 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI as a Teaching Partner: Early Lessons from Classroom Codesign with Secondary Teachers
Dec 12, 2025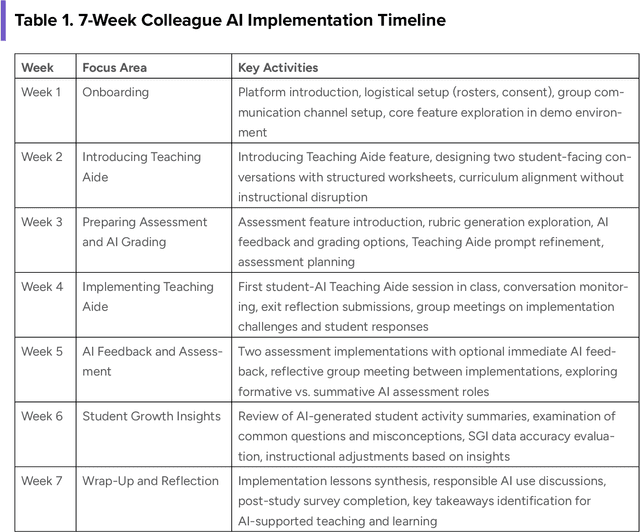

This report presents a comprehensive account of the Colleague AI Classroom pilot, a collaborative design (co-design) study that brought generative AI technology directly into real classrooms. In this study, AI functioned as a third agent, an active participant that mediated feedback, supported inquiry, and extended teachers' instructional reach while preserving human judgment and teacher authority. Over seven weeks in spring 2025, 21 in-service teachers from four Washington State public school districts and one independent school integrated four AI-powered features of the Colleague AI Classroom into their instruction: Teaching Aide, Assessment and AI Grading, AI Tutor, and Student Growth Insights. More than 600 students in grades 6-12 used the platform in class at the direction of their teachers, who designed and facilitated the AI activities. During the Classroom pilot, teachers were co-design partners: they planned activities, implemented them with students, and provided weekly reflections on AI's role in classroom settings. The teachers' feedback guided iterative improvements for Colleague AI. The research team captured rich data through surveys, planning and reflection forms, group meetings, one-on-one interviews, and platform usage logs to understand where AI adds instructional value and where it requires refinement.
RAGRank: Using PageRank to Counter Poisoning in CTI LLM Pipelines
Oct 23, 2025



Retrieval-Augmented Generation (RAG) has emerged as the dominant architectural pattern to operationalize Large Language Model (LLM) usage in Cyber Threat Intelligence (CTI) systems. However, this design is susceptible to poisoning attacks, and previously proposed defenses can fail for CTI contexts as cyber threat information is often completely new for emerging attacks, and sophisticated threat actors can mimic legitimate formats, terminology, and stylistic conventions. To address this issue, we propose that the robustness of modern RAG defenses can be accelerated by applying source credibility algorithms on corpora, using PageRank as an example. In our experiments, we demonstrate quantitatively that our algorithm applies a lower authority score to malicious documents while promoting trusted content, using the standardized MS MARCO dataset. We also demonstrate proof-of-concept performance of our algorithm on CTI documents and feeds.
Decoding Instructional Dialogue: Human-AI Collaborative Analysis of Teacher Use of AI Tool at Scale
Jul 23, 2025The integration of large language models (LLMs) into educational tools has the potential to substantially impact how teachers plan instruction, support diverse learners, and engage in professional reflection. Yet little is known about how educators actually use these tools in practice and how their interactions with AI can be meaningfully studied at scale. This paper presents a human-AI collaborative methodology for large-scale qualitative analysis of over 140,000 educator-AI messages drawn from a generative AI platform used by K-12 teachers. Through a four-phase coding pipeline, we combined inductive theme discovery, codebook development, structured annotation, and model benchmarking to examine patterns of educator engagement and evaluate the performance of LLMs in qualitative coding tasks. We developed a hierarchical codebook aligned with established teacher evaluation frameworks, capturing educators' instructional goals, contextual needs, and pedagogical strategies. Our findings demonstrate that LLMs, particularly Claude 3.5 Haiku, can reliably support theme identification, extend human recognition in complex scenarios, and outperform open-weight models in both accuracy and structural reliability. The analysis also reveals substantive patterns in how educators inquire AI to enhance instructional practices (79.7 percent of total conversations), create or adapt content (76.1 percent), support assessment and feedback loop (46.9 percent), attend to student needs for tailored instruction (43.3 percent), and assist other professional responsibilities (34.2 percent), highlighting emerging AI-related competencies that have direct implications for teacher preparation and professional development. This study offers a scalable, transparent model for AI-augmented qualitative research and provides foundational insights into the evolving role of generative AI in educational practice.
