 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Synthetic-to-Real Gaps: Frequency-Aware Perturbation and Selection for Single-shot Multi-Parametric Mapping Reconstruction
Mar 05, 2025Data-centric artificial intelligence (AI) has remarkably advanced medical imaging, with emerging methods using synthetic data to address data scarcity while introducing synthetic-to-real gaps. Unsupervised domain adaptation (UDA) shows promise in ground truth-scarce tasks, but its application in reconstruction remains underexplored. Although multiple overlapping-echo detachment (MOLED) achieves ultra-fast multi-parametric reconstruction, extending its application to various clinical scenarios, the quality suffers from deficiency in mitigating the domain gap, difficulty in maintaining structural integrity, and inadequacy in ensuring mapping accuracy. To resolve these issues, we proposed frequency-aware perturbation and selection (FPS), comprising Wasserstein distance-modulated frequency-aware perturbation (WDFP) and hierarchical frequency-aware selection network (HFSNet), which integrates frequency-aware adaptive selection (FAS), compact FAS (cFAS) and feature-aware architecture integration (FAI). Specifically, perturbation activates domain-invariant feature learning within uncertainty, while selection refines optimal solutions within perturbation, establishing a robust and closed-loop learning pathway. Extensive experiments on synthetic data, along with diverse real clinical cases from 5 healthy volunteers, 94 ischemic stroke patients, and 46 meningioma patients, demonstrate the superiority and clinical applicability of FPS. Furthermore, FPS is applied to diffusion tensor imaging (DTI), underscoring its versatility and potential for broader medical applications. The code is available at https://github.com/flyannie/FPS.
MvKeTR: Chest CT Report Generation with Multi-View Perception and Knowledge Enhancement
Nov 27, 2024

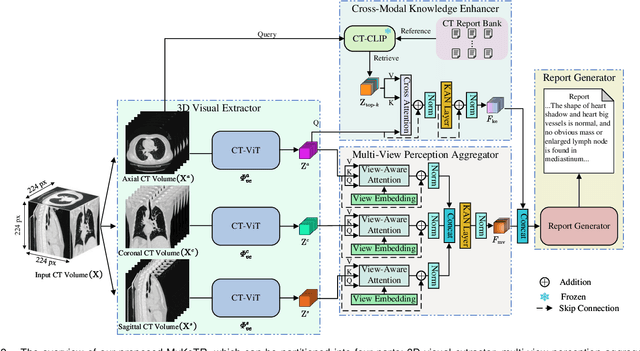

CT report generation (CTRG) aims to automatically generate diagnostic reports for 3D volumes, relieving clinicians' workload and improving patient care. Despite clinical value, existing works fail to effectively incorporate diagnostic information from multiple anatomical views and lack related clinical expertise essential for accurate and reliable diagnosis. To resolve these limitations, we propose a novel Multi-view perception Knowledge-enhanced Tansformer (MvKeTR) to mimic the diagnostic workflow of clinicians. Just as radiologists first examine CT scans from multiple planes, a Multi-View Perception Aggregator (MVPA) with view-aware attention effectively synthesizes diagnostic information from multiple anatomical views. Then, inspired by how radiologists further refer to relevant clinical records to guide diagnostic decision-making, a Cross-Modal Knowledge Enhancer (CMKE) retrieves the most similar reports based on the query volume to incorporate domain knowledge into the diagnosis procedure. Furthermore, instead of traditional MLPs, we employ Kolmogorov-Arnold Networks (KANs) with learnable nonlinear activation functions as the fundamental building blocks of both modules to better capture intricate diagnostic patterns in CT interpretation. Extensive experiments on the public CTRG-Chest-548K dataset demonstrate that our method outpaces prior state-of-the-art models across all metrics.
High-efficient deep learning-based DTI reconstruction with flexible diffusion gradient encoding scheme
Aug 02, 2023Purpose: To develop and evaluate a novel dynamic-convolution-based method called FlexDTI for high-efficient diffusion tensor reconstruction with flexible diffusion encoding gradient schemes. Methods: FlexDTI was developed to achieve high-quality DTI parametric mapping with flexible number and directions of diffusion encoding gradients. The proposed method used dynamic convolution kernels to embed diffusion gradient direction information into feature maps of the corresponding diffusion signal. Besides, our method realized the generalization of a flexible number of diffusion gradient directions by setting the maximum number of input channels of the network. The network was trained and tested using data sets from the Human Connectome Project and a local hospital. Results from FlexDTI and other advanced tensor parameter estimation methods were compared. Results: Compared to other methods, FlexDTI successfully achieves high-quality diffusion tensor-derived variables even if the number and directions of diffusion encoding gradients are variable. It increases peak signal-to-noise ratio (PSNR) by about 10 dB on Fractional Anisotropy (FA) and Mean Diffusivity (MD), compared with the state-of-the-art deep learning method with flexible diffusion encoding gradient schemes. Conclusion: FlexDTI can well learn diffusion gradient direction information to achieve generalized DTI reconstruction with flexible diffusion gradient schemes. Both flexibility and reconstruction quality can be taken into account in this network.
