 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchicalKV: A GPU Hash Table with Cache Semantics for Continuous Online Embedding Storage
Mar 17, 2026Traditional GPU hash tables preserve every inserted key -- a dictionary assumption that wastes scarce High Bandwidth Memory (HBM) when embedding tables routinely exceed single-GPU capacity. We challenge this assumption with cache semantics, where policy-driven eviction is a first-class operation. We introduce HierarchicalKV (HKV), the first general-purpose GPU hash table library whose normal full-capacity operating contract is cache-semantic: each full-bucket upsert (update-or-insert) is resolved in place by eviction or admission rejection rather than by rehashing or capacity-induced failure. HKV co-designs four core mechanisms -- cache-line-aligned buckets, in-line score-driven upsert, score-based dynamic dual-bucket selection, and triple-group concurrency -- and uses tiered key-value separation as a scaling enabler beyond HBM. On an NVIDIA H100 NVL GPU, HKV achieves up to 3.9 billion key-value pairs per second (B-KV/s) find throughput, stable across load factors 0.50-1.00 (<5% variation), and delivers 1.4x higher find throughput than WarpCore (the strongest dictionary-semantic GPU baseline at lambda=0.50) and up to 2.6-9.4x over indirection-based GPU baselines. Since its open-source release in October 2022, HKV has been integrated into multiple open-source recommendation frameworks.
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
Oct 17, 2022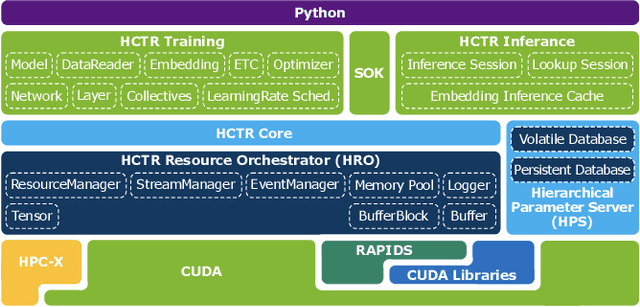
In this talk, we introduce Merlin HugeCTR. Merlin HugeCTR is an open source, GPU-accelerated integration framework for click-through rate estimation. It optimizes both training and inference, whilst enabling model training at scale with model-parallel embeddings and data-parallel neural networks. In particular, Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. In the MLPerf v1.0 DLRM model training benchmark, Merlin HugeCTR achieves a speedup of up to 24.6x on a single DGX A100 (8x A100) over PyTorch on 4x4-socket CPU nodes (4x4x28 cores). Merlin HugeCTR can also take advantage of multi-node environments to accelerate training even further. Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference. Using this HPS, Merlin HugeCTR users can achieve a 5~62x speedup (batch size dependent) for popular recommendation models over CPU baseline implementations, and dramatically reduce their end-to-end inference latency.
* 4 pages
A GPU-specialized Inference Parameter Server for Large-Scale Deep Recommendation Models
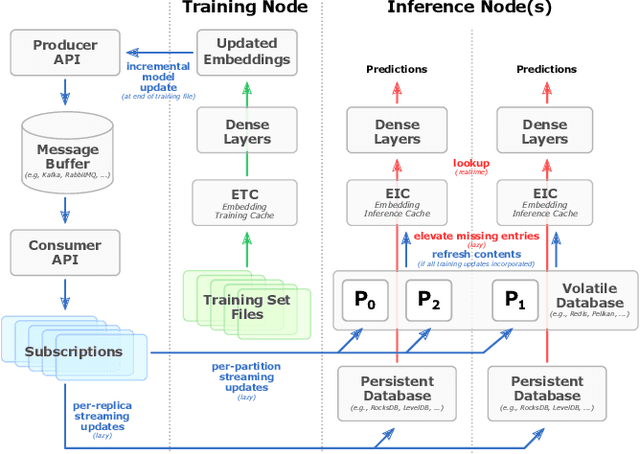
Oct 17, 2022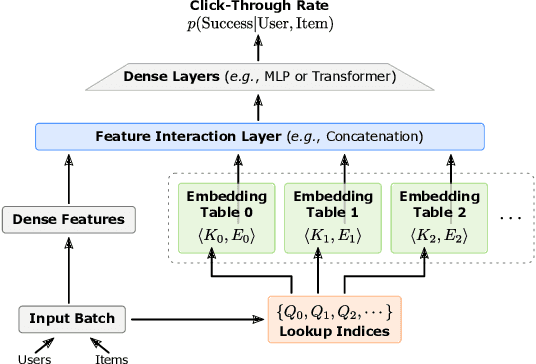
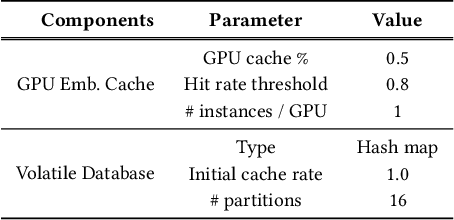
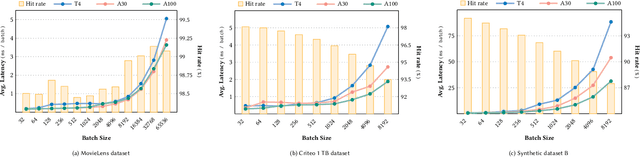
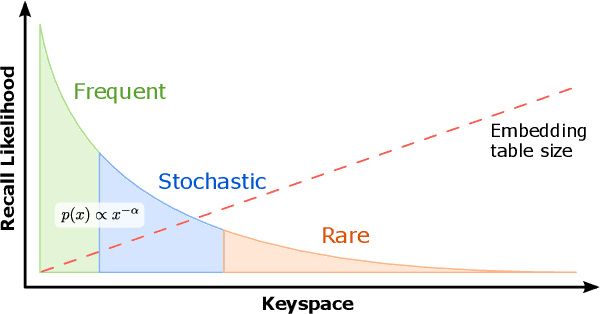
Recommendation systems are of crucial importance for a variety of modern apps and web services, such as news feeds, social networks, e-commerce, search, etc. To achieve peak prediction accuracy, modern recommendation models combine deep learning with terabyte-scale embedding tables to obtain a fine-grained representation of the underlying data. Traditional inference serving architectures require deploying the whole model to standalone servers, which is infeasible at such massive scale. In this paper, we provide insights into the intriguing and challenging inference domain of online recommendation systems. We propose the HugeCTR Hierarchical Parameter Server (HPS), an industry-leading distributed recommendation inference framework, that combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. Among other things, HPS features (1) a redundant hierarchical storage system, (2) a novel high-bandwidth cache to accelerate parallel embedding lookup on NVIDIA GPUs, (3) online training support and (4) light-weight APIs for easy integration into existing large-scale recommendation workflows. To demonstrate its capabilities, we conduct extensive studies using both synthetically engineered and public datasets. We show that our HPS can dramatically reduce end-to-end inference latency, achieving 5~62x speedup (depending on the batch size) over CPU baseline implementations for popular recommendation models. Through multi-GPU concurrent deployment, the HPS can also greatly increase the inference QPS.
