 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Rollout Allocation for Online Reinforcement Learning with Verifiable Rewards
Feb 03, 2026Sampling efficiency is a key bottleneck in reinforcement learning with verifiable rewards. Existing group-based policy optimization methods, such as GRPO, allocate a fixed number of rollouts for all training prompts. This uniform allocation implicitly treats all prompts as equally informative, and could lead to inefficient computational budget usage and impede training progress. We introduce VIP, a Variance-Informed Predictive allocation strategy that allocates a given rollout budget to the prompts in the incumbent batch to minimize the expected gradient variance of the policy update. At each iteration, VIP uses a lightweight Gaussian process model to predict per-prompt success probabilities based on recent rollouts. These probability predictions are translated into variance estimates, which are then fed into a convex optimization problem to determine the optimal rollout allocations under a hard compute budget constraint. Empirical results show that VIP consistently improves sampling efficiency and achieves higher performance than uniform or heuristic allocation strategies in multiple benchmarks.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
From Exploration to Exploitation: A Two-Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training
Nov 11, 2025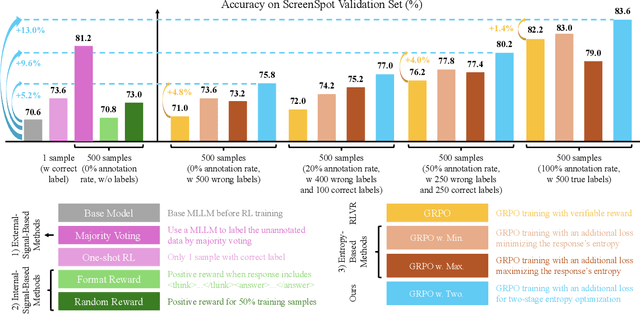



Reinforcement Learning with Verifiable Rewards (RLVR) for Multimodal Large Language Models (MLLMs) is highly dependent on high-quality labeled data, which is often scarce and prone to substantial annotation noise in real-world scenarios. Existing unsupervised RLVR methods, including pure entropy minimization, can overfit to incorrect labels and limit the crucial reward ranking signal for Group-Relative Policy Optimization (GRPO). To address these challenges and enhance noise tolerance, we propose a novel two-stage, token-level entropy optimization method for RLVR. This approach dynamically guides the model from exploration to exploitation during training. In the initial exploration phase, token-level entropy maximization promotes diverse and stochastic output generation, serving as a strong regularizer that prevents premature convergence to noisy labels and ensures sufficient intra-group variation, which enables more reliable reward gradient estimation in GRPO. As training progresses, the method transitions into the exploitation phase, where token-level entropy minimization encourages the model to produce confident and deterministic outputs, thereby consolidating acquired knowledge and refining prediction accuracy. Empirically, across three MLLM backbones - Qwen2-VL-2B, Qwen2-VL-7B, and Qwen2.5-VL-3B - spanning diverse noise settings and multiple tasks, our phased strategy consistently outperforms prior approaches by unifying and enhancing external, internal, and entropy-based methods, delivering robust and superior performance across the board.