High-efficient Bloch simulation of magnetic resonance imaging sequences based on deep learning
Oct 19, 2022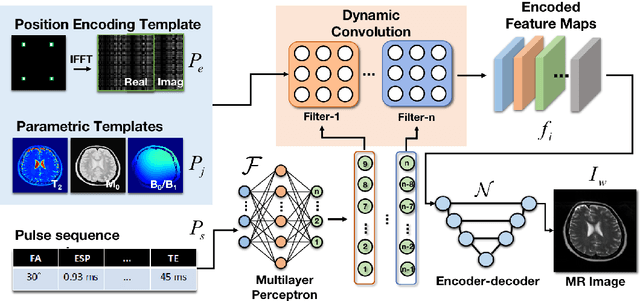

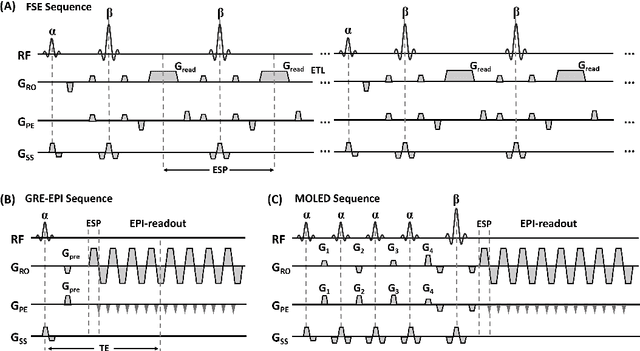
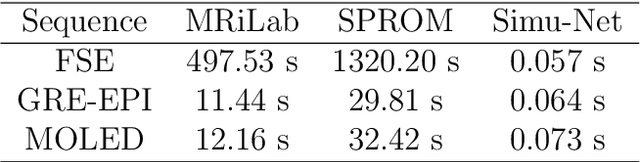
Bloch simulation constitutes an essential part of magnetic resonance imaging (MRI) development. However, even with the graphics processing units (GPU) acceleration, the heavy computational load remains a major challenge, especially in large-scale, high-accuracy simulation scenarios. Here we present a framework based on convolutional neural networks to build a high-efficient 2D Bloch simulator, termed Simu-Net. Compared to the mainstream GPU-based MRI simulation software, Simu-Net successfully accelerates simulations by over hundreds of times in three MRI pulse sequences. The accuracy and robustness of the proposed framework were also verified qualitatively and quantitatively. The trained Simu-Net was applied to generate sufficient customized training samples for deep learning-based T2 mapping and comparable results to conventional methods were obtained in the human brain. As a proof-of-concept work, Simu-Net shows the potential to apply deep learning for rapidly approximating the Bloch equation as a forward physical process.
Model-based Synthetic Data-driven Learning (MOST-DL): Application in Single-shot T2 Mapping with Severe Head Motion Using Overlapping-echo Acquisition
Jul 30, 2021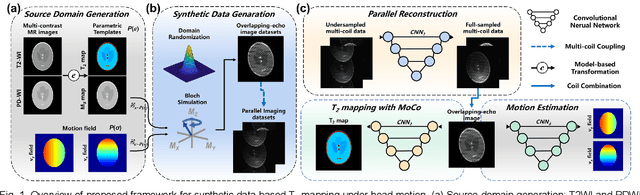
