 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidating LLM-Generated Programs with Metamorphic Prompt Testing
Jun 11, 2024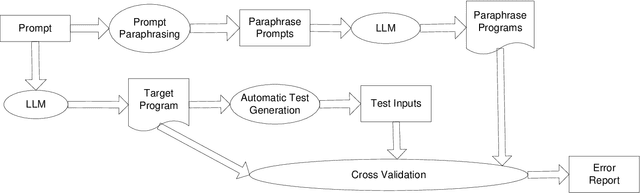
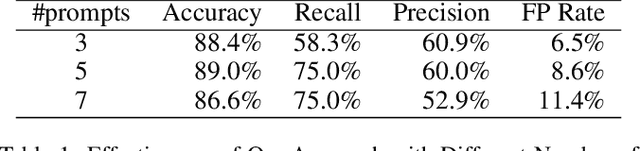
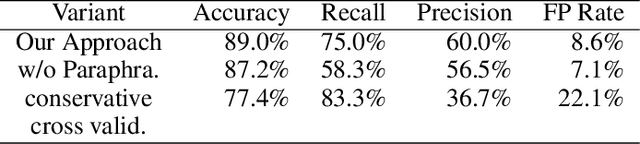
The latest paradigm shift in software development brings in the innovation and automation afforded by Large Language Models (LLMs), showcased by Generative Pre-trained Transformer (GPT), which has shown remarkable capacity to generate code autonomously, significantly reducing the manual effort required for various programming tasks. Although, the potential benefits of LLM-generated code are vast, most notably in efficiency and rapid prototyping, as LLMs become increasingly integrated into the software development lifecycle and hence the supply chain, complex and multifaceted challenges arise as the code generated from these language models carry profound questions on quality and correctness. Research is required to comprehensively explore these critical concerns surrounding LLM-generated code. In this paper, we propose a novel solution called metamorphic prompt testing to address these challenges. Our intuitive observation is that intrinsic consistency always exists among correct code pieces but may not exist among flawed code pieces, so we can detect flaws in the code by detecting inconsistencies. Therefore, we can vary a given prompt to multiple prompts with paraphrasing, and to ask the LLM to acquire multiple versions of generated code, so that we can validate whether the semantic relations still hold in the acquired code through cross-validation. Our evaluation on HumanEval shows that metamorphic prompt testing is able to detect 75 percent of the erroneous programs generated by GPT-4, with a false positive rate of 8.6 percent.
Model-based Synthetic Data-driven Learning (MOST-DL): Application in Single-shot T2 Mapping with Severe Head Motion Using Overlapping-echo Acquisition
Jul 30, 2021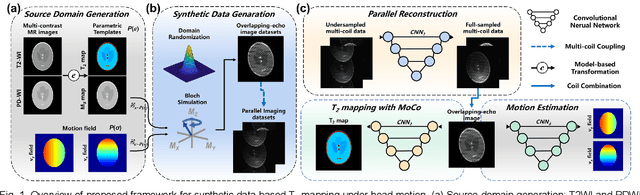
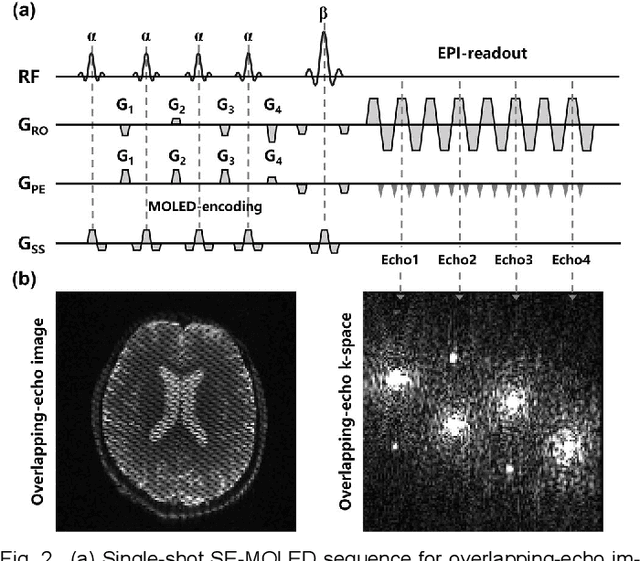
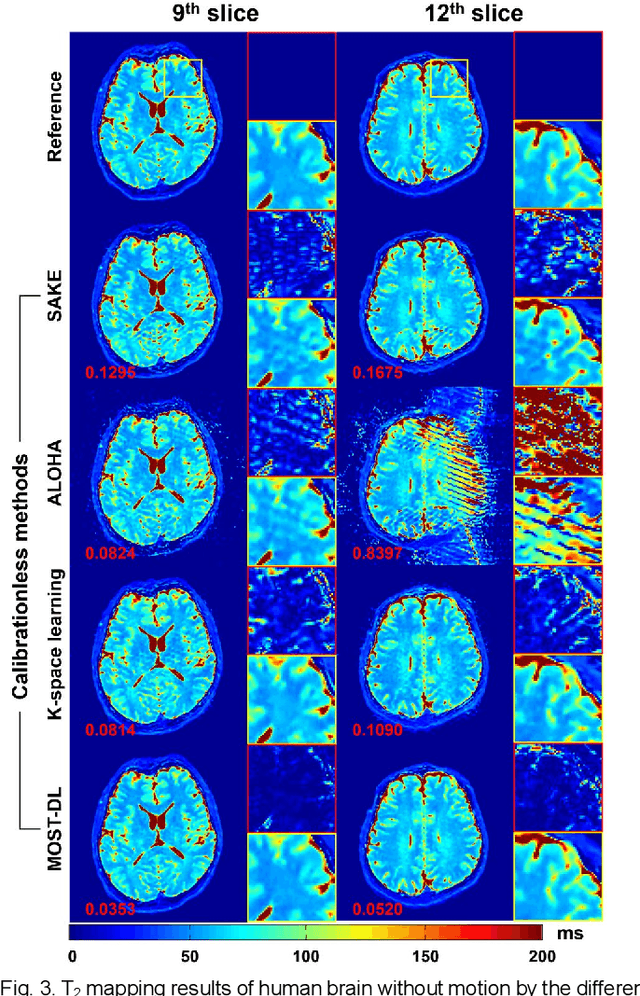
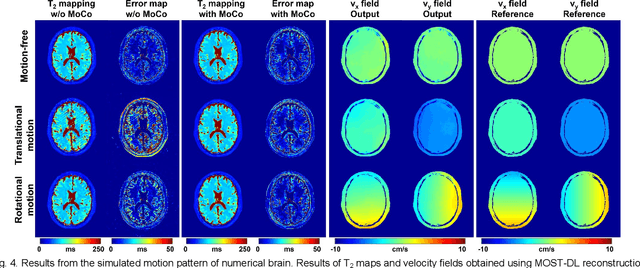