Enhancing Instructional Quality: Leveraging Computer-Assisted Textual Analysis to Generate In-Depth Insights from Educational Artifacts
Mar 06, 2024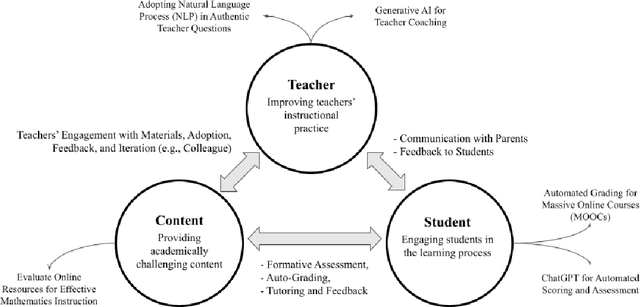
This paper explores the transformative potential of computer-assisted textual analysis in enhancing instructional quality through in-depth insights from educational artifacts. We integrate Richard Elmore's Instructional Core Framework to examine how artificial intelligence (AI) and machine learning (ML) methods, particularly natural language processing (NLP), can analyze educational content, teacher discourse, and student responses to foster instructional improvement. Through a comprehensive review and case studies within the Instructional Core Framework, we identify key areas where AI/ML integration offers significant advantages, including teacher coaching, student support, and content development. We unveil patterns that indicate AI/ML not only streamlines administrative tasks but also introduces novel pathways for personalized learning, providing actionable feedback for educators and contributing to a richer understanding of instructional dynamics. This paper emphasizes the importance of aligning AI/ML technologies with pedagogical goals to realize their full potential in educational settings, advocating for a balanced approach that considers ethical considerations, data quality, and the integration of human expertise.
From Voices to Validity: Leveraging Large Language Models (LLMs) for Textual Analysis of Policy Stakeholder Interviews
Dec 02, 2023
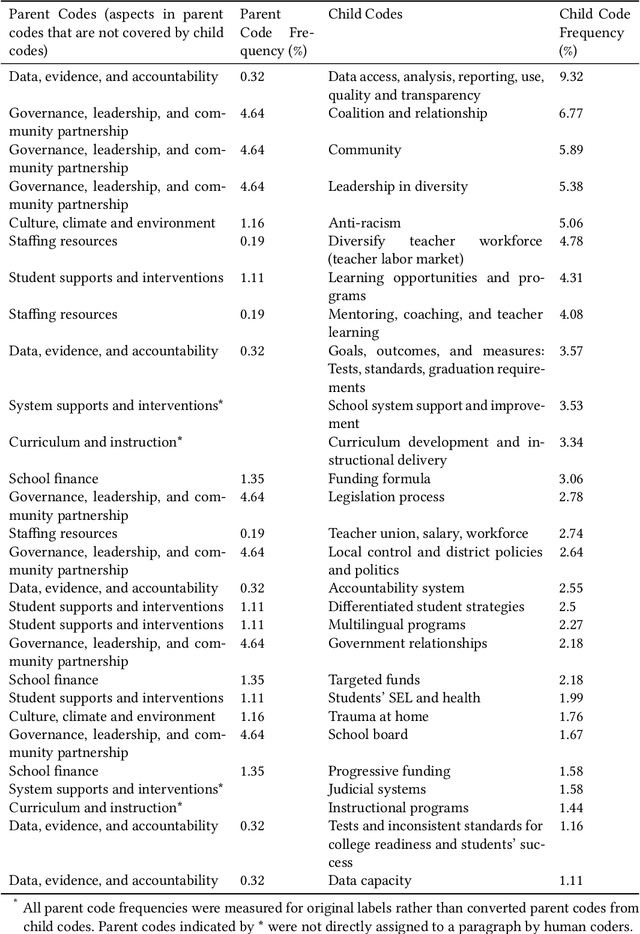

Obtaining stakeholders' diverse experiences and opinions about current policy in a timely manner is crucial for policymakers to identify strengths and gaps in resource allocation, thereby supporting effective policy design and implementation. However, manually coding even moderately sized interview texts or open-ended survey responses from stakeholders can often be labor-intensive and time-consuming. This study explores the integration of Large Language Models (LLMs)--like GPT-4--with human expertise to enhance text analysis of stakeholder interviews regarding K-12 education policy within one U.S. state. Employing a mixed-methods approach, human experts developed a codebook and coding processes as informed by domain knowledge and unsupervised topic modeling results. They then designed prompts to guide GPT-4 analysis and iteratively evaluate different prompts' performances. This combined human-computer method enabled nuanced thematic and sentiment analysis. Results reveal that while GPT-4 thematic coding aligned with human coding by 77.89% at specific themes, expanding to broader themes increased congruence to 96.02%, surpassing traditional Natural Language Processing (NLP) methods by over 25%. Additionally, GPT-4 is more closely matched to expert sentiment analysis than lexicon-based methods. Findings from quantitative measures and qualitative reviews underscore the complementary roles of human domain expertise and automated analysis as LLMs offer new perspectives and coding consistency. The human-computer interactive approach enhances efficiency, validity, and interpretability of educational policy research.
