 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM agents
Mar 12, 2026Reinforcement learning (RL) with outcome-based rewards has achieved significant success in training large language model (LLM) agents for complex reasoning tasks. However, in active reasoning where agents need to strategically ask questions to acquire task-relevant information, we find that LLM agents trained with RL often suffer from information self-locking: the agent ceases to ask informative questions and struggles to internalize already-obtained information. To understand the phenomenon, we decompose active reasoning into two core capabilities: Action Selection (AS), which determines the observation stream through queries, and Belief Tracking (BT), which updates the agent's belief based on collected evidence. We show that deficient AS and BT capabilities will limit the information exploration during RL training. Furthermore, insufficient exploration in turn hinders the improvement of AS and BT, creating a feedback loop that locks the agent in a low-information regime. To resolve the issue, we propose a simple yet effective approach that reallocates the learning signal by injecting easy- to-obtain directional critiques to help the agent escape self-locking. Extensive experiments with 7 datasets show that our approach significantly mitigates the information self-locking, bringing up to 60% improvements.
Video Reality Test: Can AI-Generated ASMR Videos fool VLMs and Humans?
Dec 18, 2025Recent advances in video generation have produced vivid content that are often indistinguishable from real videos, making AI-generated video detection an emerging societal challenge. Prior AIGC detection benchmarks mostly evaluate video without audio, target broad narrative domains, and focus on classification solely. Yet it remains unclear whether state-of-the-art video generation models can produce immersive, audio-paired videos that reliably deceive humans and VLMs. To this end, we introduce Video Reality Test, an ASMR-sourced video benchmark suite for testing perceptual realism under tight audio-visual coupling, featuring the following dimensions: (i) Immersive ASMR video-audio sources. Built on carefully curated real ASMR videos, the benchmark targets fine-grained action-object interactions with diversity across objects, actions, and backgrounds. (ii) Peer-Review evaluation. An adversarial creator-reviewer protocol where video generation models act as creators aiming to fool reviewers, while VLMs serve as reviewers seeking to identify fakeness. Our experimental findings show: The best creator Veo3.1-Fast even fools most VLMs: the strongest reviewer (Gemini 2.5-Pro) achieves only 56% accuracy (random 50%), far below that of human experts (81.25%). Adding audio improves real-fake discrimination, yet superficial cues such as watermarks can still significantly mislead models. These findings delineate the current boundary of video generation realism and expose limitations of VLMs in perceptual fidelity and audio-visual consistency. Our code is available at https://github.com/video-reality-test/video-reality-test.
Search-R3: Unifying Reasoning and Embedding Generation in Large Language Models
Oct 08, 2025
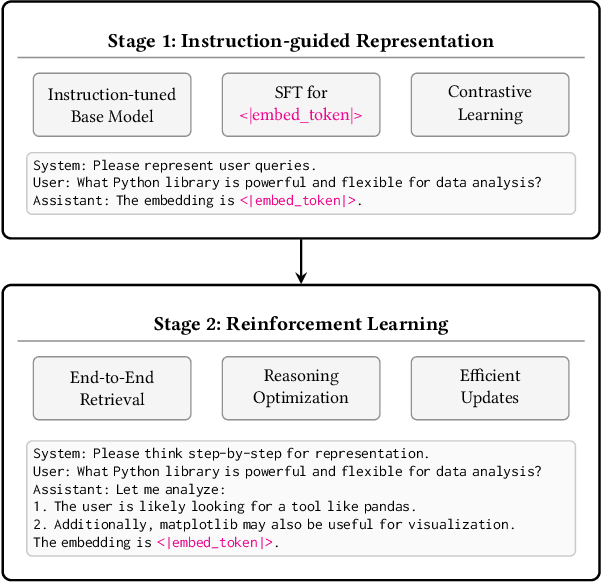
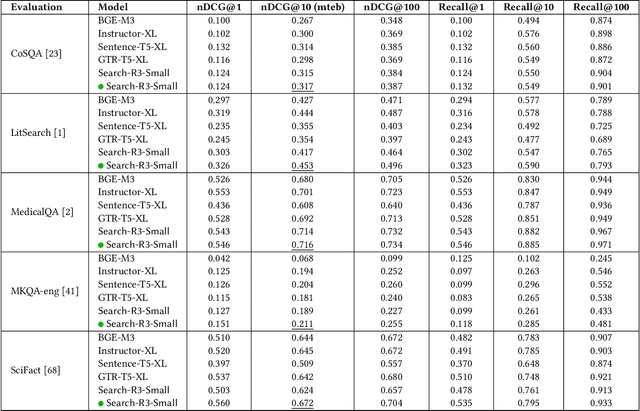