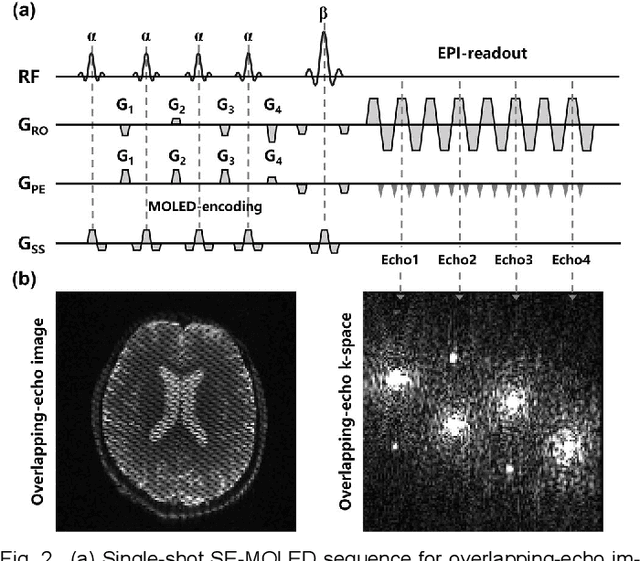
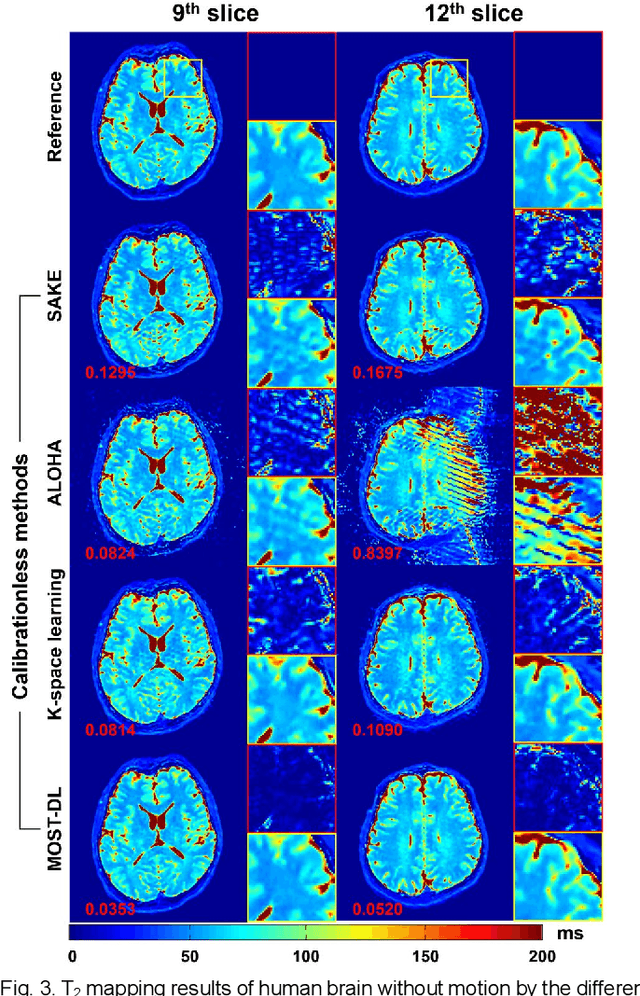
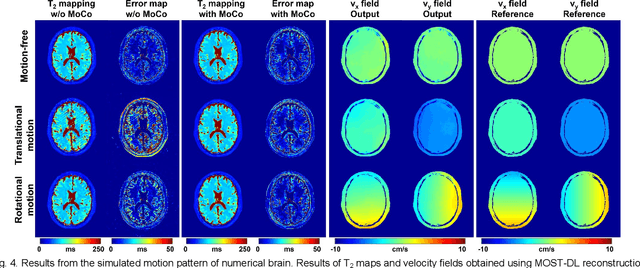
Data-driven learning algorithm has been successfully applied to facilitate reconstruction of medical imaging. However, real-world data needed for supervised learning are typically unavailable or insufficient, especially in the field of magnetic resonance imaging (MRI). Synthetic training samples have provided a potential solution for such problem, while the challenge brought by various non-ideal situations were usually encountered especially under complex experimental conditions. In this study, a general framework, Model-based Synthetic Data-driven Learning (MOST-DL), was proposed to generate paring data for network training to achieve robust T2 mapping using overlapping-echo acquisition under severe head motion accompanied with inhomogeneous RF field. We decomposed this challenging task into parallel reconstruction and motion correction according to a forward model. The neural network was first trained in pure synthetic dataset and then evaluated with in vivo human brain. Experiments showed that MOST-DL method significantly reduces ghosting and motion artifacts in T2 maps in the presence of random and continuous subject movement. We believe that the proposed approach may open a door for solving similar problems with other MRI acquisition methods and can be extended to other areas of medical imaging.