* 12 pages
Distributed Training of Deep Learning Models: A Taxonomic Perspective
Jul 08, 2020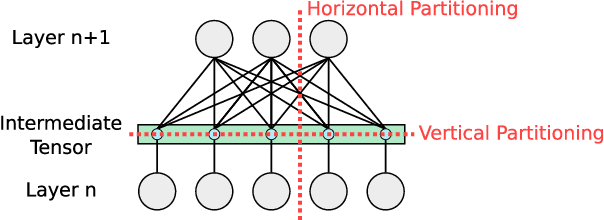
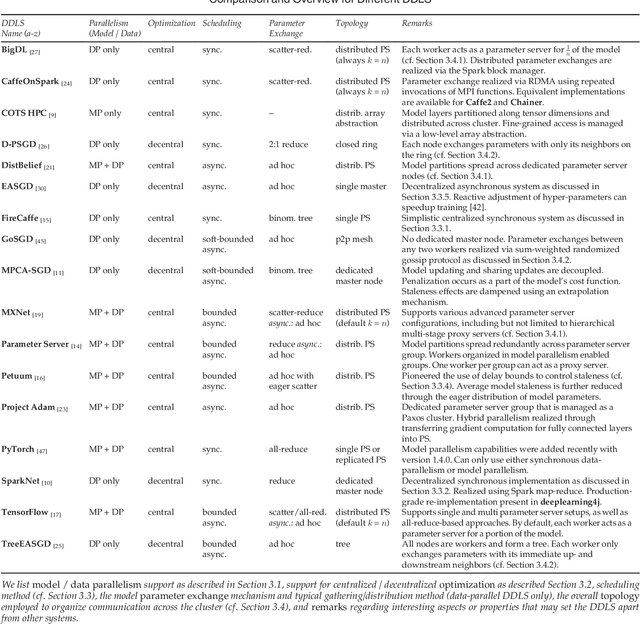
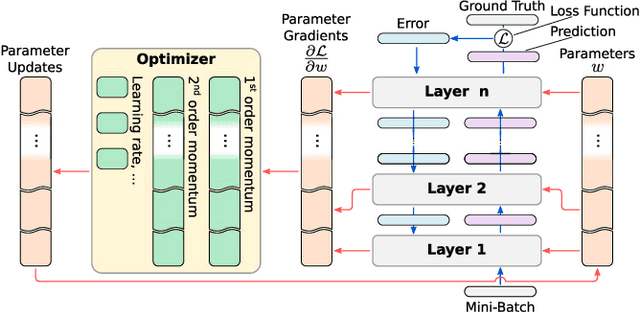
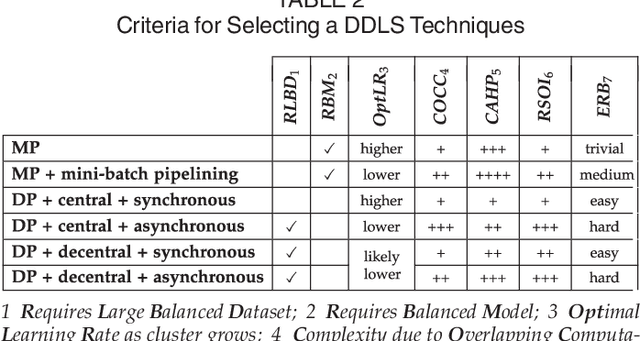
Distributed deep learning systems (DDLS) train deep neural network models by utilizing the distributed resources of a cluster. Developers of DDLS are required to make many decisions to process their particular workloads in their chosen environment efficiently. The advent of GPU-based deep learning, the ever-increasing size of datasets and deep neural network models, in combination with the bandwidth constraints that exist in cluster environments require developers of DDLS to be innovative in order to train high quality models quickly. Comparing DDLS side-by-side is difficult due to their extensive feature lists and architectural deviations. We aim to shine some light on the fundamental principles that are at work when training deep neural networks in a cluster of independent machines by analyzing the general properties associated with training deep learning models and how such workloads can be distributed in a cluster to achieve collaborative model training. Thereby we provide an overview of the different techniques that are used by contemporary DDLS and discuss their influence and implications on the training process. To conceptualize and compare DDLS, we group different techniques into categories, thus establishing a taxonomy of distributed deep learning systems.