 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Agents Learn from Trajectory-SFT: Semantics or Interfaces?
Feb 02, 2026Large language models are increasingly evaluated as interactive agents, yet standard agent benchmarks conflate two qualitatively distinct sources of success: semantic tool-use and interface-specific interaction pattern memorization. Because both mechanisms can yield identical task success on the original interface, benchmark scores alone are not identifiable evidence of environment-invariant capability. We propose PIPE, a protocol-level evaluation augmentation for diagnosing interface reliance by minimally rewriting environment interfaces while preserving task semantics and execution behavior. Across 16 environments from AgentBench and AgentGym and a range of open-source and API-based agents, PIPE reveals that trajectory-SFT substantially amplifies interface shortcutting: trained agents degrade sharply under minimal interface rewrites, while non-trajectory-trained models remain largely stable. We further introduce Interface Reliance (IR), a counterbalanced alias-based metric that quantifies preference for training-time interfaces, and show that interface shortcutting exhibits environment-dependent, non-monotonic training dynamics that remain invisible under standard evaluation. Our code is available at https://anonymous.4open.science/r/What-Do-Agents-Learn-from-Trajectory-SFT-Semantics-or-Interfaces--0831/.
SAEMark: Multi-bit LLM Watermarking with Inference-Time Scaling
Aug 11, 2025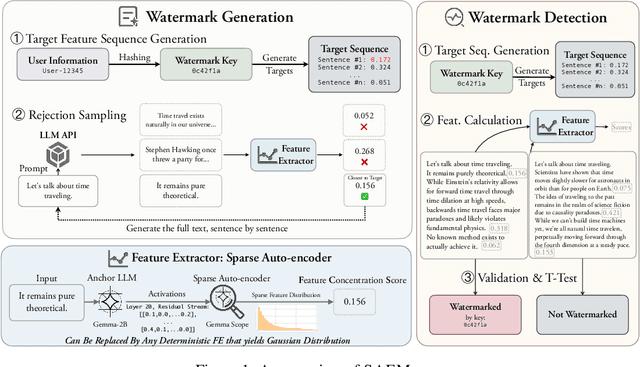


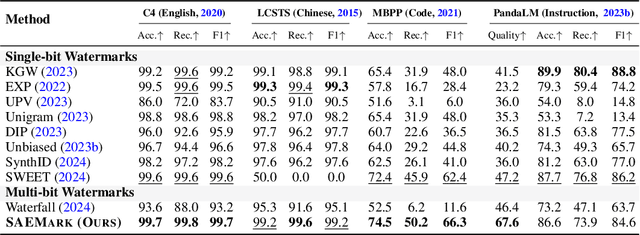
Watermarking LLM-generated text is critical for content attribution and misinformation prevention. However, existing methods compromise text quality, require white-box model access and logit manipulation. These limitations exclude API-based models and multilingual scenarios. We propose SAEMark, a general framework for post-hoc multi-bit watermarking that embeds personalized messages solely via inference-time, feature-based rejection sampling without altering model logits or requiring training. Our approach operates on deterministic features extracted from generated text, selecting outputs whose feature statistics align with key-derived targets. This framework naturally generalizes across languages and domains while preserving text quality through sampling LLM outputs instead of modifying. We provide theoretical guarantees relating watermark success probability and compute budget that hold for any suitable feature extractor. Empirically, we demonstrate the framework's effectiveness using Sparse Autoencoders (SAEs), achieving superior detection accuracy and text quality. Experiments across 4 datasets show SAEMark's consistent performance, with 99.7% F1 on English and strong multi-bit detection accuracy. SAEMark establishes a new paradigm for scalable watermarking that works out-of-the-box with closed-source LLMs while enabling content attribution.
Outcome-Refining Process Supervision for Code Generation
Dec 19, 2024



Large Language Models have demonstrated remarkable capabilities in code generation, yet they often struggle with complex programming tasks that require deep algorithmic reasoning. While process supervision through learned reward models shows promise in guiding reasoning steps, it requires expensive training data and suffers from unreliable evaluation. We propose Outcome-Refining Process Supervision, a novel paradigm that treats outcome refinement itself as the process to be supervised. Our framework leverages concrete execution signals to ground the supervision of reasoning steps, while using tree-structured exploration to maintain multiple solution trajectories simultaneously. Experiments demonstrate that our approach enables even smaller models to achieve high success accuracy and performance metrics on competitive programming tasks, creates more reliable verification than traditional reward models without requiring training PRMs. Our approach achieves significant improvements across 5 models and 3 datasets: an average of 26.9% increase in correctness and 42.2% in efficiency. The results suggest that providing structured reasoning space with concrete verification signals is crucial for solving complex programming tasks. We open-source all our code and data at: https://github.com/zhuohaoyu/ORPS