Model Predictive Control for Aggressive Driving Over Uneven Terrain
Nov 21, 2023



Terrain traversability in off-road autonomy has traditionally relied on semantic classification or resource-intensive dynamics models to capture vehicle-terrain interactions. However, our experiences in the development of a high-speed off-road platform have revealed several critical challenges that are not adequately addressed by current methods at our operating speeds of 7--10 m/s. This study focuses particularly on uneven terrain geometries such as hills, banks, and ditches. These common high-risk geometries are capable of disabling the vehicle and causing severe passenger injuries if poorly traversed. We introduce a physics-based framework for identifying traversability constraints on terrain dynamics. Using this framework, we then derive two fundamental constraints, with a primary focus on mitigating rollover and ditch-crossing failures. In addition, we present the design of our planning and control system, which uses Model Predictive Control (MPC) and a low-level controller to enable the fast and efficient computation of these constraints to meet the demands of our aggressive driving. Through real-world experimentation and traversal of hills and ditches, our approach is tested and benchmarked against a human expert. These results demonstrate that our approach captures fundamental elements of safe and aggressive control on these terrain features.
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
Oct 17, 2022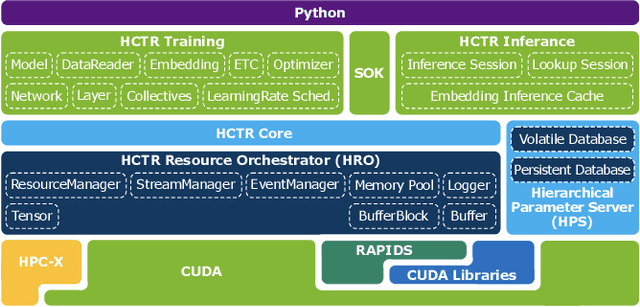
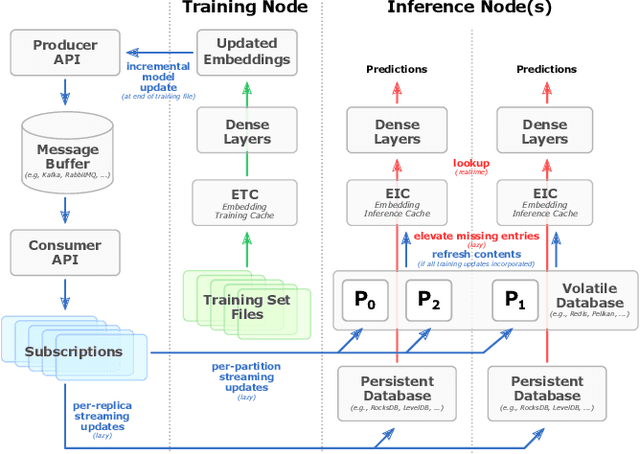
In this talk, we introduce Merlin HugeCTR. Merlin HugeCTR is an open source, GPU-accelerated integration framework for click-through rate estimation. It optimizes both training and inference, whilst enabling model training at scale with model-parallel embeddings and data-parallel neural networks. In particular, Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. In the MLPerf v1.0 DLRM model training benchmark, Merlin HugeCTR achieves a speedup of up to 24.6x on a single DGX A100 (8x A100) over PyTorch on 4x4-socket CPU nodes (4x4x28 cores). Merlin HugeCTR can also take advantage of multi-node environments to accelerate training even further. Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference. Using this HPS, Merlin HugeCTR users can achieve a 5~62x speedup (batch size dependent) for popular recommendation models over CPU baseline implementations, and dramatically reduce their end-to-end inference latency.
