 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeiSD: Hybrid Speculative Decoding for Embodied Vision-Language-Action Models with Kinematic Awareness
Mar 18, 2026Vision-Language-Action (VLA) Models have become the mainstream solution for robot control, but suffer from slow inference speeds. Speculative Decoding (SD) is a promising acceleration method which can be divided into two categories: drafter-based SD and retrieval-based SD. Existing methods fail to analyze the advantages and disadvantages of these two types of SD in VLA models, leading to their sole application or optimization. In this paper, we analyze the trajectory patterns of robots controlled by the VLA model and derive a key insight: the two types of SD should be used in a hybrid manner. However, achieving hybrid SD in VLA models poses several challenges: (1) draft rejection and persistent errors in retrieval-based SD; (2) difficulty in determining the hybrid boundary. To address these, we propose the HeiSD framework. We propose a retrieval-based SD optimization method in HeiSD,which contains a verify-skip mechanism and a sequence-wise relaxed acceptance strategy. Moreover, we proposed a kinematic-based fused metric in HeiSD to automatically determine the hybrid boundary. Experimental results demonstrate that HeiSD attains a speedup of up to 2.45x in simulation benchmarks and 2.06x~2.41x in real-world scenarios, while sustaining a high task success rate.
DyQ-VLA: Temporal-Dynamic-Aware Quantization for Embodied Vision-Language-Action Models
Mar 09, 2026Vision-Language-Action (VLA) models are dominant in embodied intelligence but are constrained by inference overheads. While model quantization alleviates these bottlenecks for edge deployment, static quantization approaches remain suboptimal for VLAs due to two critical challenges: (1) Temporal-dynamic sensitivity, where fixed precision wastes resources by ignoring stage-varying error tolerances; and (2) Real-time allocation, where identifying real-time sensitivity to guide bit allocation remains unsolved. To address these challenges, we propose DyQ-VLA, a dynamic quantization framework for VLAs. Specifically, a sensitivity-aware switching strategy leverages real-time kinematic proxies to trigger the bit-width switch, while a kinematic-guided module dynamically allocates the optimal bit-width. Experiments show that DyQ-VLA requires only 30.9% of the original memory footprint while maintaining 99.5% of its original performance, achieving 1.49x simulation and up to 1.43x real-world speedups.
KERV: Kinematic-Rectified Speculative Decoding for Embodied VLA Models
Mar 02, 2026Vision-Language-Action (VLA) models build a token-domain robot control paradigm, yet suffer from low speed. Speculative Decoding (SD) is an optimization strategy that can boost inference speed. Two key issues emerge when integrating VLA and SD: first, SD relies on re-inference to address token errors, which is computationally expensive; second, to mitigate token errors, the acceptance threshold in SD requires careful adjustment. Existing works fail to address the above two issues effectively. Meanwhile, as the bridge between AI and the physical world, existing embodied intelligence has overlooked the application of robotic kinematics. To address these issues, we innovatively combine token-domain VLA models with kinematic-domain prediction for SD, proposing a kinematic-rectified SD framework named KERV. We employ a kinematics-based Kalman Filter to predict actions and compensate for SD errors, avoiding costly re-inference. Moreover, we design a kinematics-based adjustment strategy to dynamically rectify the acceptance threshold, addressing the difficulty of threshold determination. Experimental results across diverse tasks and environments demonstrate that KERV achieves 27%~37% acceleration with nearly no Success Rate loss.
FANformer: Improving Large Language Models Through Effective Periodicity Modeling
Feb 28, 2025Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
Why language models collapse when trained on recursively generated text
Dec 19, 2024



Language models (LMs) have been widely used to generate text on the Internet. The generated text is often collected into the training corpus of the next generations of LMs. Previous work has experimentally found that LMs collapse when trained on recursively generated text. This paper contributes to existing knowledge from two aspects. We present a theoretical proof of LM collapse. Our proof reveals the cause of LM collapse and proves that all auto-regressive LMs will definitely collapse. We present a new finding: the performance of LMs gradually declines when trained on recursively generated text until they perform no better than a randomly initialized LM. The trained LMs produce large amounts of repetitive text and perform poorly across a wide range of natural language tasks. The above proof and new findings deepen our understanding of LM collapse and offer valuable insights that may inspire new training techniques to mitigate this threat.
