 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReturn of Frustratingly Easy Unsupervised Video Domain Adaptation
May 19, 2026Unsupervised video domain adaptation (UVDA) is a practical but under-explored problem. In this paper, we propose a frustratingly easy UVDA method, called MetaTrans. Specifically, MetaTrans adopts a concise learning objective that contains only two fundamental loss terms. Despite the simplicity of the learning objective, MetaTrans embodies an advanced UVDA idea, that is, handling the spatial and temporal divergence of cross-domain videos separately, through a subtle model architecture design. By implementing a temporal-static subtraction module, MetaTrans effectively removes spatial and temporal divergence. Extensive empirical evaluations, particularly on various cross-domain action recognition tasks, show substantial absolute adaptation performance enhancement and significantly superior relative performance gain compared with state-of-the-art UVDA baselines.
Toward a Multi-View Brain Network Foundation Model: Cross-View Consistency Learning Across Arbitrary Atlases
Mar 20, 2026Brain network analysis provides an interpretable framework for characterizing brain organization and has been widely used for neurological disorder identification. Recent advances in self-supervised learning have motivated the development of brain network foundation models. However, existing approaches are often limited by atlas dependency, insufficient exploitation of multiple network views, and weak incorporation of anatomical priors. In this work, we propose MV-BrainFM, a multi-view brain network foundation model designed to learn generalizable and scalable representations from brain networks constructed with arbitrary atlases. MV-BrainFM explicitly incorporates anatomical distance information into Transformer-based modeling to guide inter-regional interactions, and introduces an unsupervised cross-view consistency learning strategy to align representations from multiple atlases of the same subject in a shared latent space. By jointly enforcing within-view robustness and cross-view alignment during pretraining, the model effectively captures complementary information across heterogeneous network views while remaining atlas-aware. In addition, MV-BrainFM adopts a unified multi-view pretraining paradigm that enables simultaneous learning from multiple datasets and atlases, significantly improving computational efficiency compared to conventional sequential training strategies. The proposed framework also demonstrates strong scalability, consistently benefiting from increasing data diversity while maintaining stable performance across unseen atlas configurations. Extensive experiments on more than 20K subjects from 17 fMRI datasets show that MV-BrainFM consistently outperforms 14 existing brain network foundation models and task-specific baselines under both single-atlas and multi-atlas settings.
Directed Homophily-Aware Graph Neural Network
May 28, 2025Graph Neural Networks (GNNs) have achieved significant success in various learning tasks on graph-structured data. Nevertheless, most GNNs struggle to generalize to heterophilic neighborhoods. Additionally, many GNNs ignore the directional nature of real-world graphs, resulting in suboptimal performance on directed graphs with asymmetric structures. In this work, we propose Directed Homophily-aware Graph Neural Network (DHGNN), a novel framework that addresses these limitations by incorporating homophily-aware and direction-sensitive components. DHGNN employs a resettable gating mechanism to adaptively modulate message contributions based on homophily levels and informativeness, and a structure-aware noise-tolerant fusion module to effectively integrate node representations from the original and reverse directions. Extensive experiments on both homophilic and heterophilic directed graph datasets demonstrate that DHGNN outperforms state-of-the-art methods in node classification and link prediction. In particular, DHGNN improves over the best baseline by up to 15.07% in link prediction. Our analysis further shows that the gating mechanism captures directional homophily gaps and fluctuating homophily across layers, providing deeper insights into message-passing behavior on complex graph structures.
$α$-GAN by Rényi Cross Entropy
May 20, 2025This paper proposes $\alpha$-GAN, a generative adversarial network using R\'{e}nyi measures. The value function is formulated, by R\'{e}nyi cross entropy, as an expected certainty measure incurred by the discriminator's soft decision as to where the sample is from, true population or the generator. The discriminator tries to maximize the R\'{e}nyi certainty about sample source, while the generator wants to reduce it by injecting fake samples. This forms a min-max problem with the solution parameterized by the R\'{e}nyi order $\alpha$. This $\alpha$-GAN reduces to vanilla GAN at $\alpha = 1$, where the value function is exactly the binary cross entropy. The optimization of $\alpha$-GAN is over probability (vector) space. It is shown that the gradient is exponentially enlarged when R\'{e}nyi order is in the range $\alpha \in (0,1)$. This makes convergence faster, which is verified by experimental results. A discussion shows that choosing $\alpha \in (0,1)$ may be able to solve some common problems, e.g., vanishing gradient. A following observation reveals that this range has not been fully explored in the existing R\'{e}nyi version GANs.
