 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMark: Utility-Preserving Behavioral Watermarking for Agents
Jan 05, 2026LLM-based agents are increasingly deployed to autonomously solve complex tasks, raising urgent needs for IP protection and regulatory provenance. While content watermarking effectively attributes LLM-generated outputs, it fails to directly identify the high-level planning behaviors (e.g., tool and subgoal choices) that govern multi-step execution. Critically, watermarking at the planning-behavior layer faces unique challenges: minor distributional deviations in decision-making can compound during long-term agent operation, degrading utility, and many agents operate as black boxes that are difficult to intervene in directly. To bridge this gap, we propose AgentMark, a behavioral watermarking framework that embeds multi-bit identifiers into planning decisions while preserving utility. It operates by eliciting an explicit behavior distribution from the agent and applying distribution-preserving conditional sampling, enabling deployment under black-box APIs while remaining compatible with action-layer content watermarking. Experiments across embodied, tool-use, and social environments demonstrate practical multi-bit capacity, robust recovery from partial logs, and utility preservation. The code is available at https://github.com/Tooooa/AgentMark.
Beyond Detection: Exploring Evidence-based Multi-Agent Debate for Misinformation Intervention and Persuasion
Nov 10, 2025Multi-agent debate (MAD) frameworks have emerged as promising approaches for misinformation detection by simulating adversarial reasoning. While prior work has focused on detection accuracy, it overlooks the importance of helping users understand the reasoning behind factual judgments and develop future resilience. The debate transcripts generated during MAD offer a rich but underutilized resource for transparent reasoning. In this study, we introduce ED2D, an evidence-based MAD framework that extends previous approach by incorporating factual evidence retrieval. More importantly, ED2D is designed not only as a detection framework but also as a persuasive multi-agent system aimed at correcting user beliefs and discouraging misinformation sharing. We compare the persuasive effects of ED2D-generated debunking transcripts with those authored by human experts. Results demonstrate that ED2D outperforms existing baselines across three misinformation detection benchmarks. When ED2D generates correct predictions, its debunking transcripts exhibit persuasive effects comparable to those of human experts; However, when ED2D misclassifies, its accompanying explanations may inadvertently reinforce users'misconceptions, even when presented alongside accurate human explanations. Our findings highlight both the promise and the potential risks of deploying MAD systems for misinformation intervention. We further develop a public community website to help users explore ED2D, fostering transparency, critical thinking, and collaborative fact-checking.
Nimbus: Secure and Efficient Two-Party Inference for Transformers
Nov 24, 2024


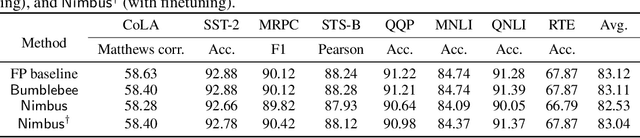
Transformer models have gained significant attention due to their power in machine learning tasks. Their extensive deployment has raised concerns about the potential leakage of sensitive information during inference. However, when being applied to Transformers, existing approaches based on secure two-party computation (2PC) bring about efficiency limitations in two folds: (1) resource-intensive matrix multiplications in linear layers, and (2) complex non-linear activation functions like $\mathsf{GELU}$ and $\mathsf{Softmax}$. This work presents a new two-party inference framework $\mathsf{Nimbus}$ for Transformer models. For the linear layer, we propose a new 2PC paradigm along with an encoding approach to securely compute matrix multiplications based on an outer-product insight, which achieves $2.9\times \sim 12.5\times$ performance improvements compared to the state-of-the-art (SOTA) protocol. For the non-linear layer, through a new observation of utilizing the input distribution, we propose an approach of low-degree polynomial approximation for $\mathsf{GELU}$ and $\mathsf{Softmax}$, which improves the performance of the SOTA polynomial approximation by $2.9\times \sim 4.0\times$, where the average accuracy loss of our approach is 0.08\% compared to the non-2PC inference without privacy. Compared with the SOTA two-party inference, $\mathsf{Nimbus}$ improves the end-to-end performance of \bert{} inference by $2.7\times \sim 4.7\times$ across different network settings.