LoRA Dropout as a Sparsity Regularizer for Overfitting Control
Apr 15, 2024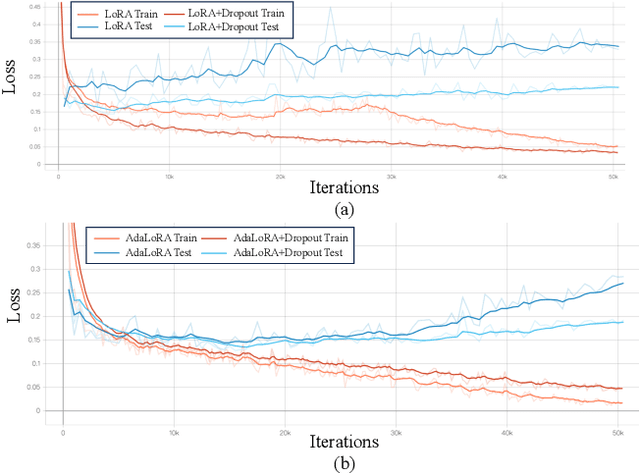
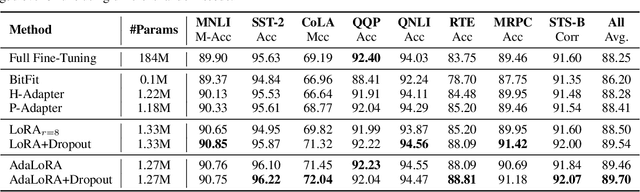
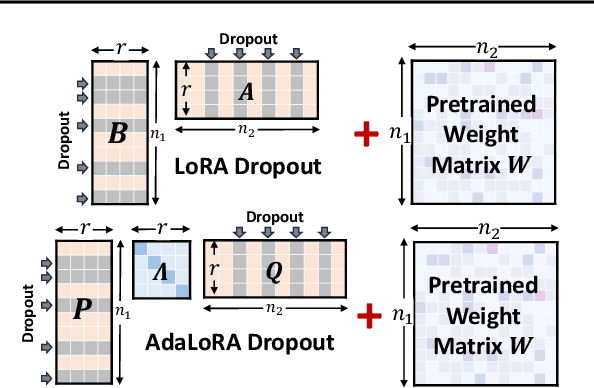
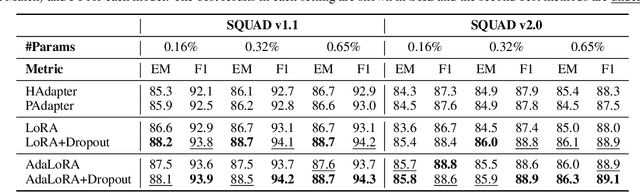
Parameter-efficient fine-tuning methods, represented by LoRA, play an essential role in adapting large-scale pre-trained models to downstream tasks. However, fine-tuning LoRA-series models also faces the risk of overfitting on the training dataset, and yet there's still a lack of theoretical guidance and practical mechanism to control overfitting on LoRA-based PEFT methods. In this paper, we propose a LoRA Dropout mechanism for the LoRA-based methods by introducing random noises to the learnable low-rank matrices and increasing parameter sparsity. We then demonstrate the theoretical mechanism of our LoRA Dropout mechanism from the perspective of sparsity regularization by providing a generalization error bound under this framework. Theoretical results show that appropriate sparsity would help tighten the gap between empirical and generalization risks and thereby control overfitting. Furthermore, based on the LoRA Dropout framework, we introduce a test-time ensemble strategy and provide theoretical evidence demonstrating that the ensemble method can further compress the error bound, and lead to better performance during inference time. Extensive experiments on various NLP tasks provide practical validations of the effectiveness of our LoRA Dropout framework in improving model accuracy and calibration.
Exploring the Potential of Large Language Models in Graph Generation
Mar 21, 2024Large language models (LLMs) have achieved great success in many fields, and recent works have studied exploring LLMs for graph discriminative tasks such as node classification. However, the abilities of LLMs for graph generation remain unexplored in the literature. Graph generation requires the LLM to generate graphs with given properties, which has valuable real-world applications such as drug discovery, while tends to be more challenging. In this paper, we propose LLM4GraphGen to explore the ability of LLMs for graph generation with systematical task designs and extensive experiments. Specifically, we propose several tasks tailored with comprehensive experiments to address key questions regarding LLMs' understanding of different graph structure rules, their ability to capture structural type distributions, and their utilization of domain knowledge for property-based graph generation. Our evaluations demonstrate that LLMs, particularly GPT-4, exhibit preliminary abilities in graph generation tasks, including rule-based and distribution-based generation. We also observe that popular prompting methods, such as few-shot and chain-of-thought prompting, do not consistently enhance performance. Besides, LLMs show potential in generating molecules with specific properties. These findings may serve as foundations for designing good LLMs based models for graph generation and provide valuable insights and further research.
Improving Code Generation by Dynamic Temperature Sampling
Sep 06, 2023Recently, Large Language Models (LLMs) have shown impressive results in code generation. However, existing decoding strategies are designed for Natural Language (NL) generation, overlooking the differences between NL and programming languages (PL). Due to this oversight, a better decoding strategy for code generation remains an open question. In this paper, we conduct the first systematic study to explore a decoding strategy specialized in code generation. With an analysis of loss distributions of code tokens, we find that code tokens can be divided into two categories: challenging tokens that are difficult to predict and confident tokens that can be easily inferred. Among them, the challenging tokens mainly appear at the beginning of a code block. Inspired by the above findings, we propose a simple yet effective method: Adaptive Temperature (AdapT) sampling, which dynamically adjusts the temperature coefficient when decoding different tokens. We apply a larger temperature when sampling for challenging tokens, allowing LLMs to explore diverse choices. We employ a smaller temperature for confident tokens avoiding the influence of tail randomness noises. We apply AdapT sampling to LLMs with different sizes and conduct evaluations on two popular datasets. Results show that AdapT sampling significantly outperforms state-of-the-art decoding strategy.