Divergent Paths: Separating Homophilic and Heterophilic Learning for Enhanced Graph-level Representations
Apr 06, 2025Graph Convolutional Networks (GCNs) are predominantly tailored for graphs displaying homophily, where similar nodes connect, but often fail on heterophilic graphs. The strategy of adopting distinct approaches to learn from homophilic and heterophilic components in node-level tasks has been widely discussed and proven effective both theoretically and experimentally. However, in graph-level tasks, research on this topic remains notably scarce. Addressing this gap, our research conducts an analysis on graphs with nodes' category ID available, distinguishing intra-category and inter-category components as embodiment of homophily and heterophily, respectively. We find while GCNs excel at extracting information within categories, they frequently capture noise from inter-category components. Consequently, it is crucial to employ distinct learning strategies for intra- and inter-category elements. To alleviate this problem, we separately learn the intra- and inter-category parts by a combination of an intra-category convolution (IntraNet) and an inter-category high-pass graph convolution (InterNet). Our IntraNet is supported by sophisticated graph preprocessing steps and a novel category-based graph readout function. For the InterNet, we utilize a high-pass filter to amplify the node disparities, enhancing the recognition of details in the high-frequency components. The proposed approach, DivGNN, combines the IntraNet and InterNet with a gated mechanism and substantially improves classification performance on graph-level tasks, surpassing traditional GNN baselines in effectiveness.
BrainOOD: Out-of-distribution Generalizable Brain Network Analysis
Feb 02, 2025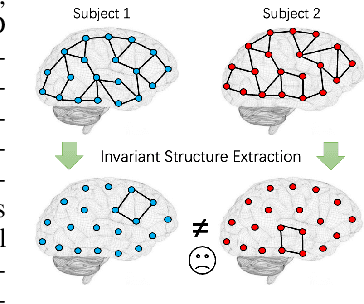

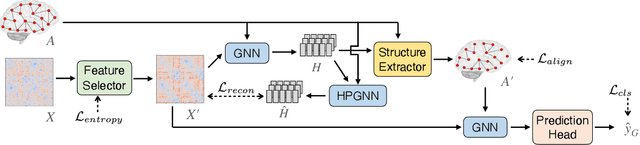
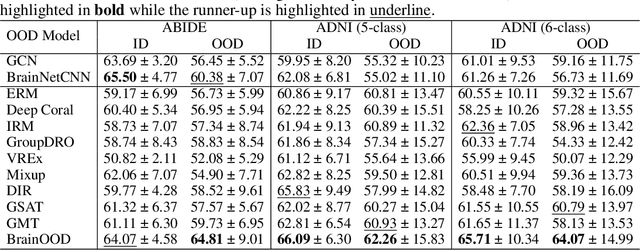
In neuroscience, identifying distinct patterns linked to neurological disorders, such as Alzheimer's and Autism, is critical for early diagnosis and effective intervention. Graph Neural Networks (GNNs) have shown promising in analyzing brain networks, but there are two major challenges in using GNNs: (1) distribution shifts in multi-site brain network data, leading to poor Out-of-Distribution (OOD) generalization, and (2) limited interpretability in identifying key brain regions critical to neurological disorders. Existing graph OOD methods, while effective in other domains, struggle with the unique characteristics of brain networks. To bridge these gaps, we introduce BrainOOD, a novel framework tailored for brain networks that enhances GNNs' OOD generalization and interpretability. BrainOOD framework consists of a feature selector and a structure extractor, which incorporates various auxiliary losses including an improved Graph Information Bottleneck (GIB) objective to recover causal subgraphs. By aligning structure selection across brain networks and filtering noisy features, BrainOOD offers reliable interpretations of critical brain regions. Our approach outperforms 16 existing methods and improves generalization to OOD subjects by up to 8.5%. Case studies highlight the scientific validity of the patterns extracted, which aligns with the findings in known neuroscience literature. We also propose the first OOD brain network benchmark, which provides a foundation for future research in this field. Our code is available at https://github.com/AngusMonroe/BrainOOD.