* 4 pages
Regularized Graph Structure Learning with Semantic Knowledge for Multi-variates Time-Series Forecasting
Oct 12, 2022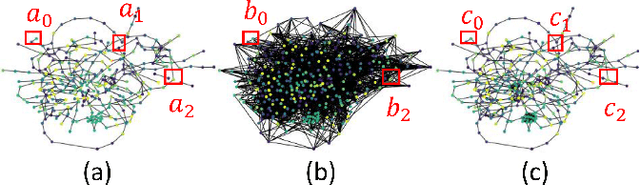
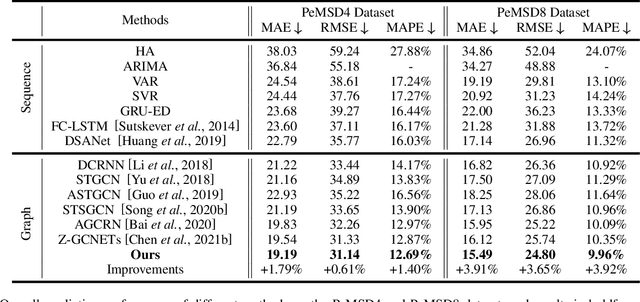
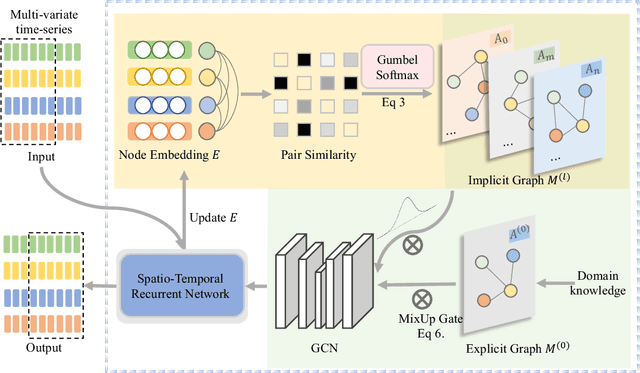
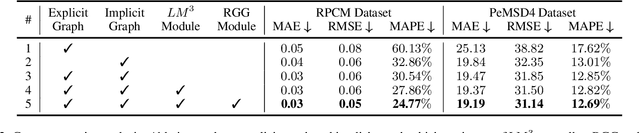
Multivariate time-series forecasting is a critical task for many applications, and graph time-series network is widely studied due to its capability to capture the spatial-temporal correlation simultaneously. However, most existing works focus more on learning with the explicit prior graph structure, while ignoring potential information from the implicit graph structure, yielding incomplete structure modeling. Some recent works attempt to learn the intrinsic or implicit graph structure directly while lacking a way to combine explicit prior structure with implicit structure together. In this paper, we propose Regularized Graph Structure Learning (RGSL) model to incorporate both explicit prior structure and implicit structure together, and learn the forecasting deep networks along with the graph structure. RGSL consists of two innovative modules. First, we derive an implicit dense similarity matrix through node embedding, and learn the sparse graph structure using the Regularized Graph Generation (RGG) based on the Gumbel Softmax trick. Second, we propose a Laplacian Matrix Mixed-up Module (LM3) to fuse the explicit graph and implicit graph together. We conduct experiments on three real-word datasets. Results show that the proposed RGSL model outperforms existing graph forecasting algorithms with a notable margin, while learning meaningful graph structure simultaneously. Our code and models are made publicly available at https://github.com/alipay/RGSL.git.
