 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Agents Learn from Trajectory-SFT: Semantics or Interfaces?
Feb 02, 2026Large language models are increasingly evaluated as interactive agents, yet standard agent benchmarks conflate two qualitatively distinct sources of success: semantic tool-use and interface-specific interaction pattern memorization. Because both mechanisms can yield identical task success on the original interface, benchmark scores alone are not identifiable evidence of environment-invariant capability. We propose PIPE, a protocol-level evaluation augmentation for diagnosing interface reliance by minimally rewriting environment interfaces while preserving task semantics and execution behavior. Across 16 environments from AgentBench and AgentGym and a range of open-source and API-based agents, PIPE reveals that trajectory-SFT substantially amplifies interface shortcutting: trained agents degrade sharply under minimal interface rewrites, while non-trajectory-trained models remain largely stable. We further introduce Interface Reliance (IR), a counterbalanced alias-based metric that quantifies preference for training-time interfaces, and show that interface shortcutting exhibits environment-dependent, non-monotonic training dynamics that remain invisible under standard evaluation. Our code is available at https://anonymous.4open.science/r/What-Do-Agents-Learn-from-Trajectory-SFT-Semantics-or-Interfaces--0831/.
ToolSafe: Enhancing Tool Invocation Safety of LLM-based agents via Proactive Step-level Guardrail and Feedback
Jan 15, 2026While LLM-based agents can interact with environments via invoking external tools, their expanded capabilities also amplify security risks. Monitoring step-level tool invocation behaviors in real time and proactively intervening before unsafe execution is critical for agent deployment, yet remains under-explored. In this work, we first construct TS-Bench, a novel benchmark for step-level tool invocation safety detection in LLM agents. We then develop a guardrail model, TS-Guard, using multi-task reinforcement learning. The model proactively detects unsafe tool invocation actions before execution by reasoning over the interaction history. It assesses request harmfulness and action-attack correlations, producing interpretable and generalizable safety judgments and feedback. Furthermore, we introduce TS-Flow, a guardrail-feedback-driven reasoning framework for LLM agents, which reduces harmful tool invocations of ReAct-style agents by 65 percent on average and improves benign task completion by approximately 10 percent under prompt injection attacks.
Modeling Uncertainty Trends for Timely Retrieval in Dynamic RAG
Nov 13, 2025Dynamic retrieval-augmented generation (RAG) allows large language models (LLMs) to fetch external knowledge on demand, offering greater adaptability than static RAG. A central challenge in this setting lies in determining the optimal timing for retrieval. Existing methods often trigger retrieval based on low token-level confidence, which may lead to delayed intervention after errors have already propagated. We introduce Entropy-Trend Constraint (ETC), a training-free method that determines optimal retrieval timing by modeling the dynamics of token-level uncertainty. Specifically, ETC utilizes first- and second-order differences of the entropy sequence to detect emerging uncertainty trends, enabling earlier and more precise retrieval. Experiments on six QA benchmarks with three LLM backbones demonstrate that ETC consistently outperforms strong baselines while reducing retrieval frequency. ETC is particularly effective in domain-specific scenarios, exhibiting robust generalization capabilities. Ablation studies and qualitative analyses further confirm that trend-aware uncertainty modeling yields more effective retrieval timing. The method is plug-and-play, model-agnostic, and readily integrable into existing decoding pipelines. Implementation code is included in the supplementary materials.
