 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA Dropout as a Sparsity Regularizer for Overfitting Control
Paper and Code
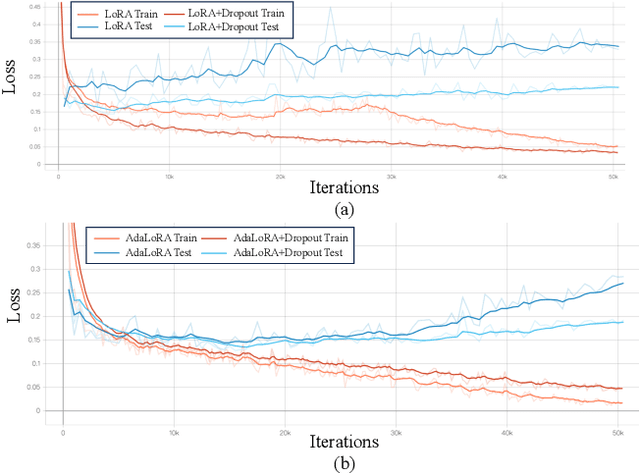
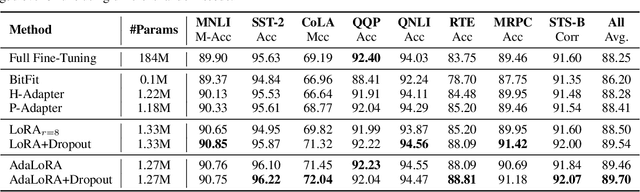
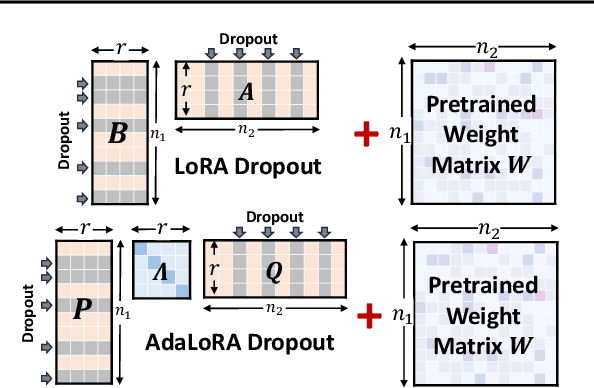
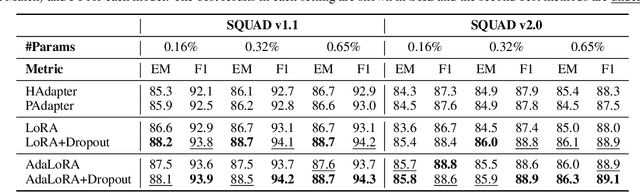
Parameter-efficient fine-tuning methods, represented by LoRA, play an essential role in adapting large-scale pre-trained models to downstream tasks. However, fine-tuning LoRA-series models also faces the risk of overfitting on the training dataset, and yet there's still a lack of theoretical guidance and practical mechanism to control overfitting on LoRA-based PEFT methods. In this paper, we propose a LoRA Dropout mechanism for the LoRA-based methods by introducing random noises to the learnable low-rank matrices and increasing parameter sparsity. We then demonstrate the theoretical mechanism of our LoRA Dropout mechanism from the perspective of sparsity regularization by providing a generalization error bound under this framework. Theoretical results show that appropriate sparsity would help tighten the gap between empirical and generalization risks and thereby control overfitting. Furthermore, based on the LoRA Dropout framework, we introduce a test-time ensemble strategy and provide theoretical evidence demonstrating that the ensemble method can further compress the error bound, and lead to better performance during inference time. Extensive experiments on various NLP tasks provide practical validations of the effectiveness of our LoRA Dropout framework in improving model accuracy and calibration.