Treatment Outcome Prediction for Intracerebral Hemorrhage via Generative Prognostic Model with Imaging and Tabular Data
Jul 24, 2023


Intracerebral hemorrhage (ICH) is the second most common and deadliest form of stroke. Despite medical advances, predicting treat ment outcomes for ICH remains a challenge. This paper proposes a novel prognostic model that utilizes both imaging and tabular data to predict treatment outcome for ICH. Our model is trained on observational data collected from non-randomized controlled trials, providing reliable predictions of treatment success. Specifically, we propose to employ a variational autoencoder model to generate a low-dimensional prognostic score, which can effectively address the selection bias resulting from the non-randomized controlled trials. Importantly, we develop a variational distributions combination module that combines the information from imaging data, non-imaging clinical data, and treatment assignment to accurately generate the prognostic score. We conducted extensive experiments on a real-world clinical dataset of intracerebral hemorrhage. Our proposed method demonstrates a substantial improvement in treatment outcome prediction compared to existing state-of-the-art approaches. Code is available at https://github.com/med-air/TOP-GPM
3DSAM-adapter: Holistic Adaptation of SAM from 2D to 3D for Promptable Medical Image Segmentation
Jun 23, 2023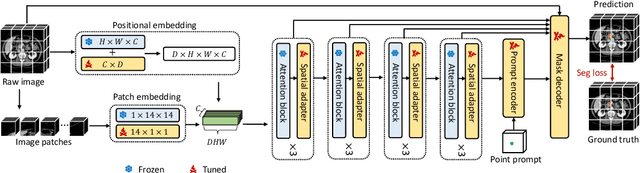
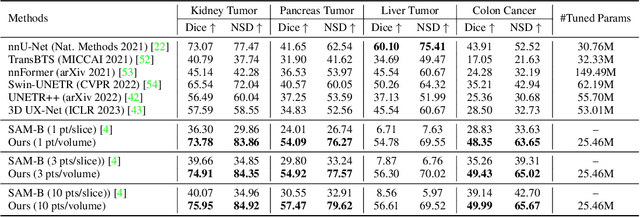
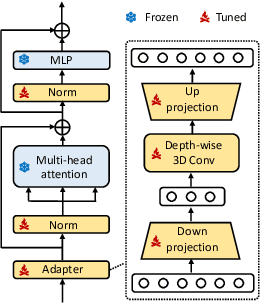
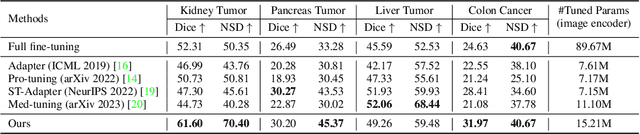
Despite that the segment anything model (SAM) achieved impressive results on general-purpose semantic segmentation with strong generalization ability on daily images, its demonstrated performance on medical image segmentation is less precise and not stable, especially when dealing with tumor segmentation tasks that involve objects of small sizes, irregular shapes, and low contrast. Notably, the original SAM architecture is designed for 2D natural images, therefore would not be able to extract the 3D spatial information from volumetric medical data effectively. In this paper, we propose a novel adaptation method for transferring SAM from 2D to 3D for promptable medical image segmentation. Through a holistically designed scheme for architecture modification, we transfer the SAM to support volumetric inputs while retaining the majority of its pre-trained parameters for reuse. The fine-tuning process is conducted in a parameter-efficient manner, wherein most of the pre-trained parameters remain frozen, and only a few lightweight spatial adapters are introduced and tuned. Regardless of the domain gap between natural and medical data and the disparity in the spatial arrangement between 2D and 3D, the transformer trained on natural images can effectively capture the spatial patterns present in volumetric medical images with only lightweight adaptations. We conduct experiments on four open-source tumor segmentation datasets, and with a single click prompt, our model can outperform domain state-of-the-art medical image segmentation models on 3 out of 4 tasks, specifically by 8.25%, 29.87%, and 10.11% for kidney tumor, pancreas tumor, colon cancer segmentation, and achieve similar performance for liver tumor segmentation. We also compare our adaptation method with existing popular adapters, and observed significant performance improvement on most datasets.
Diffusion Model based Semi-supervised Learning on Brain Hemorrhage Images for Efficient Midline Shift Quantification
Jan 01, 2023



Brain midline shift (MLS) is one of the most critical factors to be considered for clinical diagnosis and treatment decision-making for intracranial hemorrhage. Existing computational methods on MLS quantification not only require intensive labeling in millimeter-level measurement but also suffer from poor performance due to their dependence on specific landmarks or simplified anatomical assumptions. In this paper, we propose a novel semi-supervised framework to accurately measure the scale of MLS from head CT scans. We formulate the MLS measurement task as a deformation estimation problem and solve it using a few MLS slices with sparse labels. Meanwhile, with the help of diffusion models, we are able to use a great number of unlabeled MLS data and 2793 non-MLS cases for representation learning and regularization. The extracted representation reflects how the image is different from a non-MLS image and regularization serves an important role in the sparse-to-dense refinement of the deformation field. Our experiment on a real clinical brain hemorrhage dataset has achieved state-of-the-art performance and can generate interpretable deformation fields.
