 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeiSD: Hybrid Speculative Decoding for Embodied Vision-Language-Action Models with Kinematic Awareness
Mar 18, 2026Vision-Language-Action (VLA) Models have become the mainstream solution for robot control, but suffer from slow inference speeds. Speculative Decoding (SD) is a promising acceleration method which can be divided into two categories: drafter-based SD and retrieval-based SD. Existing methods fail to analyze the advantages and disadvantages of these two types of SD in VLA models, leading to their sole application or optimization. In this paper, we analyze the trajectory patterns of robots controlled by the VLA model and derive a key insight: the two types of SD should be used in a hybrid manner. However, achieving hybrid SD in VLA models poses several challenges: (1) draft rejection and persistent errors in retrieval-based SD; (2) difficulty in determining the hybrid boundary. To address these, we propose the HeiSD framework. We propose a retrieval-based SD optimization method in HeiSD,which contains a verify-skip mechanism and a sequence-wise relaxed acceptance strategy. Moreover, we proposed a kinematic-based fused metric in HeiSD to automatically determine the hybrid boundary. Experimental results demonstrate that HeiSD attains a speedup of up to 2.45x in simulation benchmarks and 2.06x~2.41x in real-world scenarios, while sustaining a high task success rate.
DyQ-VLA: Temporal-Dynamic-Aware Quantization for Embodied Vision-Language-Action Models
Mar 09, 2026Vision-Language-Action (VLA) models are dominant in embodied intelligence but are constrained by inference overheads. While model quantization alleviates these bottlenecks for edge deployment, static quantization approaches remain suboptimal for VLAs due to two critical challenges: (1) Temporal-dynamic sensitivity, where fixed precision wastes resources by ignoring stage-varying error tolerances; and (2) Real-time allocation, where identifying real-time sensitivity to guide bit allocation remains unsolved. To address these challenges, we propose DyQ-VLA, a dynamic quantization framework for VLAs. Specifically, a sensitivity-aware switching strategy leverages real-time kinematic proxies to trigger the bit-width switch, while a kinematic-guided module dynamically allocates the optimal bit-width. Experiments show that DyQ-VLA requires only 30.9% of the original memory footprint while maintaining 99.5% of its original performance, achieving 1.49x simulation and up to 1.43x real-world speedups.
KERV: Kinematic-Rectified Speculative Decoding for Embodied VLA Models
Mar 02, 2026Vision-Language-Action (VLA) models build a token-domain robot control paradigm, yet suffer from low speed. Speculative Decoding (SD) is an optimization strategy that can boost inference speed. Two key issues emerge when integrating VLA and SD: first, SD relies on re-inference to address token errors, which is computationally expensive; second, to mitigate token errors, the acceptance threshold in SD requires careful adjustment. Existing works fail to address the above two issues effectively. Meanwhile, as the bridge between AI and the physical world, existing embodied intelligence has overlooked the application of robotic kinematics. To address these issues, we innovatively combine token-domain VLA models with kinematic-domain prediction for SD, proposing a kinematic-rectified SD framework named KERV. We employ a kinematics-based Kalman Filter to predict actions and compensate for SD errors, avoiding costly re-inference. Moreover, we design a kinematics-based adjustment strategy to dynamically rectify the acceptance threshold, addressing the difficulty of threshold determination. Experimental results across diverse tasks and environments demonstrate that KERV achieves 27%~37% acceleration with nearly no Success Rate loss.
