 labeled images, surpassing the previous best results by more than 5%.