 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast, Performant, Secure Distributed Training Framework For Large Language Model
Jan 19, 2024



The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. However, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security.
S3ML: A Secure Serving System for Machine Learning Inference
Oct 13, 2020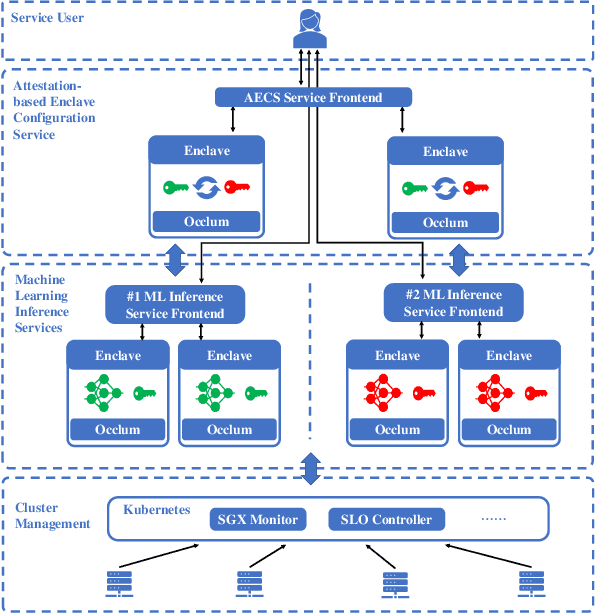
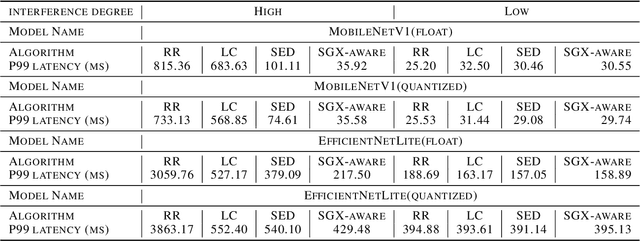
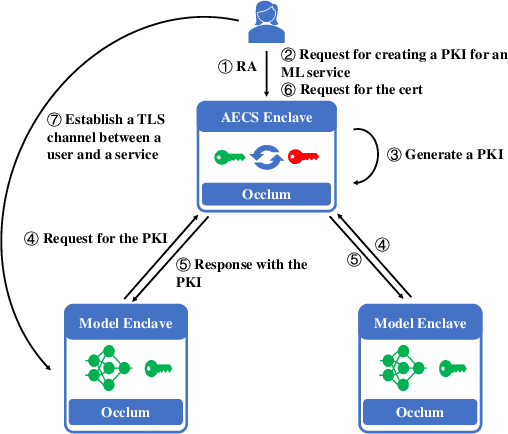
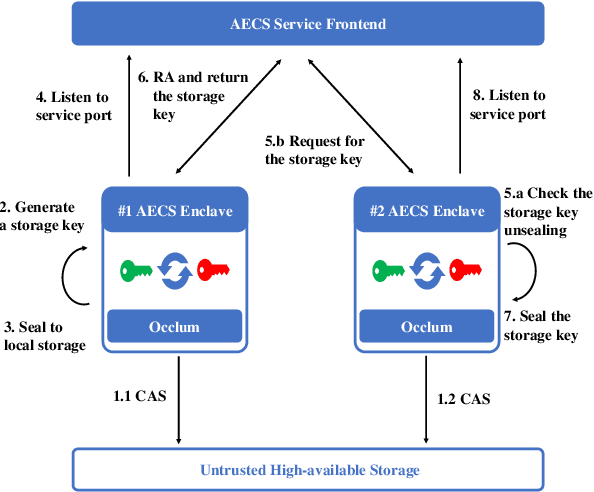
We present S3ML, a secure serving system for machine learning inference in this paper. S3ML runs machine learning models in Intel SGX enclaves to protect users' privacy. S3ML designs a secure key management service to construct flexible privacy-preserving server clusters and proposes novel SGX-aware load balancing and scaling methods to satisfy users' Service-Level Objectives. We have implemented S3ML based on Kubernetes as a low-overhead, high-available, and scalable system. We demonstrate the system performance and effectiveness of S3ML through extensive experiments on a series of widely-used models.