 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAD-R1: Eliciting Consistent Reasoning in Interpretible Medical Anomaly Detection via Consistency-Reinforced Policy Optimization
Feb 01, 2026Medical Anomaly Detection (MedAD) presents a significant opportunity to enhance diagnostic accuracy using Large Multimodal Models (LMMs) to interpret and answer questions based on medical images. However, the reliance on Supervised Fine-Tuning (SFT) on simplistic and fragmented datasets has hindered the development of models capable of plausible reasoning and robust multimodal generalization. To overcome this, we introduce MedAD-38K, the first large-scale, multi-modal, and multi-center benchmark for MedAD featuring diagnostic Chain-of-Thought (CoT) annotations alongside structured Visual Question-Answering (VQA) pairs. On this foundation, we propose a two-stage training framework. The first stage, Cognitive Injection, uses SFT to instill foundational medical knowledge and align the model with a structured think-then-answer paradigm. Given that standard policy optimization can produce reasoning that is disconnected from the final answer, the second stage incorporates Consistency Group Relative Policy Optimization (Con-GRPO). This novel algorithm incorporates a crucial consistency reward to ensure the generated reasoning process is relevant and logically coherent with the final diagnosis. Our proposed model, MedAD-R1, achieves state-of-the-art (SOTA) performance on the MedAD-38K benchmark, outperforming strong baselines by more than 10\%. This superior performance stems from its ability to generate transparent and logically consistent reasoning pathways, offering a promising approach to enhancing the trustworthiness and interpretability of AI for clinical decision support.
Self-supervised Multiplex Consensus Mamba for General Image Fusion
Dec 24, 2025Image fusion integrates complementary information from different modalities to generate high-quality fused images, thereby enhancing downstream tasks such as object detection and semantic segmentation. Unlike task-specific techniques that primarily focus on consolidating inter-modal information, general image fusion needs to address a wide range of tasks while improving performance without increasing complexity. To achieve this, we propose SMC-Mamba, a Self-supervised Multiplex Consensus Mamba framework for general image fusion. Specifically, the Modality-Agnostic Feature Enhancement (MAFE) module preserves fine details through adaptive gating and enhances global representations via spatial-channel and frequency-rotational scanning. The Multiplex Consensus Cross-modal Mamba (MCCM) module enables dynamic collaboration among experts, reaching a consensus to efficiently integrate complementary information from multiple modalities. The cross-modal scanning within MCCM further strengthens feature interactions across modalities, facilitating seamless integration of critical information from both sources. Additionally, we introduce a Bi-level Self-supervised Contrastive Learning Loss (BSCL), which preserves high-frequency information without increasing computational overhead while simultaneously boosting performance in downstream tasks. Extensive experiments demonstrate that our approach outperforms state-of-the-art (SOTA) image fusion algorithms in tasks such as infrared-visible, medical, multi-focus, and multi-exposure fusion, as well as downstream visual tasks.
MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement
Dec 17, 2025Pan-sharpening aims to generate high-resolution multispectral (HRMS) images by integrating a high-resolution panchromatic (PAN) image with its corresponding low-resolution multispectral (MS) image. To achieve effective fusion, it is crucial to fully exploit the complementary information between the two modalities. Traditional CNN-based methods typically rely on channel-wise concatenation with fixed convolutional operators, which limits their adaptability to diverse spatial and spectral variations. While cross-attention mechanisms enable global interactions, they are computationally inefficient and may dilute fine-grained correspondences, making it difficult to capture complex semantic relationships. Recent advances in the Multimodal Diffusion Transformer (MMDiT) architecture have demonstrated impressive success in image generation and editing tasks. Unlike cross-attention, MMDiT employs in-context conditioning to facilitate more direct and efficient cross-modal information exchange. In this paper, we propose MMMamba, a cross-modal in-context fusion framework for pan-sharpening, with the flexibility to support image super-resolution in a zero-shot manner. Built upon the Mamba architecture, our design ensures linear computational complexity while maintaining strong cross-modal interaction capacity. Furthermore, we introduce a novel multimodal interleaved (MI) scanning mechanism that facilitates effective information exchange between the PAN and MS modalities. Extensive experiments demonstrate the superior performance of our method compared to existing state-of-the-art (SOTA) techniques across multiple tasks and benchmarks.