Test-time Adaptation with Calibration of Medical Image Classification Nets for Label Distribution Shift
Jul 09, 2022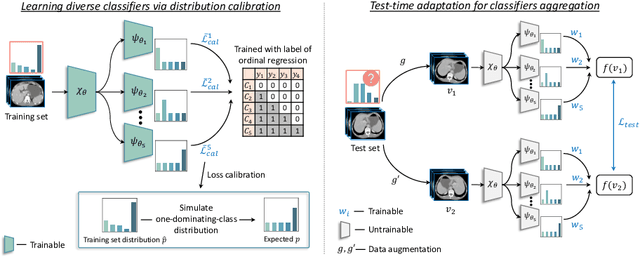
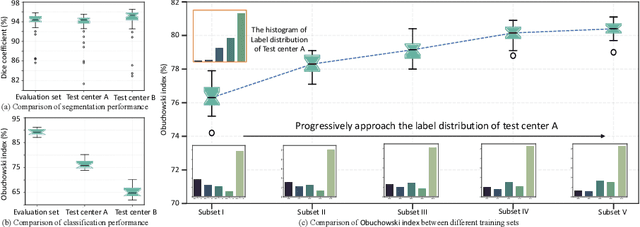
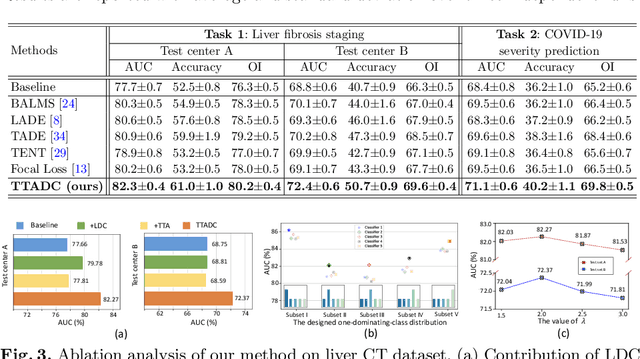
Class distribution plays an important role in learning deep classifiers. When the proportion of each class in the test set differs from the training set, the performance of classification nets usually degrades. Such a label distribution shift problem is common in medical diagnosis since the prevalence of disease vary over location and time. In this paper, we propose the first method to tackle label shift for medical image classification, which effectively adapt the model learned from a single training label distribution to arbitrary unknown test label distribution. Our approach innovates distribution calibration to learn multiple representative classifiers, which are capable of handling different one-dominating-class distributions. When given a test image, the diverse classifiers are dynamically aggregated via the consistency-driven test-time adaptation, to deal with the unknown test label distribution. We validate our method on two important medical image classification tasks including liver fibrosis staging and COVID-19 severity prediction. Our experiments clearly show the decreased model performance under label shift. With our method, model performance significantly improves on all the test datasets with different label shifts for both medical image diagnosis tasks.