Ditto: Quantization-aware Secure Inference of Transformers upon MPC
May 09, 2024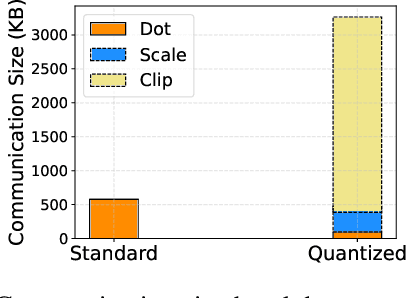
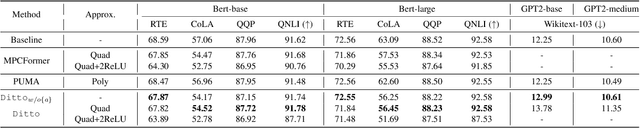
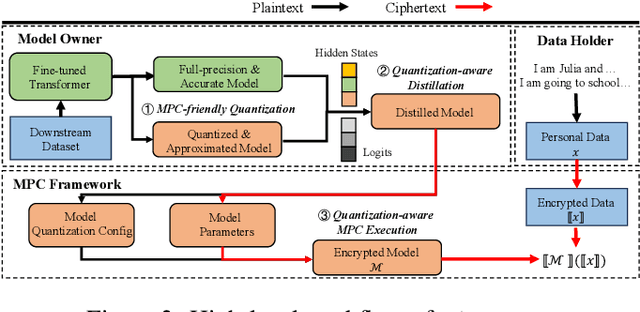
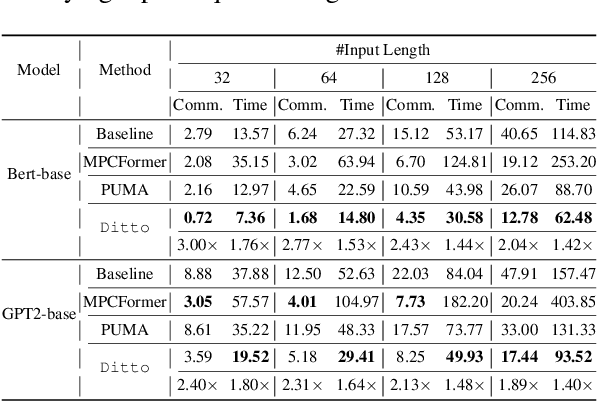
Due to the rising privacy concerns on sensitive client data and trained models like Transformers, secure multi-party computation (MPC) techniques are employed to enable secure inference despite attendant overhead. Existing works attempt to reduce the overhead using more MPC-friendly non-linear function approximations. However, the integration of quantization widely used in plaintext inference into the MPC domain remains unclear. To bridge this gap, we propose the framework named Ditto to enable more efficient quantization-aware secure Transformer inference. Concretely, we first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model utility. Then, we propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference. This approach significantly decreases both computation and communication overhead, leading to improvements in overall efficiency. We conduct extensive experiments on Bert and GPT2 models to evaluate the performance of Ditto. The results demonstrate that Ditto is about $3.14\sim 4.40\times$ faster than MPCFormer (ICLR 2023) and $1.44\sim 2.35\times$ faster than the state-of-the-art work PUMA with negligible utility degradation.
