 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Agents Learn from Trajectory-SFT: Semantics or Interfaces?
Feb 02, 2026Large language models are increasingly evaluated as interactive agents, yet standard agent benchmarks conflate two qualitatively distinct sources of success: semantic tool-use and interface-specific interaction pattern memorization. Because both mechanisms can yield identical task success on the original interface, benchmark scores alone are not identifiable evidence of environment-invariant capability. We propose PIPE, a protocol-level evaluation augmentation for diagnosing interface reliance by minimally rewriting environment interfaces while preserving task semantics and execution behavior. Across 16 environments from AgentBench and AgentGym and a range of open-source and API-based agents, PIPE reveals that trajectory-SFT substantially amplifies interface shortcutting: trained agents degrade sharply under minimal interface rewrites, while non-trajectory-trained models remain largely stable. We further introduce Interface Reliance (IR), a counterbalanced alias-based metric that quantifies preference for training-time interfaces, and show that interface shortcutting exhibits environment-dependent, non-monotonic training dynamics that remain invisible under standard evaluation. Our code is available at https://anonymous.4open.science/r/What-Do-Agents-Learn-from-Trajectory-SFT-Semantics-or-Interfaces--0831/.
StackPlanner: A Centralized Hierarchical Multi-Agent System with Task-Experience Memory Management
Jan 09, 2026Multi-agent systems based on large language models, particularly centralized architectures, have recently shown strong potential for complex and knowledge-intensive tasks. However, central agents often suffer from unstable long-horizon collaboration due to the lack of memory management, leading to context bloat, error accumulation, and poor cross-task generalization. To address both task-level memory inefficiency and the inability to reuse coordination experience, we propose StackPlanner, a hierarchical multi-agent framework with explicit memory control. StackPlanner addresses these challenges by decoupling high-level coordination from subtask execution with active task-level memory control, and by learning to retrieve and exploit reusable coordination experience via structured experience memory and reinforcement learning. Experiments on multiple deep-search and agent system benchmarks demonstrate the effectiveness of our approach in enabling reliable long-horizon multi-agent collaboration.
Bridging Global Intent with Local Details: A Hierarchical Representation Approach for Semantic Validation in Text-to-SQL
Dec 28, 2025Text-to-SQL translates natural language questions into SQL statements grounded in a target database schema. Ensuring the reliability and executability of such systems requires validating generated SQL, but most existing approaches focus only on syntactic correctness, with few addressing semantic validation (detecting misalignments between questions and SQL). As a consequence, effective semantic validation still faces two key challenges: capturing both global user intent and SQL structural details, and constructing high-quality fine-grained sub-SQL annotations. To tackle these, we introduce HEROSQL, a hierarchical SQL representation approach that integrates global intent (via Logical Plans, LPs) and local details (via Abstract Syntax Trees, ASTs). To enable better information propagation, we employ a Nested Message Passing Neural Network (NMPNN) to capture inherent relational information in SQL and aggregate schema-guided semantics across LPs and ASTs. Additionally, to generate high-quality negative samples, we propose an AST-driven sub-SQL augmentation strategy, supporting robust optimization of fine-grained semantic inconsistencies. Extensive experiments conducted on Text-to-SQL validation benchmarks (both in-domain and out-of-domain settings) demonstrate that our approach outperforms existing state-of-the-art methods, achieving an average 9.40% improvement of AUPRC and 12.35% of AUROC in identifying semantic inconsistencies. It excels at detecting fine-grained semantic errors, provides large language models with more granular feedback, and ultimately enhances the reliability and interpretability of data querying platforms.