Data-driven learning algorithm has been successfully applied to facilitate reconstruction of medical imaging. However, real-world data needed for supervised learning are typically unavailable or insufficient, especially in the field of magnetic resonance imaging (MRI). Synthetic training samples have provided a potential solution for such problem, while the challenge brought by various non-ideal situations were usually encountered especially under complex experimental conditions. In this study, a general framework, Model-based Synthetic Data-driven Learning (MOST-DL), was proposed to generate paring data for network training to achieve robust T2 mapping using overlapping-echo acquisition under severe head motion accompanied with inhomogeneous RF field. We decomposed this challenging task into parallel reconstruction and motion correction according to a forward model. The neural network was first trained in pure synthetic dataset and then evaluated with in vivo human brain. Experiments showed that MOST-DL method significantly reduces ghosting and motion artifacts in T2 maps in the presence of random and continuous subject movement. We believe that the proposed approach may open a door for solving similar problems with other MRI acquisition methods and can be extended to other areas of medical imaging.
Leveraging Code Generation to Improve Code Retrieval and Summarization via Dual Learning
Feb 25, 2020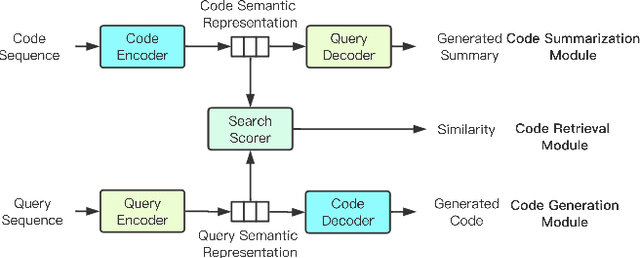
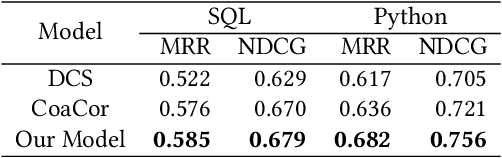
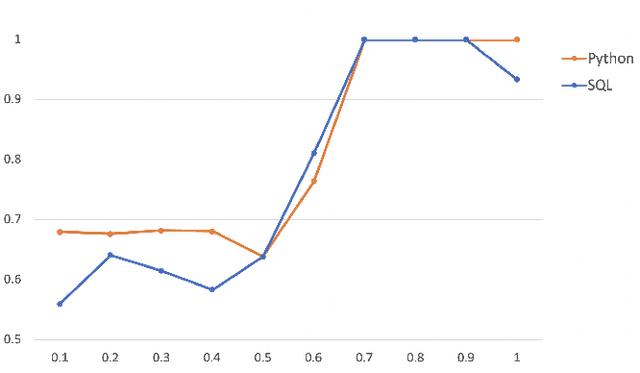
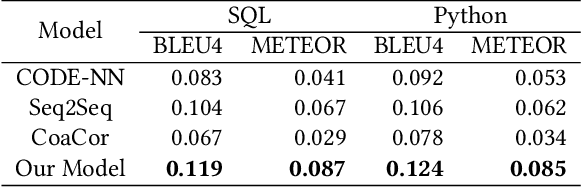
Code summarization generates brief natural language description given a source code snippet, while code retrieval fetches relevant source code given a natural language query. Since both tasks aim to model the association between natural language and programming language, recent studies have combined these two tasks to improve their performance. However, researchers have yet been able to effectively leverage the intrinsic connection between the two tasks as they train these tasks in a separate or pipeline manner, which means their performance can not be well balanced. In this paper, we propose a novel end-to-end model for the two tasks by introducing an additional code generation task. More specifically, we explicitly exploit the probabilistic correlation between code summarization and code generation with dual learning, and utilize the two encoders for code summarization and code generation to train the code retrieval task via multi-task learning. We have carried out extensive experiments on an existing dataset of SQL and Python, and results show that our model can significantly improve the results of the code retrieval task over the-state-of-art models, as well as achieve competitive performance in terms of BLEU score for the code summarization task.