MPCViT: Searching for MPC-friendly Vision Transformer with Heterogeneous Attention
Nov 25, 2022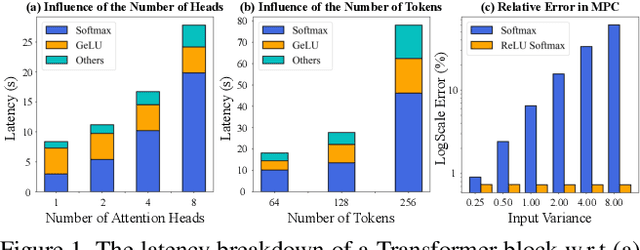

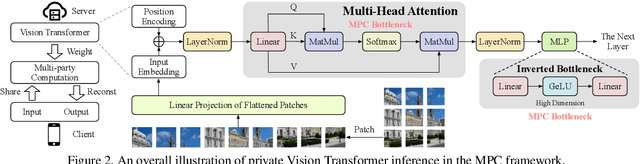
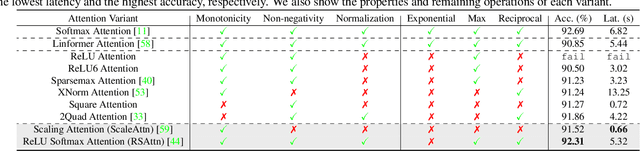
Secure multi-party computation (MPC) enables computation directly on encrypted data on non-colluding untrusted servers and protects both data and model privacy in deep learning inference. However, existing neural network (NN) architectures, including Vision Transformers (ViTs), are not designed or optimized for MPC protocols and incur significant latency overhead due to the Softmax function in the multi-head attention (MHA). In this paper, we propose an MPC-friendly ViT, dubbed MPCViT, to enable accurate yet efficient ViT inference in MPC. We systematically compare different attention variants in MPC and propose a heterogeneous attention search space, which combines the high-accuracy and MPC-efficient attentions with diverse structure granularities. We further propose a simple yet effective differentiable neural architecture search (NAS) algorithm for fast ViT optimization. MPCViT significantly outperforms prior-art ViT variants in MPC. With the proposed NAS algorithm, our extensive experiments demonstrate that MPCViT achieves 7.9x and 2.8x latency reduction with better accuracy compared to Linformer and MPCFormer on the Tiny-ImageNet dataset, respectively. Further, with proper knowledge distillation (KD), MPCViT even achieves 1.9% better accuracy compared to the baseline ViT with 9.9x latency reduction on the Tiny-ImageNet dataset.
When Homomorphic Encryption Marries Secret Sharing: Secure Large-Scale Sparse Logistic Regression and Applications in Risk Control
Aug 20, 2020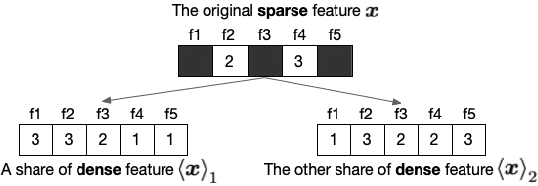
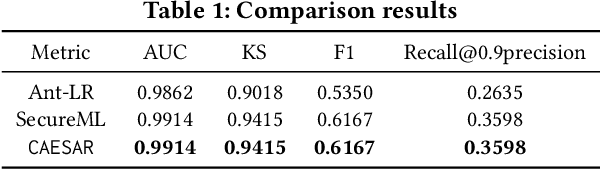
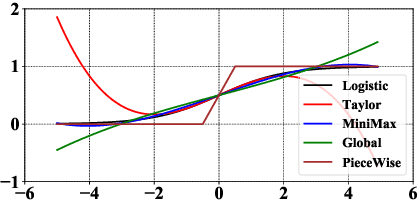

Logistic Regression (LR) is the most widely used machine learning model in industry due to its efficiency, robustness, and interpretability. Meanwhile, with the problem of data isolation and the requirement of high model performance, building secure and efficient LR model for multi-parties becomes a hot topic for both academia and industry. Existing works mainly employ either Homomorphic Encryption (HE) or Secret Sharing (SS) to build secure LR. HE based methods can deal with high-dimensional sparse features, but they may suffer potential security risk. In contrast, SS based methods have provable security but they have efficiency issue under high-dimensional sparse features. In this paper, we first present CAESAR, which combines HE and SS to build seCure lArge-scalE SpArse logistic Regression model and thus has the advantages of both efficiency and security. We then present the distributed implementation of CAESAR for scalability requirement. We finally deploy CAESAR into a risk control task and conduct comprehensive experiments to study the efficiency of CAESAR.