ABXI: Invariant Interest Adaptation for Task-Guided Cross-Domain Sequential Recommendation
Jan 25, 2025



Cross-Domain Sequential Recommendation (CDSR) has recently gained attention for countering data sparsity by transferring knowledge across domains. A common approach merges domain-specific sequences into cross-domain sequences, serving as bridges to connect domains. One key challenge is to correctly extract the shared knowledge among these sequences and appropriately transfer it. Most existing works directly transfer unfiltered cross-domain knowledge rather than extracting domain-invariant components and adaptively integrating them into domain-specific modelings. Another challenge lies in aligning the domain-specific and cross-domain sequences. Existing methods align these sequences based on timestamps, but this approach can cause prediction mismatches when the current tokens and their targets belong to different domains. In such cases, the domain-specific knowledge carried by the current tokens may degrade performance. To address these challenges, we propose the A-B-Cross-to-Invariant Learning Recommender (ABXI). Specifically, leveraging LoRA's effectiveness for efficient adaptation, ABXI incorporates two types of LoRAs to facilitate knowledge adaptation. First, all sequences are processed through a shared encoder that employs a domain LoRA for each sequence, thereby preserving unique domain characteristics. Next, we introduce an invariant projector that extracts domain-invariant interests from cross-domain representations, utilizing an invariant LoRA to adapt these interests into modeling each specific domain. Besides, to avoid prediction mismatches, all domain-specific sequences are aligned to match the domains of the cross-domain ground truths. Experimental results on three datasets demonstrate that our approach outperforms other CDSR counterparts by a large margin. The codes are available in \url{https://github.com/DiMarzioBian/ABXI}.
GeoGround: A Unified Large Vision-Language Model. for Remote Sensing Visual Grounding
Nov 16, 2024



Remote sensing (RS) visual grounding aims to use natural language expression to locate specific objects (in the form of the bounding box or segmentation mask) in RS images, enhancing human interaction with intelligent RS interpretation systems. Early research in this area was primarily based on horizontal bounding boxes (HBBs), but as more diverse RS datasets have become available, tasks involving oriented bounding boxes (OBBs) and segmentation masks have emerged. In practical applications, different targets require different grounding types: HBB can localize an object's position, OBB provides its orientation, and mask depicts its shape. However, existing specialized methods are typically tailored to a single type of RS visual grounding task and are hard to generalize across tasks. In contrast, large vision-language models (VLMs) exhibit powerful multi-task learning capabilities but struggle to handle dense prediction tasks like segmentation. This paper proposes GeoGround, a novel framework that unifies support for HBB, OBB, and mask RS visual grounding tasks, allowing flexible output selection. Rather than customizing the architecture of VLM, our work aims to elegantly support pixel-level visual grounding output through the Text-Mask technique. We define prompt-assisted and geometry-guided learning to enhance consistency across different signals. To support model training, we present refGeo, a large-scale RS visual instruction-following dataset containing 161k image-text pairs. Experimental results show that GeoGround demonstrates strong performance across four RS visual grounding tasks, matching or surpassing the performance of specialized methods on multiple benchmarks. Code available at https://github.com/zytx121/GeoGround
