 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDitto: Quantization-aware Secure Inference of Transformers upon MPC
May 09, 2024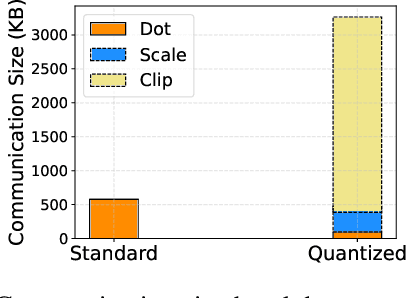
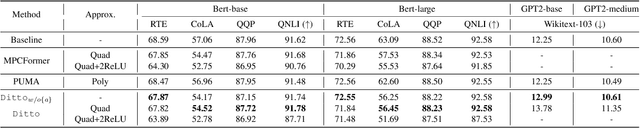
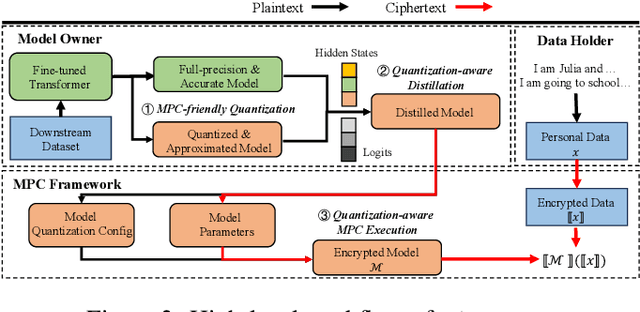
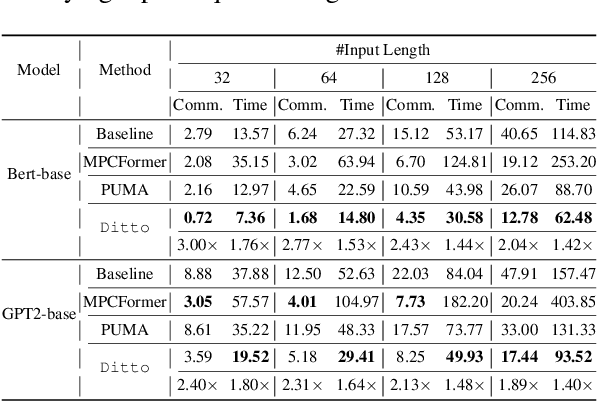
Due to the rising privacy concerns on sensitive client data and trained models like Transformers, secure multi-party computation (MPC) techniques are employed to enable secure inference despite attendant overhead. Existing works attempt to reduce the overhead using more MPC-friendly non-linear function approximations. However, the integration of quantization widely used in plaintext inference into the MPC domain remains unclear. To bridge this gap, we propose the framework named Ditto to enable more efficient quantization-aware secure Transformer inference. Concretely, we first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model utility. Then, we propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference. This approach significantly decreases both computation and communication overhead, leading to improvements in overall efficiency. We conduct extensive experiments on Bert and GPT2 models to evaluate the performance of Ditto. The results demonstrate that Ditto is about $3.14\sim 4.40\times$ faster than MPCFormer (ICLR 2023) and $1.44\sim 2.35\times$ faster than the state-of-the-art work PUMA with negligible utility degradation.
SpotTune: Leveraging Transient Resources for Cost-efficient Hyper-parameter Tuning in the Public Cloud
Dec 07, 2020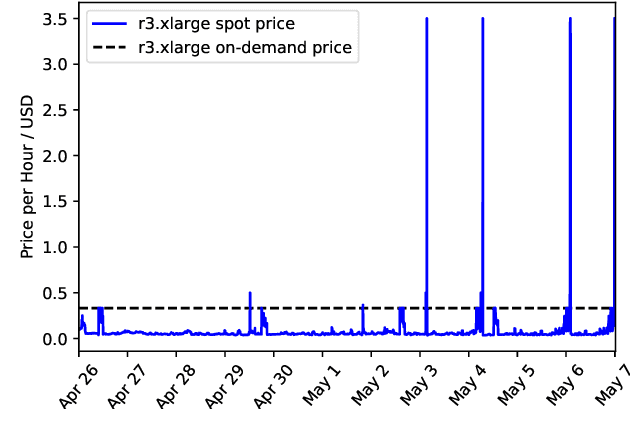
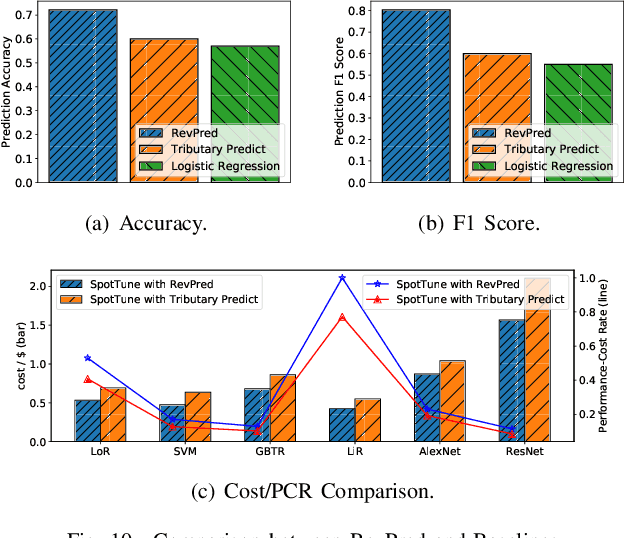
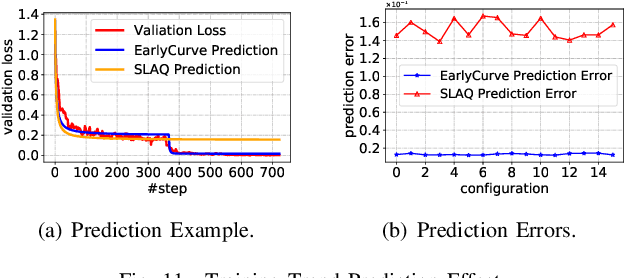
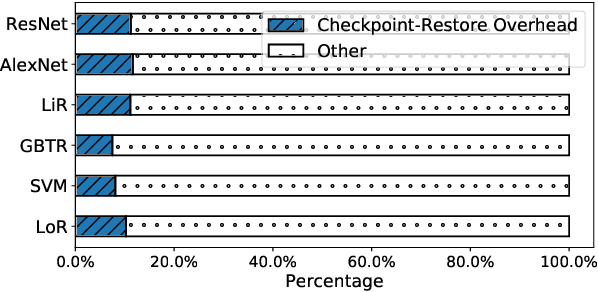
Hyper-parameter tuning (HPT) is crucial for many machine learning (ML) algorithms. But due to the large searching space, HPT is usually time-consuming and resource-intensive. Nowadays, many researchers use public cloud resources to train machine learning models, convenient yet expensive. How to speed up the HPT process while at the same time reduce cost is very important for cloud ML users. In this paper, we propose SpotTune, an approach that exploits transient revocable resources in the public cloud with some tailored strategies to do HPT in a parallel and cost-efficient manner. Orchestrating the HPT process upon transient servers, SpotTune uses two main techniques, fine-grained cost-aware resource provisioning, and ML training trend predicting, to reduce the monetary cost and runtime of HPT processes. Our evaluations show that SpotTune can reduce the cost by up to 90% and achieve a 16.61x performance-cost rate improvement.