Track Any Anomalous Object: A Granular Video Anomaly Detection Pipeline
Jun 05, 2025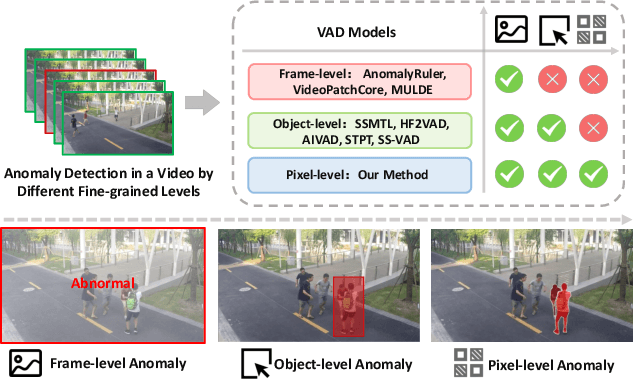
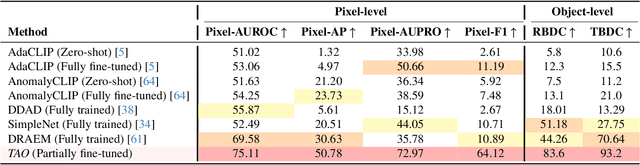
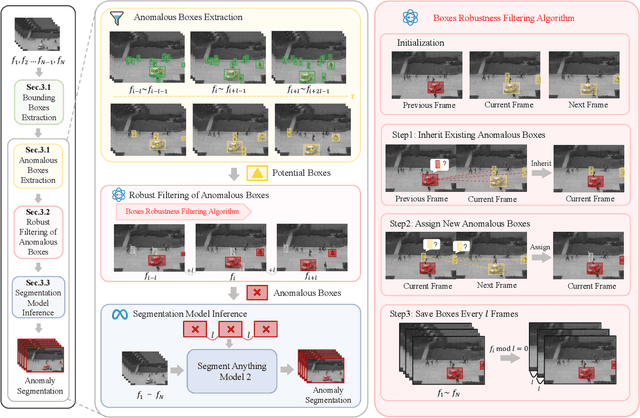

Video anomaly detection (VAD) is crucial in scenarios such as surveillance and autonomous driving, where timely detection of unexpected activities is essential. Although existing methods have primarily focused on detecting anomalous objects in videos -- either by identifying anomalous frames or objects -- they often neglect finer-grained analysis, such as anomalous pixels, which limits their ability to capture a broader range of anomalies. To address this challenge, we propose a new framework called Track Any Anomalous Object (TAO), which introduces a granular video anomaly detection pipeline that, for the first time, integrates the detection of multiple fine-grained anomalous objects into a unified framework. Unlike methods that assign anomaly scores to every pixel, our approach transforms the problem into pixel-level tracking of anomalous objects. By linking anomaly scores to downstream tasks such as segmentation and tracking, our method removes the need for threshold tuning and achieves more precise anomaly localization in long and complex video sequences. Experiments demonstrate that TAO sets new benchmarks in accuracy and robustness. Project page available online.