A Hybrid-Domain Framework for Secure Gradient Tree Boosting
May 18, 2020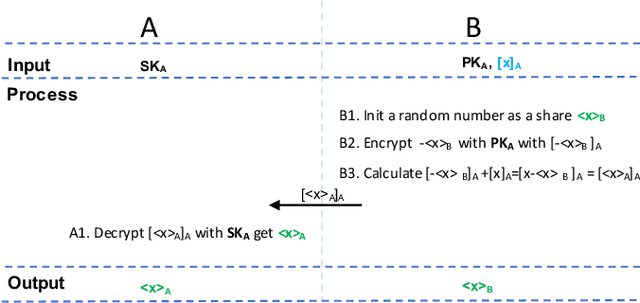
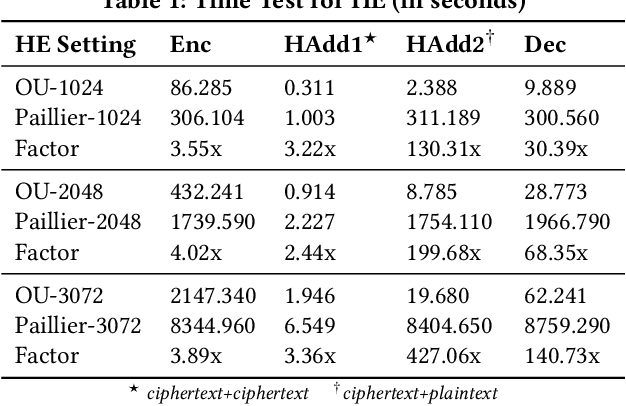
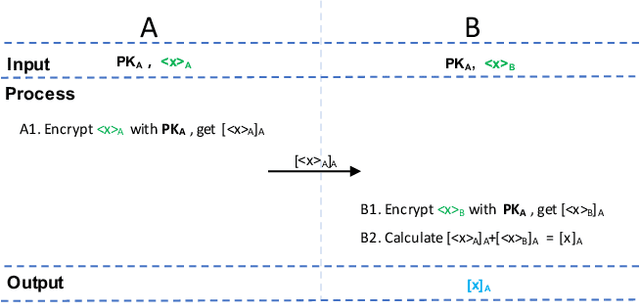
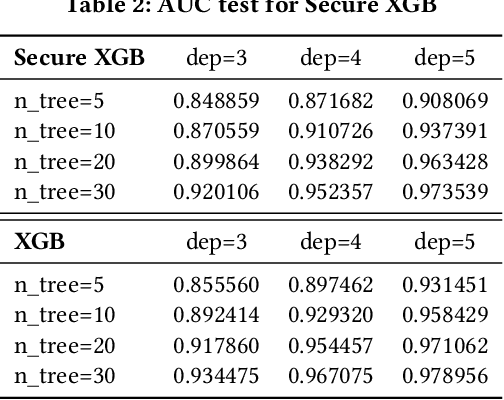
Gradient tree boosting (e.g. XGB) is one of the most widely usedmachine learning models in practice. How to build a secure XGB inface of data isolation problem becomes a hot research topic. However, existing works tend to leak intermediate information and thusraise potential privacy risk. In this paper, we propose a novel framework for two parties to build secure XGB with vertically partitioneddata. Specifically, we associate Homomorphic Encryption (HE) domain with Secret Sharing (SS) domain by providing the two-waytransformation primitives. The framework generally promotes theefficiency for privacy preserving machine learning and offers theflexibility to implement other machine learning models. Then weelaborate two secure XGB training algorithms as well as a corresponding prediction algorithm under the hybrid security domains.Next, we compare our proposed two training algorithms throughboth complexity analysis and experiments. Finally, we verify themodel performance on benchmark dataset and further apply ourwork to a real-world scenario.