 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcepts from Representations: Post-hoc Concept Bottleneck Models via Sparse Decomposition of Visual Representations
Jan 18, 2026Deep learning has achieved remarkable success in image recognition, yet their inherent opacity poses challenges for deployment in critical domains. Concept-based interpretations aim to address this by explaining model reasoning through human-understandable concepts. However, existing post-hoc methods and ante-hoc concept bottleneck models (CBMs), suffer from limitations such as unreliable concept relevance, non-visual or labor-intensive concept definitions, and model or data-agnostic assumptions. This paper introduces Post-hoc Concept Bottleneck Model via Representation Decomposition (PCBM-ReD), a novel pipeline that retrofits interpretability onto pretrained opaque models. PCBM-ReD automatically extracts visual concepts from a pre-trained encoder, employs multimodal large language models (MLLMs) to label and filter concepts based on visual identifiability and task relevance, and selects an independent subset via reconstruction-guided optimization. Leveraging CLIP's visual-text alignment, it decomposes image representations into linear combination of concept embeddings to fit into the CBMs abstraction. Extensive experiments across 11 image classification tasks show PCBM-ReD achieves state-of-the-art accuracy, narrows the performance gap with end-to-end models, and exhibits better interpretability.
pFedFair: Towards Optimal Group Fairness-Accuracy Trade-off in Heterogeneous Federated Learning
Mar 19, 2025Federated learning (FL) algorithms commonly aim to maximize clients' accuracy by training a model on their collective data. However, in several FL applications, the model's decisions should meet a group fairness constraint to be independent of sensitive attributes such as gender or race. While such group fairness constraints can be incorporated into the objective function of the FL optimization problem, in this work, we show that such an approach would lead to suboptimal classification accuracy in an FL setting with heterogeneous client distributions. To achieve an optimal accuracy-group fairness trade-off, we propose the Personalized Federated Learning for Client-Level Group Fairness (pFedFair) framework, where clients locally impose their fairness constraints over the distributed training process. Leveraging the image embedding models, we extend the application of pFedFair to computer vision settings, where we numerically show that pFedFair achieves an optimal group fairness-accuracy trade-off in heterogeneous FL settings. We present the results of several numerical experiments on benchmark and synthetic datasets, which highlight the suboptimality of non-personalized FL algorithms and the improvements made by the pFedFair method.
A Super-pixel-based Approach to the Stable Interpretation of Neural Networks
Dec 19, 2024



Saliency maps are widely used in the computer vision community for interpreting neural network classifiers. However, due to the randomness of training samples and optimization algorithms, the resulting saliency maps suffer from a significant level of stochasticity, making it difficult for domain experts to capture the intrinsic factors that influence the neural network's decision. In this work, we propose a novel pixel partitioning strategy to boost the stability and generalizability of gradient-based saliency maps. Through both theoretical analysis and numerical experiments, we demonstrate that the grouping of pixels reduces the variance of the saliency map and improves the generalization behavior of the interpretation method. Furthermore, we propose a sensible grouping strategy based on super-pixels which cluster pixels into groups that align well with the semantic meaning of the images. We perform several numerical experiments on CIFAR-10 and ImageNet. Our empirical results suggest that the super-pixel-based interpretation maps consistently improve the stability and quality over the pixel-based saliency maps.
Structured Gradient-based Interpretations via Norm-Regularized Adversarial Training
Apr 06, 2024