PCMamba: Physics-Informed Cross-Modal State Space Model for Dual-Camera Compressive Hyperspectral Imaging
May 22, 2025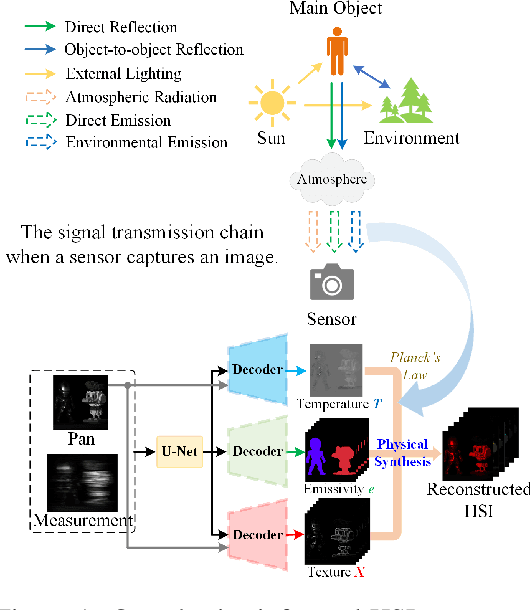
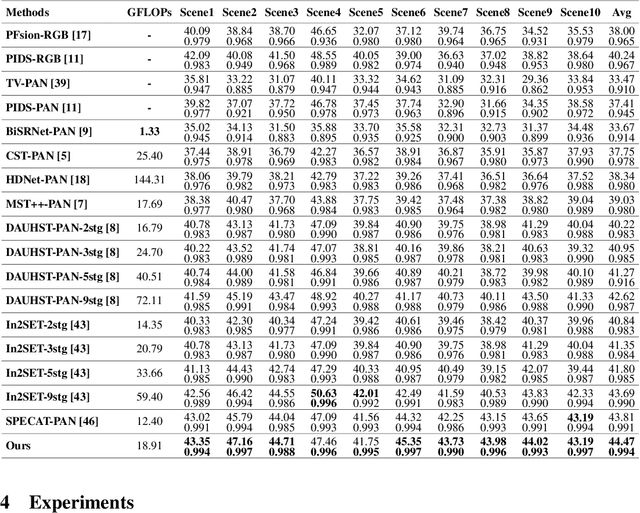
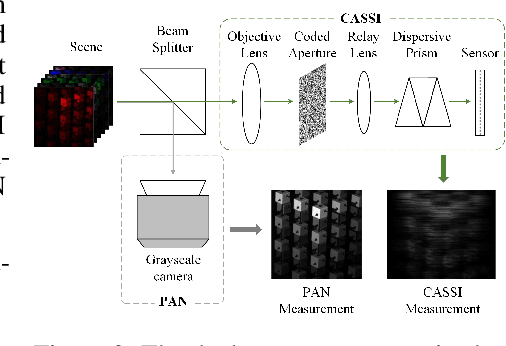
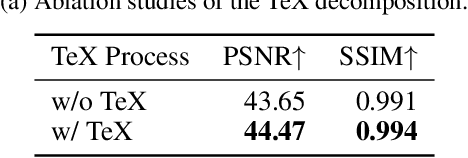
Panchromatic (PAN) -assisted Dual-Camera Compressive Hyperspectral Imaging (DCCHI) is a key technology in snapshot hyperspectral imaging. Existing research primarily focuses on exploring spectral information from 2D compressive measurements and spatial information from PAN images in an explicit manner, leading to a bottleneck in HSI reconstruction. Various physical factors, such as temperature, emissivity, and multiple reflections between objects, play a critical role in the process of a sensor acquiring hyperspectral thermal signals. Inspired by this, we attempt to investigate the interrelationships between physical properties to provide deeper theoretical insights for HSI reconstruction. In this paper, we propose a Physics-Informed Cross-Modal State Space Model Network (PCMamba) for DCCHI, which incorporates the forward physical imaging process of HSI into the linear complexity of Mamba to facilitate lightweight and high-quality HSI reconstruction. Specifically, we analyze the imaging process of hyperspectral thermal signals to enable the network to disentangle the three key physical properties-temperature, emissivity, and texture. By fully exploiting the potential information embedded in 2D measurements and PAN images, the HSIs are reconstructed through a physics-driven synthesis process. Furthermore, we design a Cross-Modal Scanning Mamba Block (CSMB) that introduces inter-modal pixel-wise interaction with positional inductive bias by cross-scanning the backbone features and PAN features. Extensive experiments conducted on both real and simulated datasets demonstrate that our method significantly outperforms SOTA methods in both quantitative and qualitative metrics.