Despite their remarkable natural language understanding capabilities, Large Language Models (LLMs) have been underutilized for retrieval tasks. We present Search-R3, a novel framework that addresses this limitation by adapting LLMs to generate search embeddings as a direct output of their reasoning process. Our approach exploits LLMs' chain-of-thought capabilities, allowing them to produce more effective embeddings by reasoning step-by-step through complex semantic analyses. We implement this through three complementary mechanisms. (1) a supervised learning stage enables the model's ability to produce quality embeddings, (2) a reinforcement learning (RL) methodology that optimizes embedding generation alongside reasoning, and (3) a specialized RL environment that efficiently handles evolving embedding representations without requiring complete corpus re-encoding at each training iteration. Our extensive evaluations on diverse benchmarks demonstrate that Search-R3 significantly outperforms prior methods by unifying the reasoning and embedding generation processes. This integrated post-training approach represents a substantial advancement in handling complex knowledge-intensive tasks that require both sophisticated reasoning and effective information retrieval. Project page: https://github.com/ytgui/Search-R3
MESH -- Understanding Videos Like Human: Measuring Hallucinations in Large Video Models
Sep 10, 2025Large Video Models (LVMs) build on the semantic capabilities of Large Language Models (LLMs) and vision modules by integrating temporal information to better understand dynamic video content. Despite their progress, LVMs are prone to hallucinations-producing inaccurate or irrelevant descriptions. Current benchmarks for video hallucination depend heavily on manual categorization of video content, neglecting the perception-based processes through which humans naturally interpret videos. We introduce MESH, a benchmark designed to evaluate hallucinations in LVMs systematically. MESH uses a Question-Answering framework with binary and multi-choice formats incorporating target and trap instances. It follows a bottom-up approach, evaluating basic objects, coarse-to-fine subject features, and subject-action pairs, aligning with human video understanding. We demonstrate that MESH offers an effective and comprehensive approach for identifying hallucinations in videos. Our evaluations show that while LVMs excel at recognizing basic objects and features, their susceptibility to hallucinations increases markedly when handling fine details or aligning multiple actions involving various subjects in longer videos.
Think or Not? Selective Reasoning via Reinforcement Learning for Vision-Language Models
May 22, 2025Reinforcement Learning (RL) has proven to be an effective post-training strategy for enhancing reasoning in vision-language models (VLMs). Group Relative Policy Optimization (GRPO) is a recent prominent method that encourages models to generate complete reasoning traces before answering, leading to increased token usage and computational cost. Inspired by the human-like thinking process-where people skip reasoning for easy questions but think carefully when needed-we explore how to enable VLMs to first decide when reasoning is necessary. To realize this, we propose TON, a two-stage training strategy: (i) a supervised fine-tuning (SFT) stage with a simple yet effective 'thought dropout' operation, where reasoning traces are randomly replaced with empty thoughts. This introduces a think-or-not format that serves as a cold start for selective reasoning; (ii) a GRPO stage that enables the model to freely explore when to think or not, while maximizing task-aware outcome rewards. Experimental results show that TON can reduce the completion length by up to 90% compared to vanilla GRPO, without sacrificing performance or even improving it. Further evaluations across diverse vision-language tasks-covering a range of reasoning difficulties under both 3B and 7B models-consistently reveal that the model progressively learns to bypass unnecessary reasoning steps as training advances. These findings shed light on the path toward human-like reasoning patterns in reinforcement learning approaches. Our code is available at https://github.com/kokolerk/TON.