Autoformalizer with Tool Feedback
Oct 08, 2025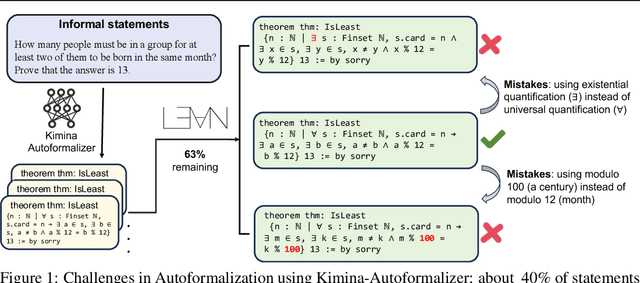

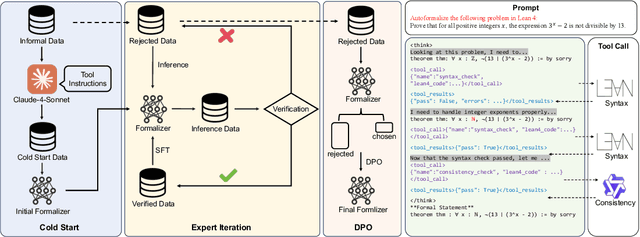
Autoformalization addresses the scarcity of data for Automated Theorem Proving (ATP) by translating mathematical problems from natural language into formal statements. Efforts in recent work shift from directly prompting large language models to training an end-to-end formalizer model from scratch, achieving remarkable advancements. However, existing formalizer still struggles to consistently generate valid statements that meet syntactic validity and semantic consistency. To address this issue, we propose the Autoformalizer with Tool Feedback (ATF), a novel approach that incorporates syntactic and consistency information as tools into the formalization process. By integrating Lean 4 compilers for syntax corrections and employing a multi-LLMs-as-judge approach for consistency validation, the model is able to adaptively refine generated statements according to the tool feedback, enhancing both syntactic validity and semantic consistency. The training of ATF involves a cold-start phase on synthetic tool-calling data, an expert iteration phase to improve formalization capabilities, and Direct Preference Optimization to alleviate ineffective revisions. Experimental results show that ATF markedly outperforms a range of baseline formalizer models, with its superior performance further validated by human evaluations. Subsequent analysis reveals that ATF demonstrates excellent inference scaling properties. Moreover, we open-source Numina-ATF, a dataset containing 750K synthetic formal statements to facilitate advancements in autoformalization and ATP research.
SAEMark: Multi-bit LLM Watermarking with Inference-Time Scaling
Aug 11, 2025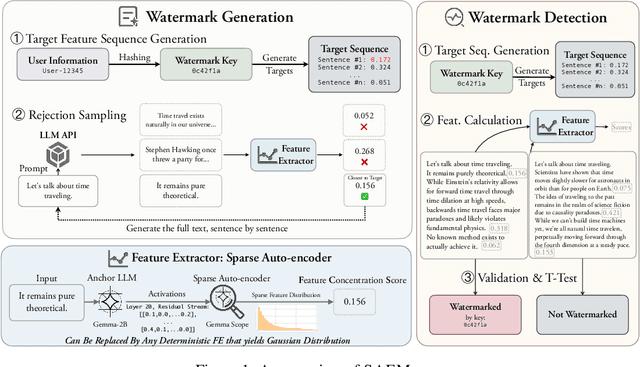


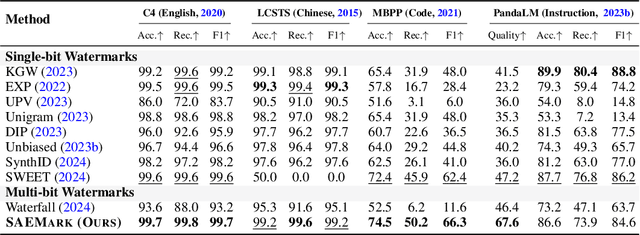
Watermarking LLM-generated text is critical for content attribution and misinformation prevention. However, existing methods compromise text quality, require white-box model access and logit manipulation. These limitations exclude API-based models and multilingual scenarios. We propose SAEMark, a general framework for post-hoc multi-bit watermarking that embeds personalized messages solely via inference-time, feature-based rejection sampling without altering model logits or requiring training. Our approach operates on deterministic features extracted from generated text, selecting outputs whose feature statistics align with key-derived targets. This framework naturally generalizes across languages and domains while preserving text quality through sampling LLM outputs instead of modifying. We provide theoretical guarantees relating watermark success probability and compute budget that hold for any suitable feature extractor. Empirically, we demonstrate the framework's effectiveness using Sparse Autoencoders (SAEs), achieving superior detection accuracy and text quality. Experiments across 4 datasets show SAEMark's consistent performance, with 99.7% F1 on English and strong multi-bit detection accuracy. SAEMark establishes a new paradigm for scalable watermarking that works out-of-the-box with closed-source LLMs while enabling content attribution.
Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
May 23, 2025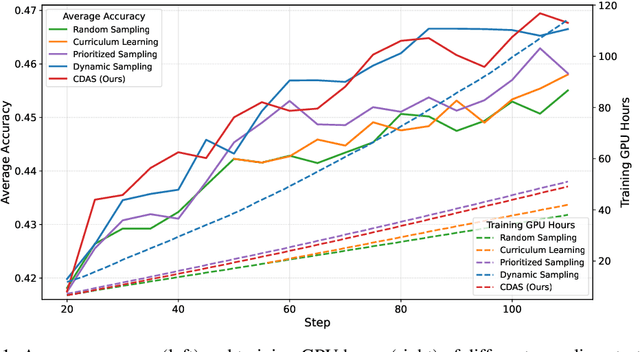
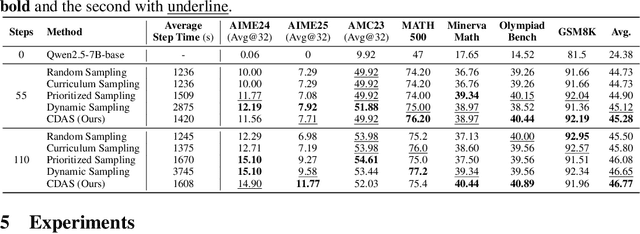
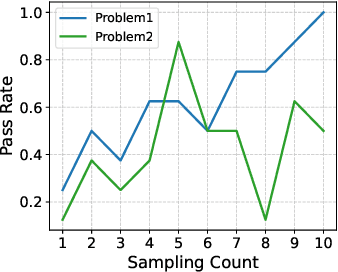
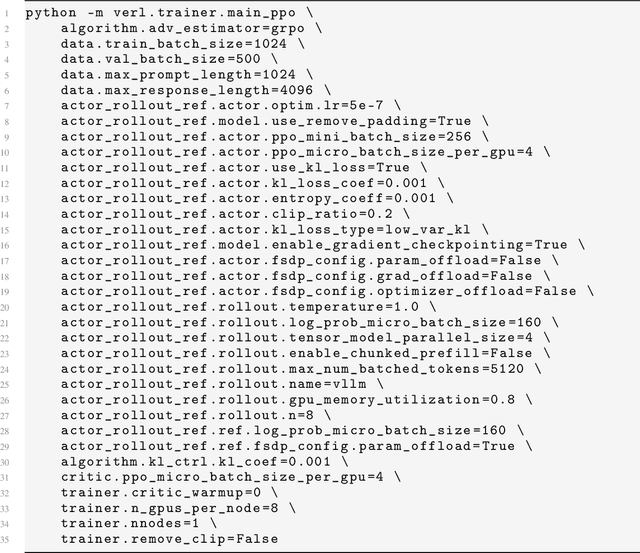
Reinforcement learning exhibits potential in enhancing the reasoning abilities of large language models, yet it is hard to scale for the low sample efficiency during the rollout phase. Existing methods attempt to improve efficiency by scheduling problems based on problem difficulties. However, these approaches suffer from unstable and biased estimations of problem difficulty and fail to capture the alignment between model competence and problem difficulty in RL training, leading to suboptimal results. To tackle these limitations, this paper introduces \textbf{C}ompetence-\textbf{D}ifficulty \textbf{A}lignment \textbf{S}ampling (\textbf{CDAS}), which enables accurate and stable estimation of problem difficulties by aggregating historical performance discrepancies of problems. Then the model competence is quantified to adaptively select problems whose difficulty is in alignment with the model's current competence using a fixed-point system. Experimental results across a range of challenging mathematical benchmarks show that CDAS achieves great improvements in both accuracy and efficiency. CDAS attains the highest average accuracy against baselines and exhibits significant speed advantages compared to Dynamic Sampling, a competitive strategy in DAPO, which is \textbf{2.33} times slower than CDAS.
MPL: Multiple Programming Languages with Large Language Models for Information Extraction
May 22, 2025Recent research in information extraction (IE) focuses on utilizing code-style inputs to enhance structured output generation. The intuition behind this is that the programming languages (PLs) inherently exhibit greater structural organization than natural languages (NLs). This structural advantage makes PLs particularly suited for IE tasks. Nevertheless, existing research primarily focuses on Python for code-style simulation, overlooking the potential of other widely-used PLs (e.g., C++ and Java) during the supervised fine-tuning (SFT) phase. In this research, we propose \textbf{M}ultiple \textbf{P}rogramming \textbf{L}anguages with large language models for information extraction (abbreviated as \textbf{MPL}), a novel framework that explores the potential of incorporating different PLs in the SFT phase. Additionally, we introduce \texttt{function-prompt} with virtual running to simulate code-style inputs more effectively and efficiently. Experimental results on a wide range of datasets demonstrate the effectiveness of MPL. Furthermore, we conduct extensive experiments to provide a comprehensive analysis. We have released our code for future research.