Gradient-based saliency maps have been widely used to explain the decisions of deep neural network classifiers. However, standard gradient-based interpretation maps, including the simple gradient and integrated gradient algorithms, often lack desired structures such as sparsity and connectedness in their application to real-world computer vision models. A frequently used approach to inducing sparsity structures into gradient-based saliency maps is to alter the simple gradient scheme using sparsification or norm-based regularization. A drawback with such post-processing methods is their frequently-observed significant loss in fidelity to the original simple gradient map. In this work, we propose to apply adversarial training as an in-processing scheme to train neural networks with structured simple gradient maps. We show a duality relation between the regularized norms of the adversarial perturbations and gradient-based maps, based on which we design adversarial training loss functions promoting sparsity and group-sparsity properties in simple gradient maps. We present several numerical results to show the influence of our proposed norm-based adversarial training methods on the standard gradient-based maps of standard neural network architectures on benchmark image datasets.
3DSAM-adapter: Holistic Adaptation of SAM from 2D to 3D for Promptable Medical Image Segmentation
Jun 23, 2023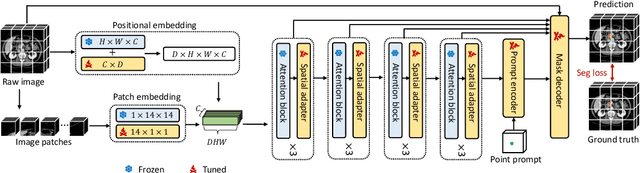
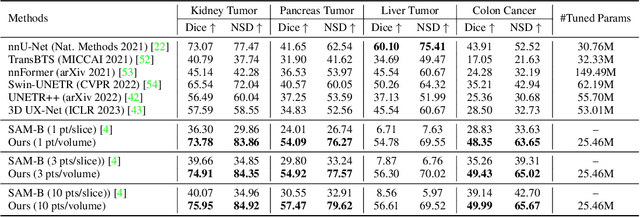
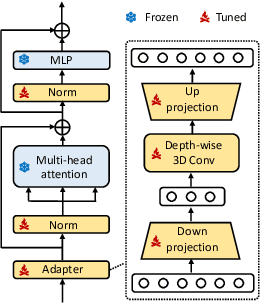
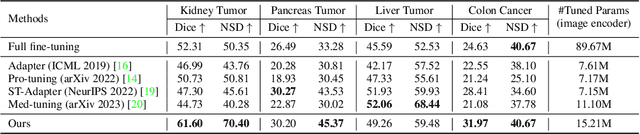
Despite that the segment anything model (SAM) achieved impressive results on general-purpose semantic segmentation with strong generalization ability on daily images, its demonstrated performance on medical image segmentation is less precise and not stable, especially when dealing with tumor segmentation tasks that involve objects of small sizes, irregular shapes, and low contrast. Notably, the original SAM architecture is designed for 2D natural images, therefore would not be able to extract the 3D spatial information from volumetric medical data effectively. In this paper, we propose a novel adaptation method for transferring SAM from 2D to 3D for promptable medical image segmentation. Through a holistically designed scheme for architecture modification, we transfer the SAM to support volumetric inputs while retaining the majority of its pre-trained parameters for reuse. The fine-tuning process is conducted in a parameter-efficient manner, wherein most of the pre-trained parameters remain frozen, and only a few lightweight spatial adapters are introduced and tuned. Regardless of the domain gap between natural and medical data and the disparity in the spatial arrangement between 2D and 3D, the transformer trained on natural images can effectively capture the spatial patterns present in volumetric medical images with only lightweight adaptations. We conduct experiments on four open-source tumor segmentation datasets, and with a single click prompt, our model can outperform domain state-of-the-art medical image segmentation models on 3 out of 4 tasks, specifically by 8.25%, 29.87%, and 10.11% for kidney tumor, pancreas tumor, colon cancer segmentation, and achieve similar performance for liver tumor segmentation. We also compare our adaptation method with existing popular adapters, and observed significant performance improvement on most datasets.
Diffusion Model based Semi-supervised Learning on Brain Hemorrhage Images for Efficient Midline Shift Quantification
Jan 01, 2023



Brain midline shift (MLS) is one of the most critical factors to be considered for clinical diagnosis and treatment decision-making for intracranial hemorrhage. Existing computational methods on MLS quantification not only require intensive labeling in millimeter-level measurement but also suffer from poor performance due to their dependence on specific landmarks or simplified anatomical assumptions. In this paper, we propose a novel semi-supervised framework to accurately measure the scale of MLS from head CT scans. We formulate the MLS measurement task as a deformation estimation problem and solve it using a few MLS slices with sparse labels. Meanwhile, with the help of diffusion models, we are able to use a great number of unlabeled MLS data and 2793 non-MLS cases for representation learning and regularization. The extracted representation reflects how the image is different from a non-MLS image and regularization serves an important role in the sparse-to-dense refinement of the deformation field. Our experiment on a real clinical brain hemorrhage dataset has achieved state-of-the-art performance and can generate interpretable deformation fields.