S3ML: A Secure Serving System for Machine Learning Inference
Oct 13, 2020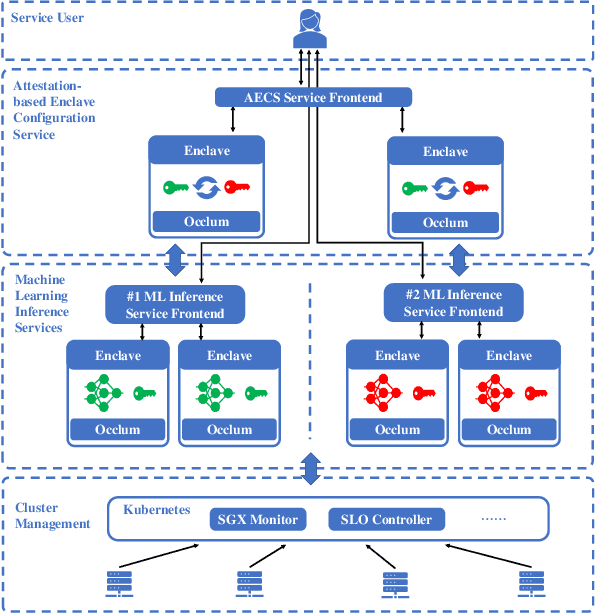
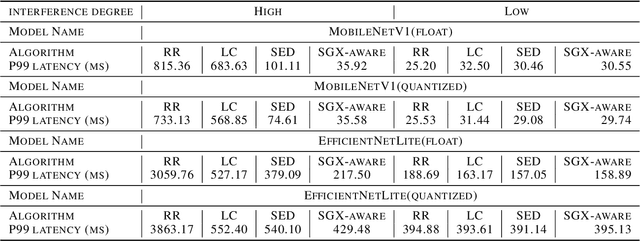
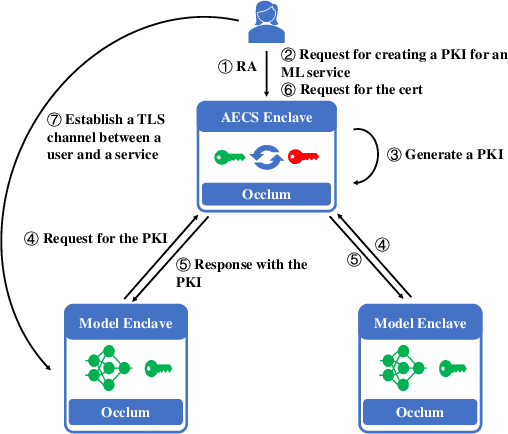
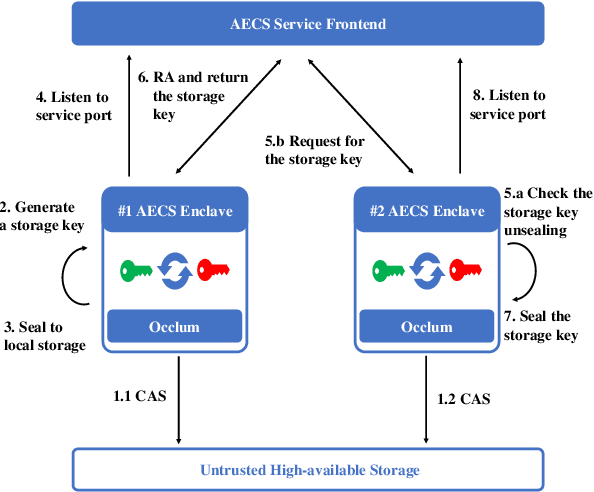
We present S3ML, a secure serving system for machine learning inference in this paper. S3ML runs machine learning models in Intel SGX enclaves to protect users' privacy. S3ML designs a secure key management service to construct flexible privacy-preserving server clusters and proposes novel SGX-aware load balancing and scaling methods to satisfy users' Service-Level Objectives. We have implemented S3ML based on Kubernetes as a low-overhead, high-available, and scalable system. We demonstrate the system performance and effectiveness of S3ML through extensive experiments on a series of widely-used models.