FRN: Fractal-Based Recursive Spectral Reconstruction Network
May 21, 2025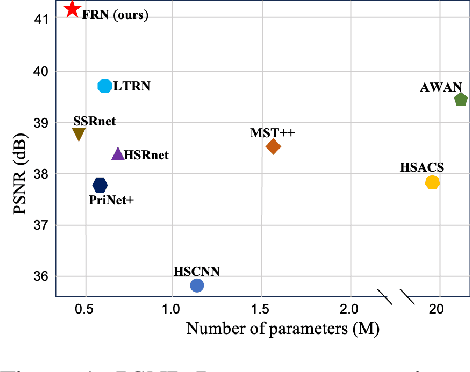
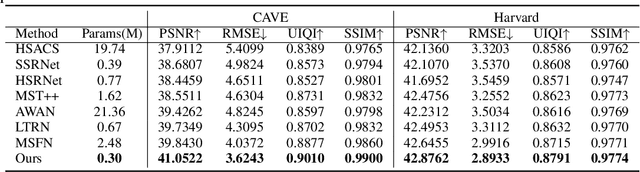
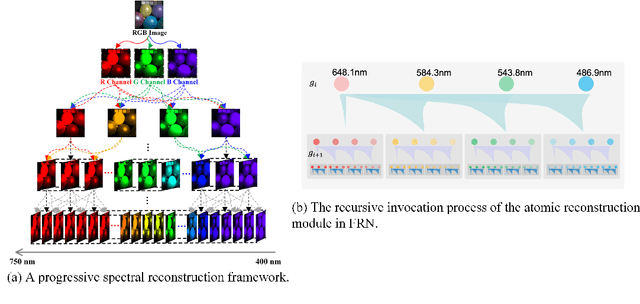

Generating hyperspectral images (HSIs) from RGB images through spectral reconstruction can significantly reduce the cost of HSI acquisition. In this paper, we propose a Fractal-Based Recursive Spectral Reconstruction Network (FRN), which differs from existing paradigms that attempt to directly integrate the full-spectrum information from the R, G, and B channels in a one-shot manner. Instead, it treats spectral reconstruction as a progressive process, predicting from broad to narrow bands or employing a coarse-to-fine approach for predicting the next wavelength. Inspired by fractals in mathematics, FRN establishes a novel spectral reconstruction paradigm by recursively invoking an atomic reconstruction module. In each invocation, only the spectral information from neighboring bands is used to provide clues for the generation of the image at the next wavelength, which follows the low-rank property of spectral data. Moreover, we design a band-aware state space model that employs a pixel-differentiated scanning strategy at different stages of the generation process, further suppressing interference from low-correlation regions caused by reflectance differences. Through extensive experimentation across different datasets, FRN achieves superior reconstruction performance compared to state-of-the-art methods in both quantitative and qualitative evaluations.
JarvisIR: Elevating Autonomous Driving Perception with Intelligent Image Restoration
Apr 05, 2025



Vision-centric perception systems struggle with unpredictable and coupled weather degradations in the wild. Current solutions are often limited, as they either depend on specific degradation priors or suffer from significant domain gaps. To enable robust and autonomous operation in real-world conditions, we propose JarvisIR, a VLM-powered agent that leverages the VLM as a controller to manage multiple expert restoration models. To further enhance system robustness, reduce hallucinations, and improve generalizability in real-world adverse weather, JarvisIR employs a novel two-stage framework consisting of supervised fine-tuning and human feedback alignment. Specifically, to address the lack of paired data in real-world scenarios, the human feedback alignment enables the VLM to be fine-tuned effectively on large-scale real-world data in an unsupervised manner. To support the training and evaluation of JarvisIR, we introduce CleanBench, a comprehensive dataset consisting of high-quality and large-scale instruction-responses pairs, including 150K synthetic entries and 80K real entries. Extensive experiments demonstrate that JarvisIR exhibits superior decision-making and restoration capabilities. Compared with existing methods, it achieves a 50% improvement in the average of all perception metrics on CleanBench-Real. Project page: https://cvpr2025-jarvisir.github.io/.