On the Thinking-Language Modeling Gap in Large Language Models
May 19, 2025
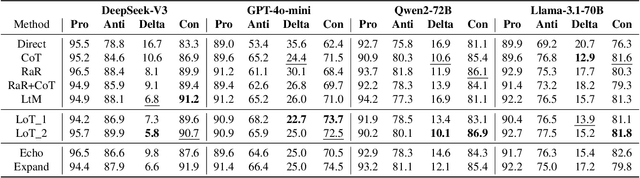

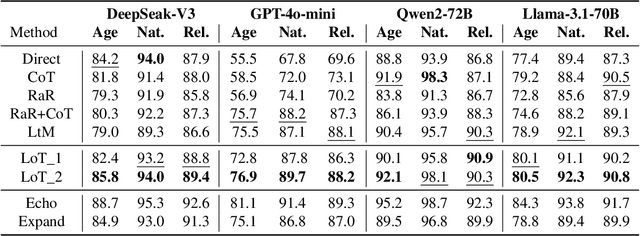
System 2 reasoning is one of the defining characteristics of intelligence, which requires slow and logical thinking. Human conducts System 2 reasoning via the language of thoughts that organizes the reasoning process as a causal sequence of mental language, or thoughts. Recently, it has been observed that System 2 reasoning can be elicited from Large Language Models (LLMs) pre-trained on large-scale natural languages. However, in this work, we show that there is a significant gap between the modeling of languages and thoughts. As language is primarily a tool for humans to share knowledge and thinking, modeling human language can easily absorb language biases into LLMs deviated from the chain of thoughts in minds. Furthermore, we show that the biases will mislead the eliciting of "thoughts" in LLMs to focus only on a biased part of the premise. To this end, we propose a new prompt technique termed Language-of-Thoughts (LoT) to demonstrate and alleviate this gap. Instead of directly eliciting the chain of thoughts from partial information, LoT instructs LLMs to adjust the order and token used for the expressions of all the relevant information. We show that the simple strategy significantly reduces the language modeling biases in LLMs and improves the performance of LLMs across a variety of reasoning tasks.
DivIL: Unveiling and Addressing Over-Invariance for Out-of- Distribution Generalization
Feb 18, 2025Out-of-distribution generalization is a common problem that expects the model to perform well in the different distributions even far from the train data. A popular approach to addressing this issue is invariant learning (IL), in which the model is compiled to focus on invariant features instead of spurious features by adding strong constraints during training. However, there are some potential pitfalls of strong invariant constraints. Due to the limited number of diverse environments and over-regularization in the feature space, it may lead to a loss of important details in the invariant features while alleviating the spurious correlations, namely the over-invariance, which can also degrade the generalization performance. We theoretically define the over-invariance and observe that this issue occurs in various classic IL methods. To alleviate this issue, we propose a simple approach Diverse Invariant Learning (DivIL) by adding the unsupervised contrastive learning and the random masking mechanism compensatory for the invariant constraints, which can be applied to various IL methods. Furthermore, we conduct experiments across multiple modalities across 12 datasets and 6 classic models, verifying our over-invariance insight and the effectiveness of our DivIL framework. Our code is available at https://github.com/kokolerk/DivIL.
Oversmoothing as Loss of Sign: Towards Structural Balance in Graph Neural Networks
Feb 17, 2025



Oversmoothing is a common issue in graph neural networks (GNNs), where node representations become excessively homogeneous as the number of layers increases, resulting in degraded performance. Various strategies have been proposed to combat oversmoothing in practice, yet they are based on different heuristics and lack a unified understanding of their inherent mechanisms. In this paper, we show that three major classes of anti-oversmoothing techniques can be mathematically interpreted as message passing over signed graphs comprising both positive and negative edges. By analyzing the asymptotic behavior of signed graph propagation, we demonstrate that negative edges can repel nodes to a certain extent, providing deeper insights into how these methods mitigate oversmoothing. Furthermore, our results suggest that the structural balance of a signed graph-where positive edges exist only within clusters and negative edges appear only between clusters-is crucial for clustering node representations in the long term through signed graph propagation. Motivated by these observations, we propose a solution to mitigate oversmoothing with theoretical guarantees-Structural Balance Propagation (SBP), by incorporating label and feature information to create a structurally balanced graph for message-passing. Experiments on nine datasets against twelve baselines demonstrate the effectiveness of our method, highlighting the value of our signed graph perspective.
