 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Fragility of AI-Based Channel Decoders under Small Channel Perturbations
Feb 02, 2026Recent advances in deep learning have led to AI-based error correction decoders that report empirical performance improvements over traditional belief-propagation (BP) decoding on AWGN channels. While such gains are promising, a fundamental question remains: where do these improvements come from, and what cost is paid to achieve them? In this work, we study this question through the lens of robustness to distributional shifts at the channel output. We evaluate both input-dependent adversarial perturbations (FGM and projected gradient methods under $\ell_2$ constraints) and universal adversarial perturbations that apply a single norm-bounded shift to all received vectors. Our results show that recent AI decoders, including ECCT and CrossMPT, could suffer significant performance degradation under such perturbations, despite superior nominal performance under i.i.d. AWGN. Moreover, adversarial perturbations transfer relatively strongly between AI decoders but weakly to BP-based decoders, and universal perturbations are substantially more harmful than random perturbations of equal norm. These numerical findings suggest a potential robustness cost and higher sensitivity to channel distribution underlying recent AI decoding gains.
MESH -- Understanding Videos Like Human: Measuring Hallucinations in Large Video Models
Sep 10, 2025Large Video Models (LVMs) build on the semantic capabilities of Large Language Models (LLMs) and vision modules by integrating temporal information to better understand dynamic video content. Despite their progress, LVMs are prone to hallucinations-producing inaccurate or irrelevant descriptions. Current benchmarks for video hallucination depend heavily on manual categorization of video content, neglecting the perception-based processes through which humans naturally interpret videos. We introduce MESH, a benchmark designed to evaluate hallucinations in LVMs systematically. MESH uses a Question-Answering framework with binary and multi-choice formats incorporating target and trap instances. It follows a bottom-up approach, evaluating basic objects, coarse-to-fine subject features, and subject-action pairs, aligning with human video understanding. We demonstrate that MESH offers an effective and comprehensive approach for identifying hallucinations in videos. Our evaluations show that while LVMs excel at recognizing basic objects and features, their susceptibility to hallucinations increases markedly when handling fine details or aligning multiple actions involving various subjects in longer videos.
SPARKE: Scalable Prompt-Aware Diversity Guidance in Diffusion Models via RKE Score
Jun 11, 2025Diffusion models have demonstrated remarkable success in high-fidelity image synthesis and prompt-guided generative modeling. However, ensuring adequate diversity in generated samples of prompt-guided diffusion models remains a challenge, particularly when the prompts span a broad semantic spectrum and the diversity of generated data needs to be evaluated in a prompt-aware fashion across semantically similar prompts. Recent methods have introduced guidance via diversity measures to encourage more varied generations. In this work, we extend the diversity measure-based approaches by proposing the Scalable Prompt-Aware R\'eny Kernel Entropy Diversity Guidance (SPARKE) method for prompt-aware diversity guidance. SPARKE utilizes conditional entropy for diversity guidance, which dynamically conditions diversity measurement on similar prompts and enables prompt-aware diversity control. While the entropy-based guidance approach enhances prompt-aware diversity, its reliance on the matrix-based entropy scores poses computational challenges in large-scale generation settings. To address this, we focus on the special case of Conditional latent RKE Score Guidance, reducing entropy computation and gradient-based optimization complexity from the $O(n^3)$ of general entropy measures to $O(n)$. The reduced computational complexity allows for diversity-guided sampling over potentially thousands of generation rounds on different prompts. We numerically test the SPARKE method on several text-to-image diffusion models, demonstrating that the proposed method improves the prompt-aware diversity of the generated data without incurring significant computational costs. We release our code on the project page: https://mjalali.github.io/SPARKE
pFedFair: Towards Optimal Group Fairness-Accuracy Trade-off in Heterogeneous Federated Learning
Mar 19, 2025Federated learning (FL) algorithms commonly aim to maximize clients' accuracy by training a model on their collective data. However, in several FL applications, the model's decisions should meet a group fairness constraint to be independent of sensitive attributes such as gender or race. While such group fairness constraints can be incorporated into the objective function of the FL optimization problem, in this work, we show that such an approach would lead to suboptimal classification accuracy in an FL setting with heterogeneous client distributions. To achieve an optimal accuracy-group fairness trade-off, we propose the Personalized Federated Learning for Client-Level Group Fairness (pFedFair) framework, where clients locally impose their fairness constraints over the distributed training process. Leveraging the image embedding models, we extend the application of pFedFair to computer vision settings, where we numerically show that pFedFair achieves an optimal group fairness-accuracy trade-off in heterogeneous FL settings. We present the results of several numerical experiments on benchmark and synthetic datasets, which highlight the suboptimality of non-personalized FL algorithms and the improvements made by the pFedFair method.