Pan-LUT: Efficient Pan-sharpening via Learnable Look-Up Tables
Mar 31, 2025
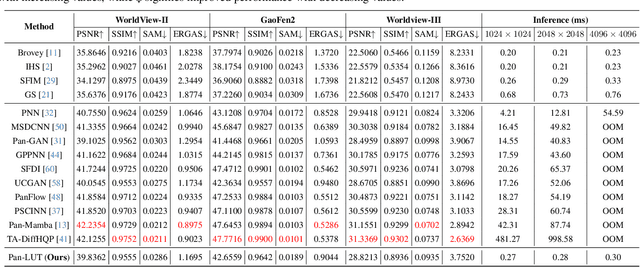
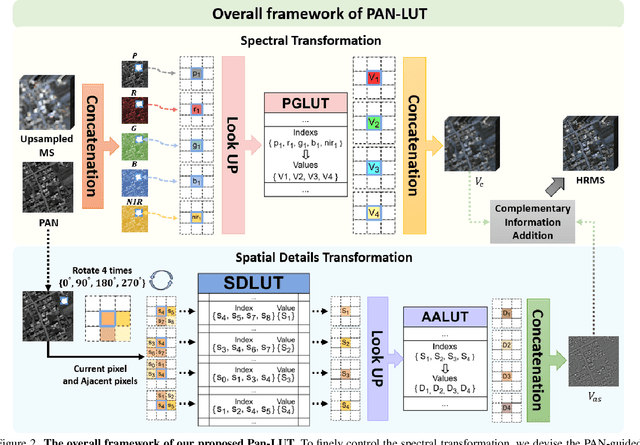

Recently, deep learning-based pan-sharpening algorithms have achieved notable advancements over traditional methods. However, many deep learning-based approaches incur substantial computational overhead during inference, especially with high-resolution images. This excessive computational demand limits the applicability of these methods in real-world scenarios, particularly in the absence of dedicated computing devices such as GPUs and TPUs. To address these challenges, we propose Pan-LUT, a novel learnable look-up table (LUT) framework for pan-sharpening that strikes a balance between performance and computational efficiency for high-resolution remote sensing images. To finely control the spectral transformation, we devise the PAN-guided look-up table (PGLUT) for channel-wise spectral mapping. To effectively capture fine-grained spatial details and adaptively learn local contexts, we introduce the spatial details look-up table (SDLUT) and adaptive aggregation look-up table (AALUT). Our proposed method contains fewer than 300K parameters and processes a 8K resolution image in under 1 ms using a single NVIDIA GeForce RTX 2080 Ti GPU, demonstrating significantly faster performance compared to other methods. Experiments reveal that Pan-LUT efficiently processes large remote sensing images in a lightweight manner, bridging the gap to real-world applications. Furthermore, our model surpasses SOTA methods in full-resolution scenes under real-world conditions, highlighting its effectiveness and efficiency.
Efficient Dataset Distillation through Low-Rank Space Sampling
Mar 11, 2025Huge amount of data is the key of the success of deep learning, however, redundant information impairs the generalization ability of the model and increases the burden of calculation. Dataset Distillation (DD) compresses the original dataset into a smaller but representative subset for high-quality data and efficient training strategies. Existing works for DD generate synthetic images by treating each image as an independent entity, thereby overlooking the common features among data. This paper proposes a dataset distillation method based on Matching Training Trajectories with Low-rank Space Sampling(MTT-LSS), which uses low-rank approximations to capture multiple low-dimensional manifold subspaces of the original data. The synthetic data is represented by basis vectors and shared dimension mappers from these subspaces, reducing the cost of generating individual data points while effectively minimizing information redundancy. The proposed method is tested on CIFAR-10, CIFAR-100, and SVHN datasets, and outperforms the baseline methods by an average of 9.9%.
Bridging Synthetic-to-Real Gaps: Frequency-Aware Perturbation and Selection for Single-shot Multi-Parametric Mapping Reconstruction
Mar 05, 2025Data-centric artificial intelligence (AI) has remarkably advanced medical imaging, with emerging methods using synthetic data to address data scarcity while introducing synthetic-to-real gaps. Unsupervised domain adaptation (UDA) shows promise in ground truth-scarce tasks, but its application in reconstruction remains underexplored. Although multiple overlapping-echo detachment (MOLED) achieves ultra-fast multi-parametric reconstruction, extending its application to various clinical scenarios, the quality suffers from deficiency in mitigating the domain gap, difficulty in maintaining structural integrity, and inadequacy in ensuring mapping accuracy. To resolve these issues, we proposed frequency-aware perturbation and selection (FPS), comprising Wasserstein distance-modulated frequency-aware perturbation (WDFP) and hierarchical frequency-aware selection network (HFSNet), which integrates frequency-aware adaptive selection (FAS), compact FAS (cFAS) and feature-aware architecture integration (FAI). Specifically, perturbation activates domain-invariant feature learning within uncertainty, while selection refines optimal solutions within perturbation, establishing a robust and closed-loop learning pathway. Extensive experiments on synthetic data, along with diverse real clinical cases from 5 healthy volunteers, 94 ischemic stroke patients, and 46 meningioma patients, demonstrate the superiority and clinical applicability of FPS. Furthermore, FPS is applied to diffusion tensor imaging (DTI), underscoring its versatility and potential for broader medical applications. The code is available at https://github.com/flyannie/FPS.