LoRA Dropout as a Sparsity Regularizer for Overfitting Control
Apr 15, 2024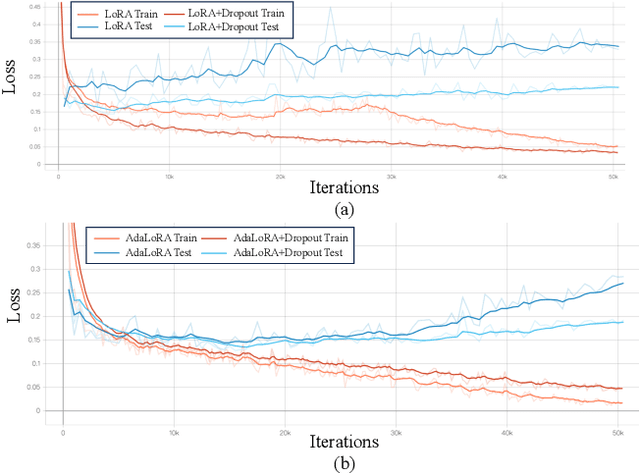
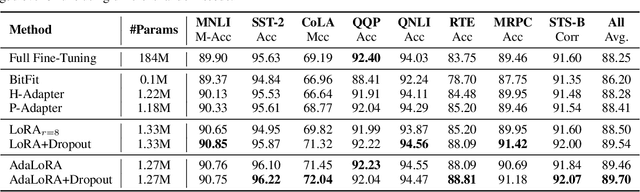
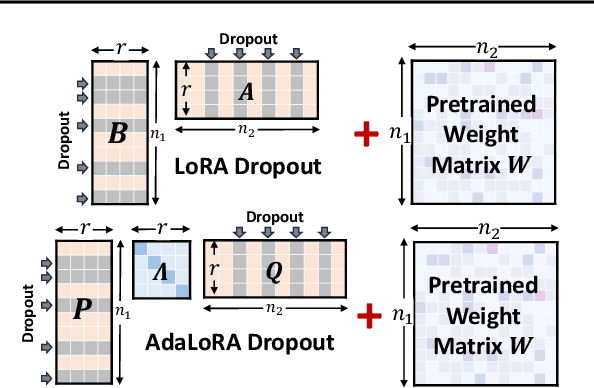
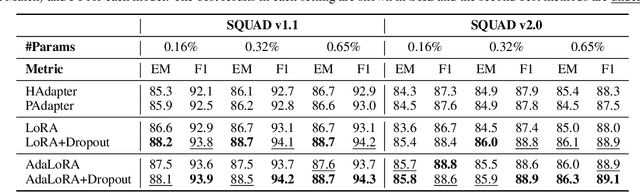
Parameter-efficient fine-tuning methods, represented by LoRA, play an essential role in adapting large-scale pre-trained models to downstream tasks. However, fine-tuning LoRA-series models also faces the risk of overfitting on the training dataset, and yet there's still a lack of theoretical guidance and practical mechanism to control overfitting on LoRA-based PEFT methods. In this paper, we propose a LoRA Dropout mechanism for the LoRA-based methods by introducing random noises to the learnable low-rank matrices and increasing parameter sparsity. We then demonstrate the theoretical mechanism of our LoRA Dropout mechanism from the perspective of sparsity regularization by providing a generalization error bound under this framework. Theoretical results show that appropriate sparsity would help tighten the gap between empirical and generalization risks and thereby control overfitting. Furthermore, based on the LoRA Dropout framework, we introduce a test-time ensemble strategy and provide theoretical evidence demonstrating that the ensemble method can further compress the error bound, and lead to better performance during inference time. Extensive experiments on various NLP tasks provide practical validations of the effectiveness of our LoRA Dropout framework in improving model accuracy and calibration.
Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation
Apr 05, 2024With the increasingly powerful performances and enormous scales of Pretrained Language Models (PLMs), promoting parameter efficiency in fine-tuning has become a crucial need for effective and efficient adaptation to various downstream tasks. One representative line of fine-tuning methods is Orthogonal Fine-tuning (OFT), which rigorously preserves the angular distances within the parameter space to preserve the pretrained knowledge. Despite the empirical effectiveness, OFT still suffers low parameter efficiency at $\mathcal{O}(d^2)$ and limited capability of downstream adaptation. Inspired by Givens rotation, in this paper, we proposed quasi-Givens Orthogonal Fine-Tuning (qGOFT) to address the problems. We first use $\mathcal{O}(d)$ Givens rotations to accomplish arbitrary orthogonal transformation in $SO(d)$ with provable equivalence, reducing parameter complexity from $\mathcal{O}(d^2)$ to $\mathcal{O}(d)$. Then we introduce flexible norm and relative angular adjustments under soft orthogonality regularization to enhance the adaptation capability of downstream semantic deviations. Extensive experiments on various tasks and PLMs validate the effectiveness of our methods.
Boosting Semi-Supervised Learning with Contrastive Complementary Labeling
Dec 13, 2022



Semi-supervised learning (SSL) has achieved great success in leveraging a large amount of unlabeled data to learn a promising classifier. A popular approach is pseudo-labeling that generates pseudo labels only for those unlabeled data with high-confidence predictions. As for the low-confidence ones, existing methods often simply discard them because these unreliable pseudo labels may mislead the model. Nevertheless, we highlight that these data with low-confidence pseudo labels can be still beneficial to the training process. Specifically, although the class with the highest probability in the prediction is unreliable, we can assume that this sample is very unlikely to belong to the classes with the lowest probabilities. In this way, these data can be also very informative if we can effectively exploit these complementary labels, i.e., the classes that a sample does not belong to. Inspired by this, we propose a novel Contrastive Complementary Labeling (CCL) method that constructs a large number of reliable negative pairs based on the complementary labels and adopts contrastive learning to make use of all the unlabeled data. Extensive experiments demonstrate that CCL significantly improves the performance on top of existing methods. More critically, our CCL is particularly effective under the label-scarce settings. For example, we yield an improvement of 2.43% over FixMatch on CIFAR-10 only with 40 labeled data.