On the Inductive Biases of Demographic Parity-based Fair Learning Algorithms
Feb 28, 2024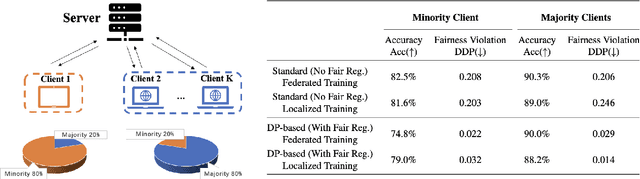
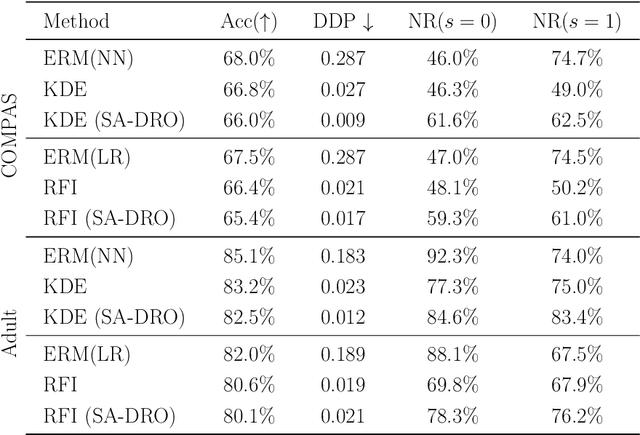

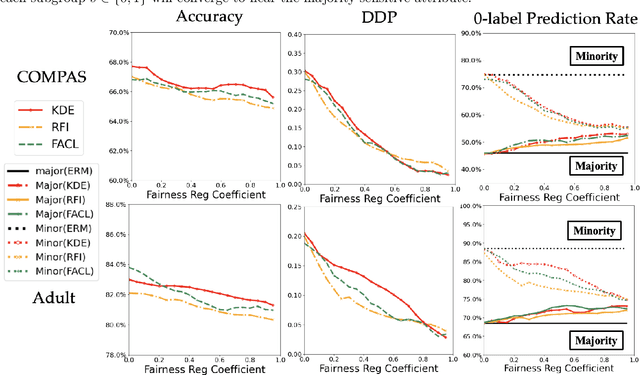
Fair supervised learning algorithms assigning labels with little dependence on a sensitive attribute have attracted great attention in the machine learning community. While the demographic parity (DP) notion has been frequently used to measure a model's fairness in training fair classifiers, several studies in the literature suggest potential impacts of enforcing DP in fair learning algorithms. In this work, we analytically study the effect of standard DP-based regularization methods on the conditional distribution of the predicted label given the sensitive attribute. Our analysis shows that an imbalanced training dataset with a non-uniform distribution of the sensitive attribute could lead to a classification rule biased toward the sensitive attribute outcome holding the majority of training data. To control such inductive biases in DP-based fair learning, we propose a sensitive attribute-based distributionally robust optimization (SA-DRO) method improving robustness against the marginal distribution of the sensitive attribute. Finally, we present several numerical results on the application of DP-based learning methods to standard centralized and distributed learning problems. The empirical findings support our theoretical results on the inductive biases in DP-based fair learning algorithms and the debiasing effects of the proposed SA-DRO method.