Rapid model transfer for medical image segmentation via iterative human-in-the-loop update: from labelled public to unlabelled clinical datasets for multi-organ segmentation in CT
Apr 13, 2022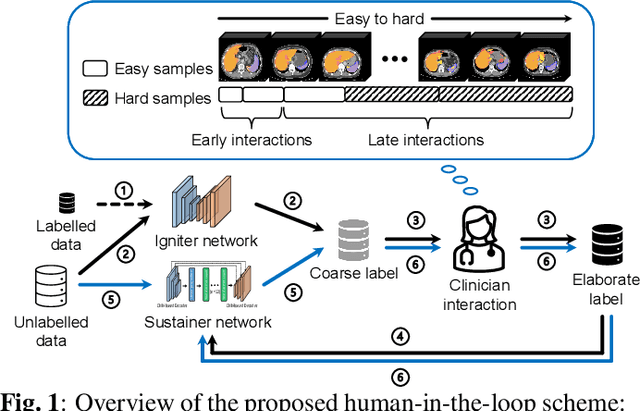


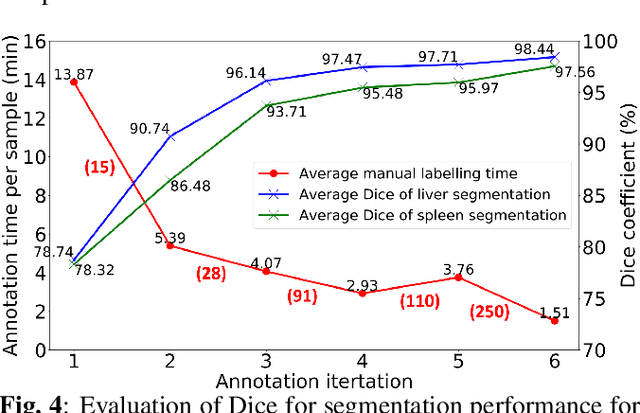
Despite the remarkable success on medical image analysis with deep learning, it is still under exploration regarding how to rapidly transfer AI models from one dataset to another for clinical applications. This paper presents a novel and generic human-in-the-loop scheme for efficiently transferring a segmentation model from a small-scale labelled dataset to a larger-scale unlabelled dataset for multi-organ segmentation in CT. To achieve this, we propose to use an igniter network which can learn from a small-scale labelled dataset and generate coarse annotations to start the process of human-machine interaction. Then, we use a sustainer network for our larger-scale dataset, and iteratively updated it on the new annotated data. Moreover, we propose a flexible labelling strategy for the annotator to reduce the initial annotation workload. The model performance and the time cost of annotation in each subject evaluated on our private dataset are reported and analysed. The results show that our scheme can not only improve the performance by 19.7% on Dice, but also expedite the cost time of manual labelling from 13.87 min to 1.51 min per CT volume during the model transfer, demonstrating the clinical usefulness with promising potentials.
Hierarchical Deep Network with Uncertainty-aware Semi-supervised Learning for Vessel Segmentation
May 31, 2021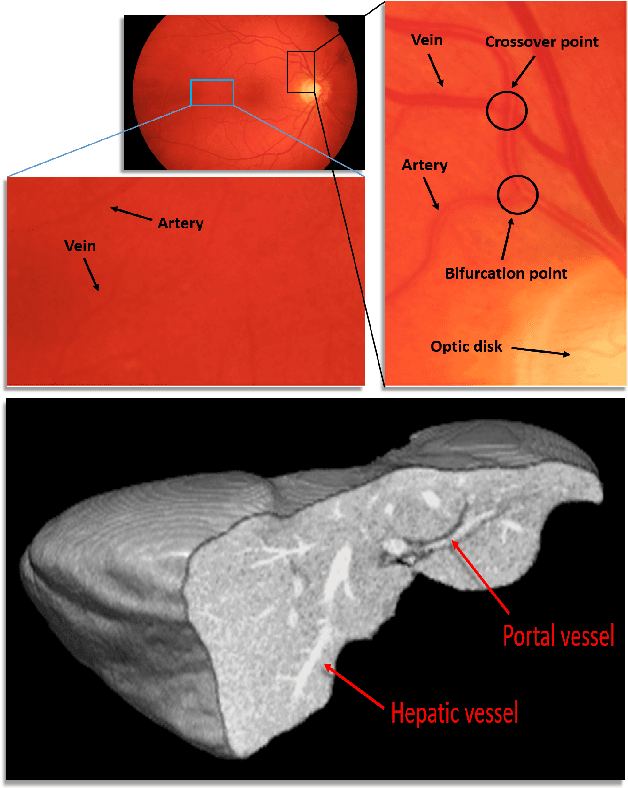
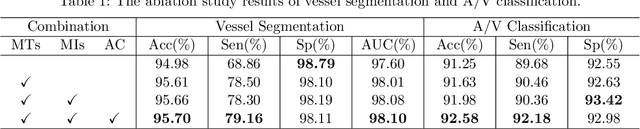
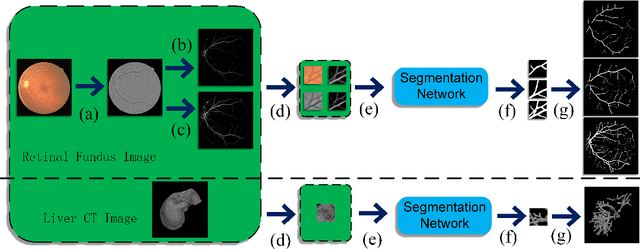
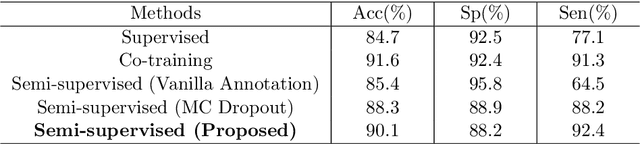
The analysis of organ vessels is essential for computer-aided diagnosis and surgical planning. But it is not a easy task since the fine-detailed connected regions of organ vessel bring a lot of ambiguity in vessel segmentation and sub-type recognition, especially for the low-contrast capillary regions. Furthermore, recent two-staged approaches would accumulate and even amplify these inaccuracies from the first-stage whole vessel segmentation into the second-stage sub-type vessel pixel-wise classification. Moreover, the scarcity of manual annotation in organ vessels poses another challenge. In