Text4Seg: Reimagining Image Segmentation as Text Generation
Oct 13, 2024
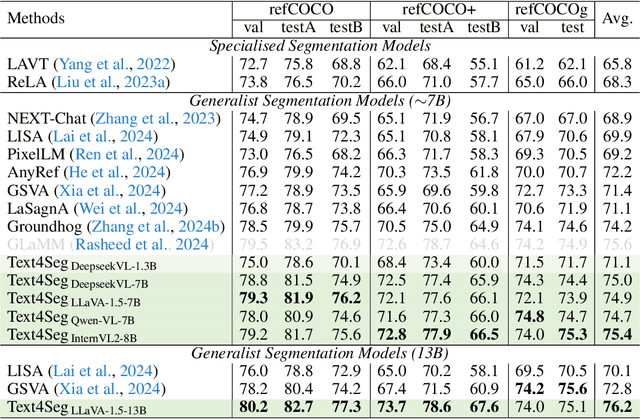
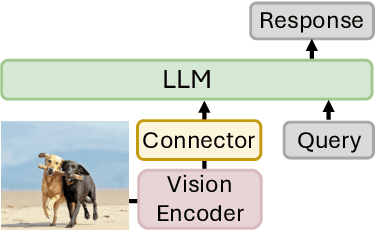
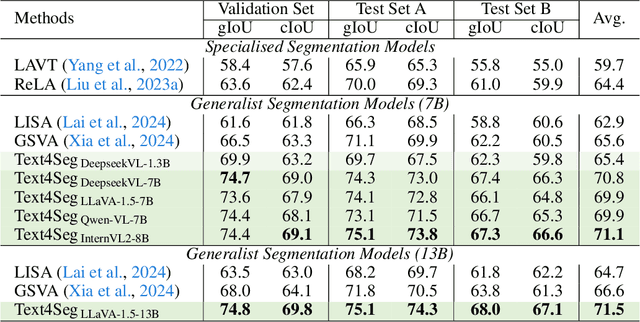
Multimodal Large Language Models (MLLMs) have shown exceptional capabilities in vision-language tasks; however, effectively integrating image segmentation into these models remains a significant challenge. In this paper, we introduce Text4Seg, a novel text-as-mask paradigm that casts image segmentation as a text generation problem, eliminating the need for additional decoders and significantly simplifying the segmentation process. Our key innovation is semantic descriptors, a new textual representation of segmentation masks where each image patch is mapped to its corresponding text label. This unified representation allows seamless integration into the auto-regressive training pipeline of MLLMs for easier optimization. We demonstrate that representing an image with $16\times16$ semantic descriptors yields competitive segmentation performance. To enhance efficiency, we introduce the Row-wise Run-Length Encoding (R-RLE), which compresses redundant text sequences, reducing the length of semantic descriptors by 74% and accelerating inference by $3\times$, without compromising performance. Extensive experiments across various vision tasks, such as referring expression segmentation and comprehension, show that Text4Seg achieves state-of-the-art performance on multiple datasets by fine-tuning different MLLM backbones. Our approach provides an efficient, scalable solution for vision-centric tasks within the MLLM framework.
Contrasformer: A Brain Network Contrastive Transformer for Neurodegenerative Condition Identification
Sep 17, 2024Understanding neurological disorder is a fundamental problem in neuroscience, which often requires the analysis of brain networks derived from functional magnetic resonance imaging (fMRI) data. Despite the prevalence of Graph Neural Networks (GNNs) and Graph Transformers in various domains, applying them to brain networks faces challenges. Specifically, the datasets are severely impacted by the noises caused by distribution shifts across sub-populations and the neglect of node identities, both obstruct the identification of disease-specific patterns. To tackle these challenges, we propose Contrasformer, a novel contrastive brain network Transformer. It generates a prior-knowledge-enhanced contrast graph to address the distribution shifts across sub-populations by a two-stream attention mechanism. A cross attention with identity embedding highlights the identity of nodes, and three auxiliary losses ensure group consistency. Evaluated on 4 functional brain network datasets over 4 different diseases, Contrasformer outperforms the state-of-the-art methods for brain networks by achieving up to 10.8\% improvement in accuracy, which demonstrates its efficacy in neurological disorder identification. Case studies illustrate its interpretability, especially in the context of neuroscience. This paper provides a solution for analyzing brain networks, offering valuable insights into neurological disorders. Our code is available at \url{https://github.com/AngusMonroe/Contrasformer}.