DeepVisualInsight: Time-Travelling Visualization for Spatio-Temporal Causality of Deep Classification Training
Dec 31, 2021
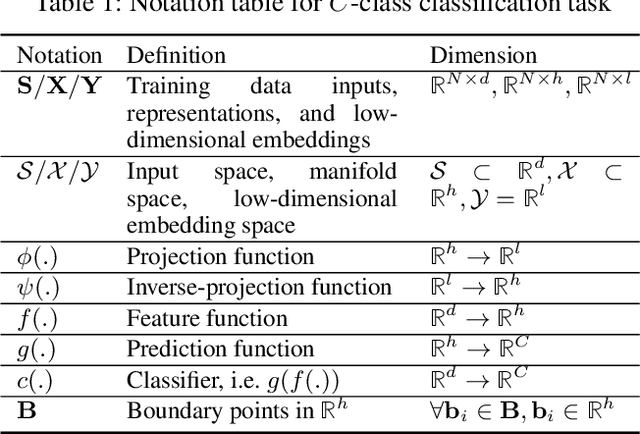
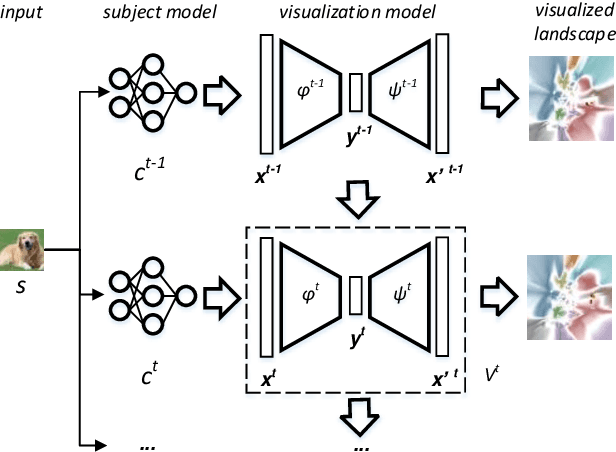
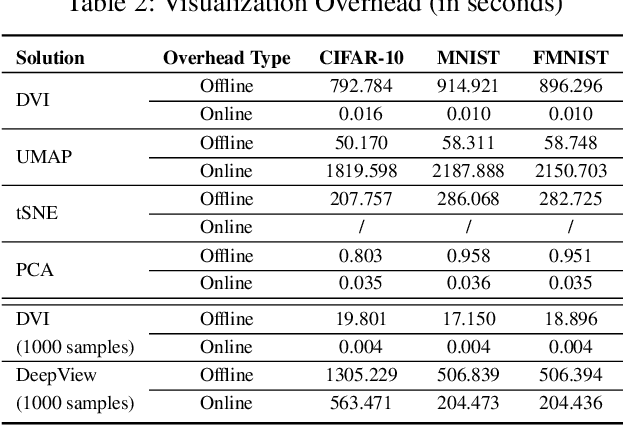
Understanding how the predictions of deep learning models are formed during the training process is crucial to improve model performance and fix model defects, especially when we need to investigate nontrivial training strategies such as active learning, and track the root cause of unexpected training results such as performance degeneration. In this work, we propose a time-travelling visual solution DeepVisualInsight (DVI), aiming to manifest the spatio-temporal causality while training a deep learning image classifier. The spatio-temporal causality demonstrates how the gradient-descent algorithm and various training data sampling techniques can influence and reshape the layout of learnt input representation and the classification boundaries in consecutive epochs. Such causality allows us to observe and analyze the whole learning process in the visible low dimensional space. Technically, we propose four spatial and temporal properties and design our visualization solution to satisfy them. These properties preserve the most important information when inverse-)projecting input samples between the visible low-dimensional and the invisible high-dimensional space, for causal analyses. Our extensive experiments show that, comparing to baseline approaches, we achieve the best visualization performance regarding the spatial/temporal properties and visualization efficiency. Moreover, our case study shows that our visual solution can well reflect the characteristics of various training scenarios, showing good potential of DVI as a debugging tool for analyzing deep learning training processes.
Massive Self-Assembly in Grid Environments
Feb 23, 2021


Self-assembly plays an essential role in many natural processes, involving the formation and evolution of living or non-living structures, and shows potential applications in many emerging domains. In existing research and practice, there still lacks an ideal self-assembly mechanism that manifests efficiency, scalability, and stability at the same time. Inspired by phototaxis observed in nature, we propose a computational approach for massive self-assembly of connected shapes in grid environments. The key component of this approach is an artificial light field superimposed on a grid environment, which is determined by the positions of all agents and at the same time drives all agents to change their positions, forming a dynamic mutual feedback process. This work advances the understanding and potential applications of self-assembly.