SpotTune: Leveraging Transient Resources for Cost-efficient Hyper-parameter Tuning in the Public Cloud
Dec 07, 2020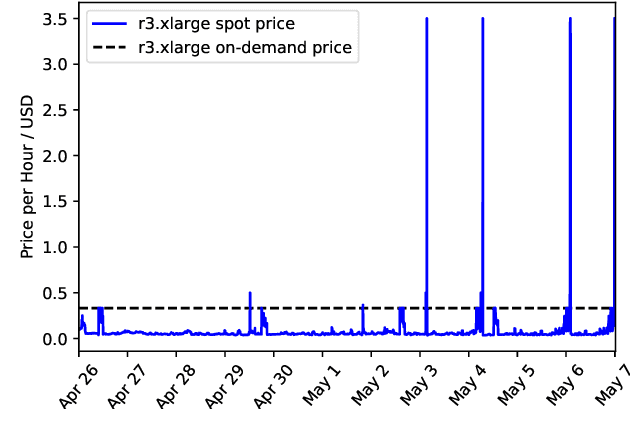
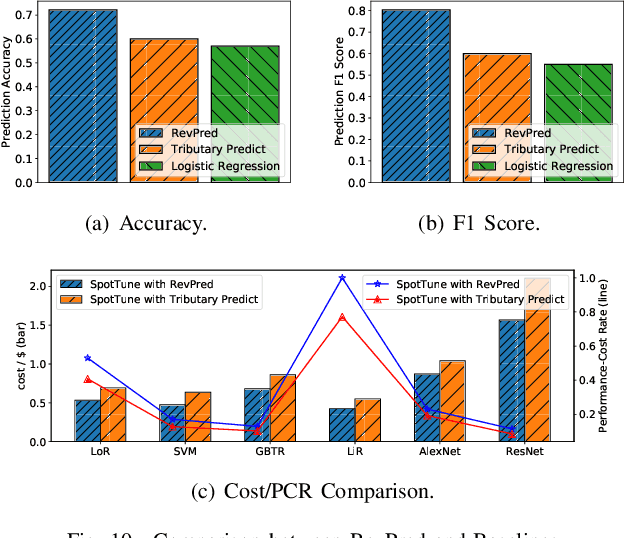
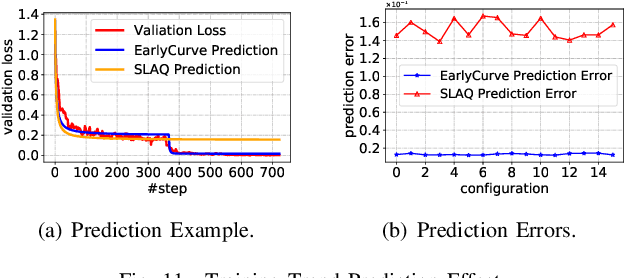
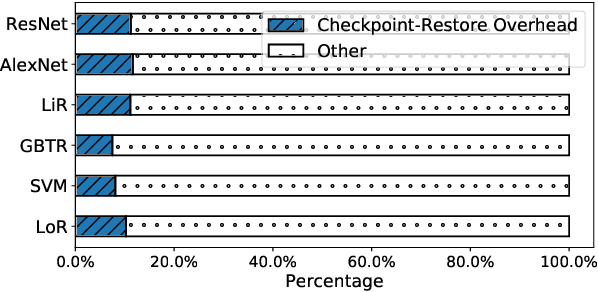
Hyper-parameter tuning (HPT) is crucial for many machine learning (ML) algorithms. But due to the large searching space, HPT is usually time-consuming and resource-intensive. Nowadays, many researchers use public cloud resources to train machine learning models, convenient yet expensive. How to speed up the HPT process while at the same time reduce cost is very important for cloud ML users. In this paper, we propose SpotTune, an approach that exploits transient revocable resources in the public cloud with some tailored strategies to do HPT in a parallel and cost-efficient manner. Orchestrating the HPT process upon transient servers, SpotTune uses two main techniques, fine-grained cost-aware resource provisioning, and ML training trend predicting, to reduce the monetary cost and runtime of HPT processes. Our evaluations show that SpotTune can reduce the cost by up to 90% and achieve a 16.61x performance-cost rate improvement.