Measuring and Clustering Network Attackers using Medium-Interaction Honeypots
Jun 27, 2022
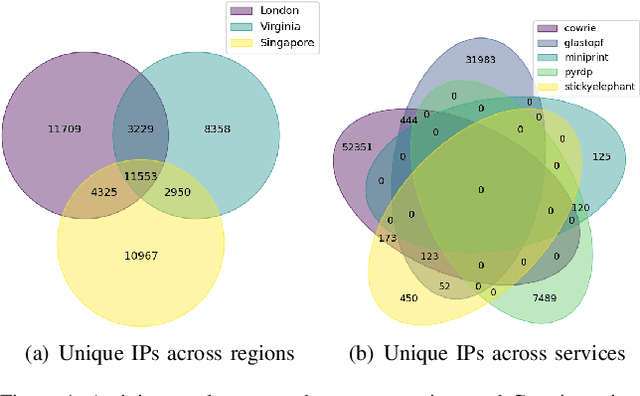
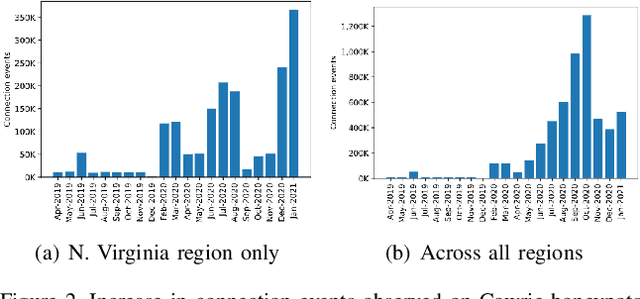
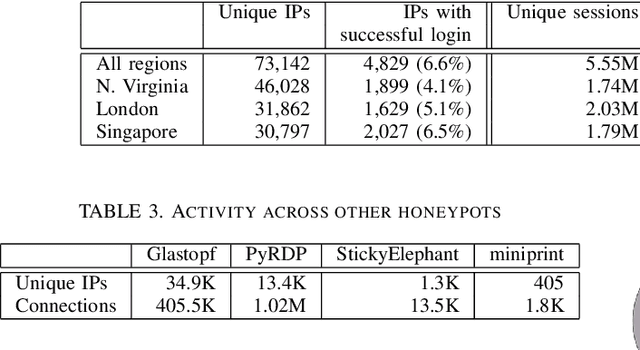
Network honeypots are often used by information security teams to measure the threat landscape in order to secure their networks. With the advancement of honeypot development, today's medium-interaction honeypots provide a way for security teams and researchers to deploy these active defense tools that require little maintenance on a variety of protocols. In this work, we deploy such honeypots on five different protocols on the public Internet and study the intent and sophistication of the attacks we observe. We then use the information gained to develop a clustering approach that identifies correlations in attacker behavior to discover IPs that are highly likely to be controlled by a single operator, illustrating the advantage of using these honeypots for data collection.
Sparse deep computer-generated holography for optical microscopy
Dec 12, 2021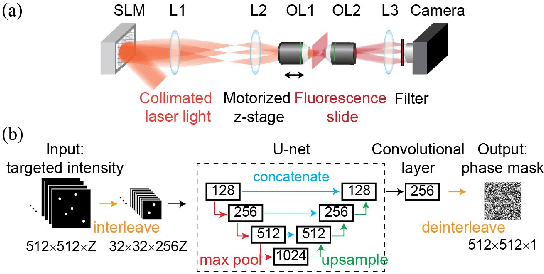



Computer-generated holography (CGH) has broad applications such as direct-view display, virtual and augmented reality, as well as optical microscopy. CGH usually utilizes a spatial light modulator that displays a computer-generated phase mask, modulating the phase of coherent light in order to generate customized patterns. The algorithm that computes the phase mask is the core of CGH and is usually tailored to meet different applications. CGH for optical microscopy usually requires 3D accessibility (i.e., generating overlapping patterns along the $z$-axis) and micron-scale spatial precision. Here, we propose a CGH algorithm using an unsupervised generative model designed for optical microscopy to synthesize 3D selected illumination. The algorithm, named sparse deep CGH, is able to generate sparsely distributed points in a large 3D volume with higher contrast than conventional CGH algorithms.