High Efficient Reconstruction of Single-shot T2 Mapping from OverLapping-Echo Detachment Planar Imaging Based on Deep Residual Network
Aug 17, 2017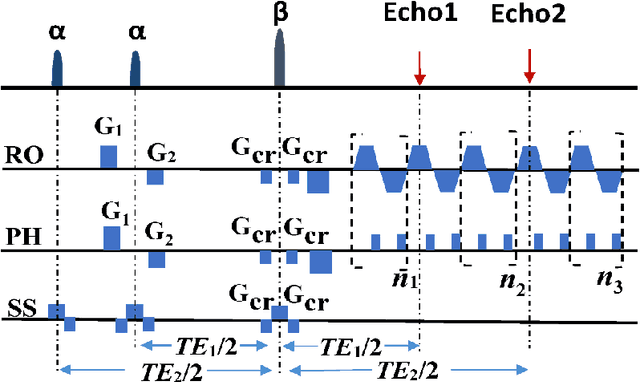
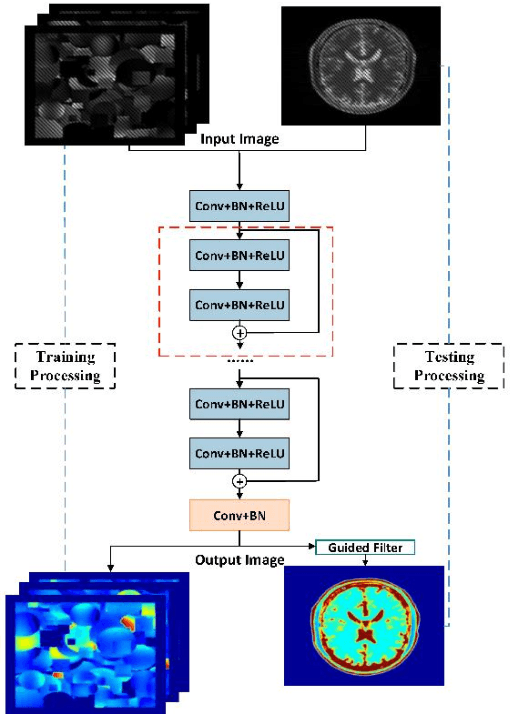
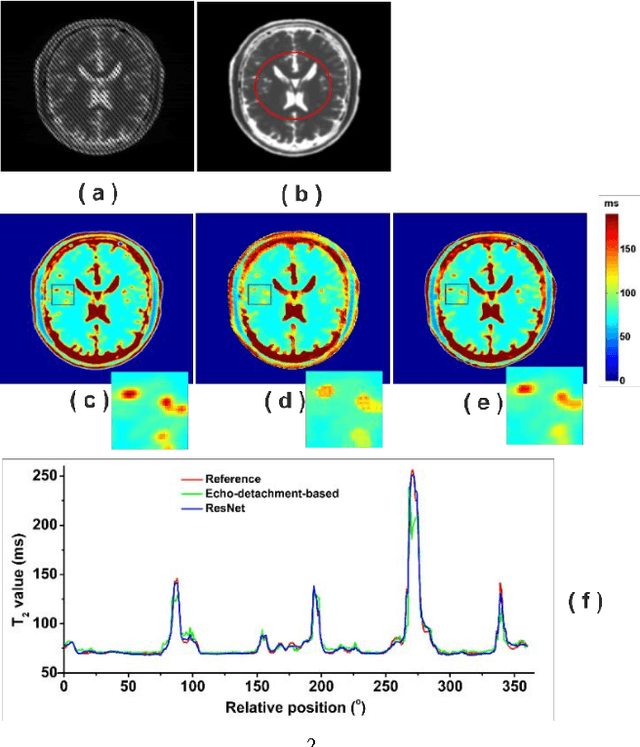
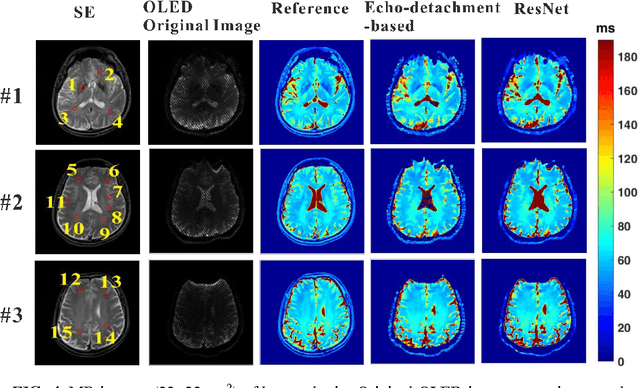
Purpose: An end-to-end deep convolutional neural network (CNN) based on deep residual network (ResNet) was proposed to efficiently reconstruct reliable T2 mapping from single-shot OverLapping-Echo Detachment (OLED) planar imaging. Methods: The training dataset was obtained from simulations carried out on SPROM software developed by our group. The relationship between the original OLED image containing two echo signals and the corresponded T2 mapping was learned by ResNet training. After the ResNet was trained, it was applied to reconstruct the T2 mapping from simulation and in vivo human brain data. Results: Though the ResNet was trained entirely on simulated data, the trained network was generalized well to real human brain data. The results from simulation and in vivo human brain experiments show that the proposed method significantly outperformed the echo-detachment-based method. Reliable T2 mapping was achieved within tens of milliseconds after the network had been trained while the echo-detachment-based OLED reconstruction method took minutes. Conclusion: The proposed method will greatly facilitate real-time dynamic and quantitative MR imaging via OLED sequence, and ResNet has the potential to reconstruct images from complex MRI sequence efficiently.