S3ML: A Secure Serving System for Machine Learning Inference
Oct 13, 2020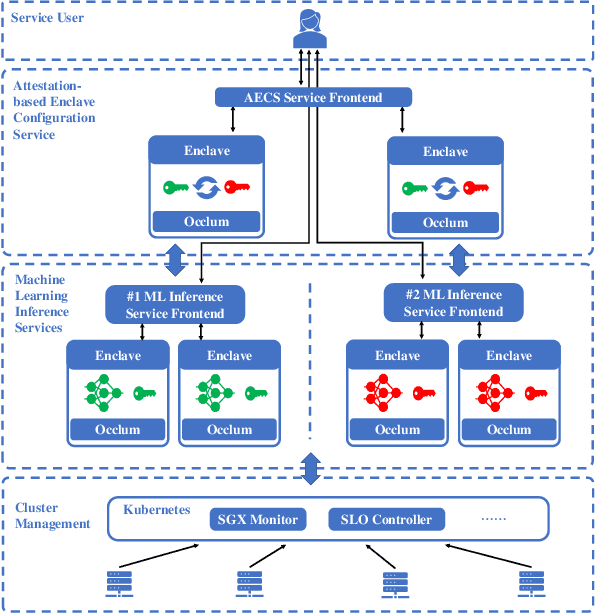
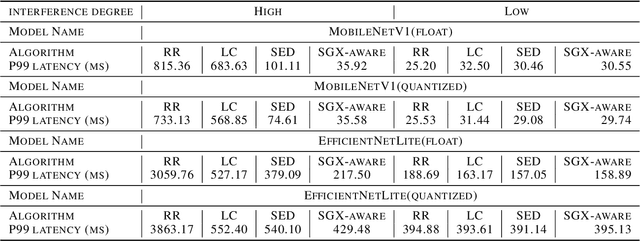
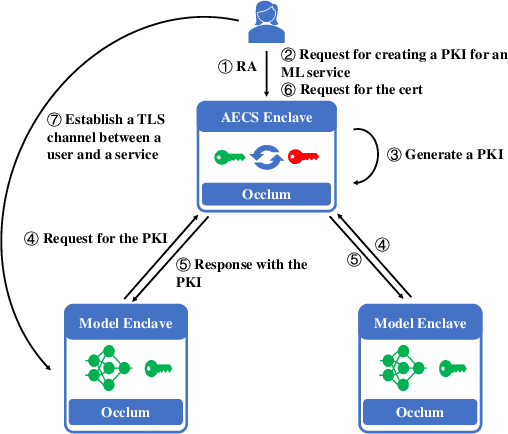
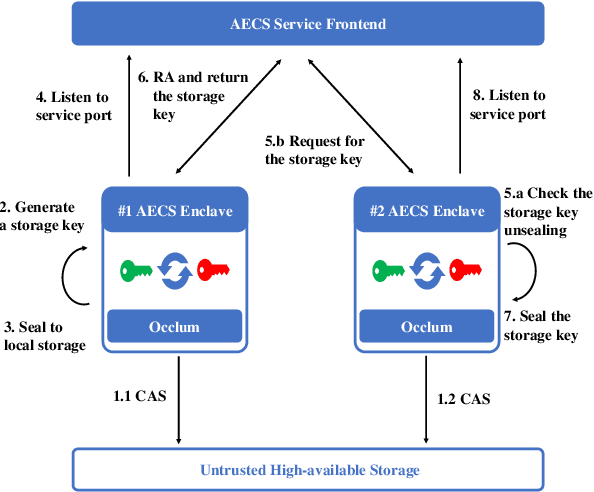
We present S3ML, a secure serving system for machine learning inference in this paper. S3ML runs machine learning models in Intel SGX enclaves to protect users' privacy. S3ML designs a secure key management service to construct flexible privacy-preserving server clusters and proposes novel SGX-aware load balancing and scaling methods to satisfy users' Service-Level Objectives. We have implemented S3ML based on Kubernetes as a low-overhead, high-available, and scalable system. We demonstrate the system performance and effectiveness of S3ML through extensive experiments on a series of widely-used models.