this paper, to address the above issues, we propose a hierarchical deep network where an attention mechanism localizes the low-contrast capillary regions guided by the whole vessels, and enhance the spatial activation in those areas for the sub-type vessels. In addition, we propose an uncertainty-aware semi-supervised training framework to alleviate the annotation-hungry limitation of deep models. The proposed method achieves the state-of-the-art performance in the benchmarks of both retinal artery/vein segmentation in fundus images and liver portal/hepatic vessel segmentation in CT images.
Consistent Posterior Distributions under Vessel-Mixing: A Regularization for Cross-Domain Retinal Artery/Vein Classification
Mar 16, 2021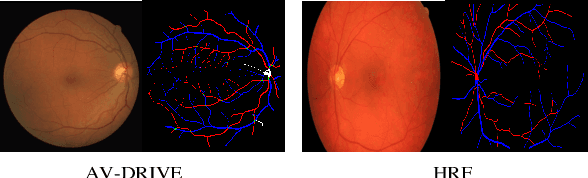

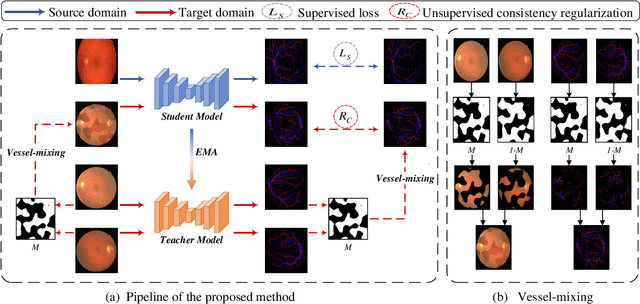

Retinal artery/vein (A/V) classification is a critical technique for diagnosing diabetes and cardiovascular diseases. Although deep learning based methods achieve impressive results in A/V classification, their performances usually degrade severely when being directly applied to another database, due to the domain shift, e.g., caused by the variations in imaging protocols. In this paper, we propose a novel vessel-mixing based consistency regularization framework, for cross-domain learning in retinal A/V classification. Specially, to alleviate the severe bias to source domain, based on the label smooth prior, the model is regularized to give consistent predictions for unlabeled target-domain inputs that are under perturbation. This consistency regularization implicitly introduces a mechanism where the model and the perturbation is opponent to each other, where the model is pushed to be robust enough to cope with the perturbation. Thus, we investigate a more difficult opponent to further inspire the robustness of model, in the scenario of retinal A/V, called vessel-mixing perturbation. Specially, it effectively disturbs the fundus images especially the vessel structures by mixing two images regionally. We conduct extensive experiments on cross-domain A/V classification using four public datasets, which are collected by diverse institutions and imaging devices. The results demonstrate that our method achieves the state-of-the-art cross-domain performance, which is also close to the upper bound obtained by fully supervised learning on target domain.