VLM-R$^3$: Region Recognition, Reasoning, and Refinement for Enhanced Multimodal Chain-of-Thought
May 22, 2025Recently, reasoning-based MLLMs have achieved a degree of success in generating long-form textual reasoning chains. However, they still struggle with complex tasks that necessitate dynamic and iterative focusing on and revisiting of visual regions to achieve precise grounding of textual reasoning in visual evidence. We introduce \textbf{VLM-R$^3$} (\textbf{V}isual \textbf{L}anguage \textbf{M}odel with \textbf{R}egion \textbf{R}ecognition and \textbf{R}easoning), a framework that equips an MLLM with the ability to (i) decide \emph{when} additional visual evidence is needed, (ii) determine \emph{where} to ground within the image, and (iii) seamlessly weave the relevant sub-image content back into an interleaved chain-of-thought. The core of our method is \textbf{Region-Conditioned Reinforcement Policy Optimization (R-GRPO)}, a training paradigm that rewards the model for selecting informative regions, formulating appropriate transformations (e.g.\ crop, zoom), and integrating the resulting visual context into subsequent reasoning steps. To bootstrap this policy, we compile a modest but carefully curated Visuo-Lingual Interleaved Rationale (VLIR) corpus that provides step-level supervision on region selection and textual justification. Extensive experiments on MathVista, ScienceQA, and other benchmarks show that VLM-R$^3$ sets a new state of the art in zero-shot and few-shot settings, with the largest gains appearing on questions demanding subtle spatial reasoning or fine-grained visual cue extraction.
Mitigating Spurious Correlations with Causal Logit Perturbation
May 21, 2025Deep learning has seen widespread success in various domains such as science, industry, and society. However, it is acknowledged that certain approaches suffer from non-robustness, relying on spurious correlations for predictions. Addressing these limitations is of paramount importance, necessitating the development of methods that can disentangle spurious correlations. {This study attempts to implement causal models via logit perturbations and introduces a novel Causal Logit Perturbation (CLP) framework to train classifiers with generated causal logit perturbations for individual samples, thereby mitigating the spurious associations between non-causal attributes (i.e., image backgrounds) and classes.} {Our framework employs a} perturbation network to generate sample-wise logit perturbations using a series of training characteristics of samples as inputs. The whole framework is optimized by an online meta-learning-based learning algorithm and leverages human causal knowledge by augmenting metadata in both counterfactual and factual manners. Empirical evaluations on four typical biased learning scenarios, including long-tail learning, noisy label learning, generalized long-tail learning, and subpopulation shift learning, demonstrate that CLP consistently achieves state-of-the-art performance. Moreover, visualization results support the effectiveness of the generated causal perturbations in redirecting model attention towards causal image attributes and dismantling spurious associations.
Can You Really Trust Code Copilots? Evaluating Large Language Models from a Code Security Perspective
May 15, 2025Code security and usability are both essential for various coding assistant applications driven by large language models (LLMs). Current code security benchmarks focus solely on single evaluation task and paradigm, such as code completion and generation, lacking comprehensive assessment across dimensions like secure code generation, vulnerability repair and discrimination. In this paper, we first propose CoV-Eval, a multi-task benchmark covering various tasks such as code completion, vulnerability repair, vulnerability detection and classification, for comprehensive evaluation of LLM code security. Besides, we developed VC-Judge, an improved judgment model that aligns closely with human experts and can review LLM-generated programs for vulnerabilities in a more efficient and reliable way. We conduct a comprehensive evaluation of 20 proprietary and open-source LLMs. Overall, while most LLMs identify vulnerable codes well, they still tend to generate insecure codes and struggle with recognizing specific vulnerability types and performing repairs. Extensive experiments and qualitative analyses reveal key challenges and optimization directions, offering insights for future research in LLM code security.