BrainOOD: Out-of-distribution Generalizable Brain Network Analysis
Feb 02, 2025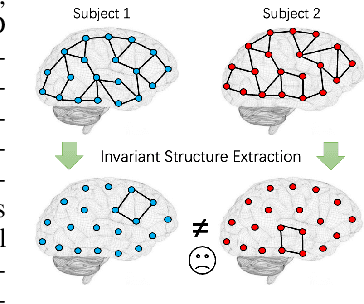

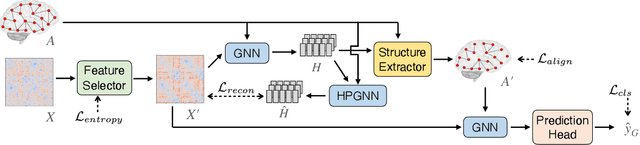
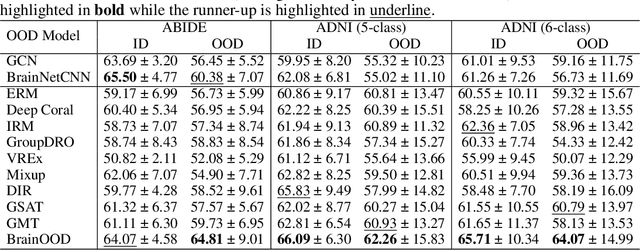
In neuroscience, identifying distinct patterns linked to neurological disorders, such as Alzheimer's and Autism, is critical for early diagnosis and effective intervention. Graph Neural Networks (GNNs) have shown promising in analyzing brain networks, but there are two major challenges in using GNNs: (1) distribution shifts in multi-site brain network data, leading to poor Out-of-Distribution (OOD) generalization, and (2) limited interpretability in identifying key brain regions critical to neurological disorders. Existing graph OOD methods, while effective in other domains, struggle with the unique characteristics of brain networks. To bridge these gaps, we introduce BrainOOD, a novel framework tailored for brain networks that enhances GNNs' OOD generalization and interpretability. BrainOOD framework consists of a feature selector and a structure extractor, which incorporates various auxiliary losses including an improved Graph Information Bottleneck (GIB) objective to recover causal subgraphs. By aligning structure selection across brain networks and filtering noisy features, BrainOOD offers reliable interpretations of critical brain regions. Our approach outperforms 16 existing methods and improves generalization to OOD subjects by up to 8.5%. Case studies highlight the scientific validity of the patterns extracted, which aligns with the findings in known neuroscience literature. We also propose the first OOD brain network benchmark, which provides a foundation for future research in this field. Our code is available at https://github.com/AngusMonroe/BrainOOD.
HIGHT: Hierarchical Graph Tokenization for Graph-Language Alignment
Jun 20, 2024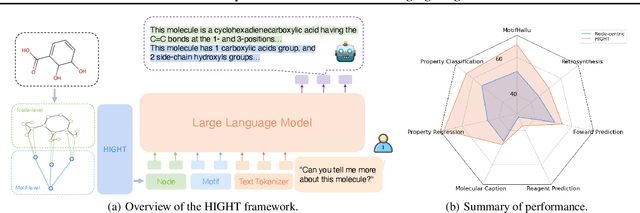

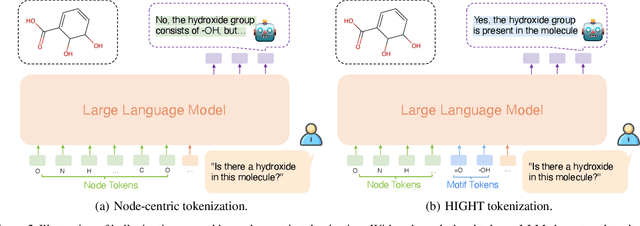
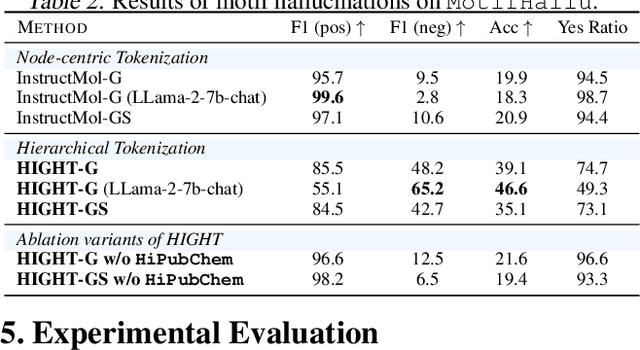
Recently there has been a surge of interest in extending the success of large language models (LLMs) to graph modality, such as social networks and molecules. As LLMs are predominantly trained with 1D text data, most existing approaches adopt a graph neural network to represent a graph as a series of node tokens and feed these tokens to LLMs for graph-language alignment. Despite achieving some successes, existing approaches have overlooked the hierarchical structures that are inherent in graph data. Especially, in molecular graphs, the high-order structural information contains rich semantics of molecular functional groups, which encode crucial biochemical functionalities of the molecules. We establish a simple benchmark showing that neglecting the hierarchical information in graph tokenization will lead to subpar graph-language alignment and severe hallucination in generated outputs. To address this problem, we propose a novel strategy called HIerarchical GrapH Tokenization (HIGHT). HIGHT employs a hierarchical graph tokenizer that extracts and encodes the hierarchy of node, motif, and graph levels of informative tokens to improve the graph perception of LLMs. HIGHT also adopts an augmented graph-language supervised fine-tuning dataset, enriched with the hierarchical graph information, to further enhance the graph-language alignment. Extensive experiments on 7 molecule-centric benchmarks confirm the effectiveness of HIGHT in reducing hallucination by 40%, as well as significant improvements in various molecule-language downstream tasks.