 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
A GPU-specialized Inference Parameter Server for Large-Scale Deep Recommendation Models
Oct 17, 2022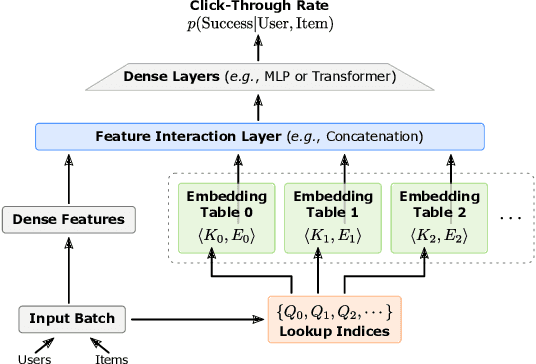
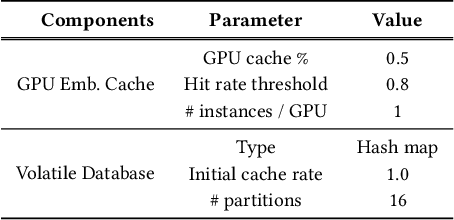
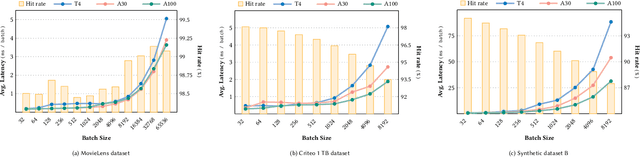
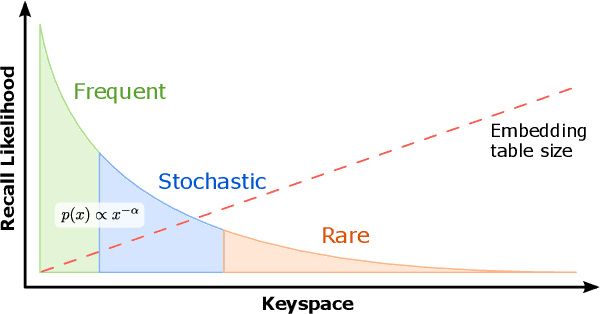
Recommendation systems are of crucial importance for a variety of modern apps and web services, such as news feeds, social networks, e-commerce, search, etc. To achieve peak prediction accuracy, modern recommendation models combine deep learning with terabyte-scale embedding tables to obtain a fine-grained representation of the underlying data. Traditional inference serving architectures require deploying the whole model to standalone servers, which is infeasible at such massive scale. In this paper, we provide insights into the intriguing and challenging inference domain of online recommendation systems. We propose the HugeCTR Hierarchical Parameter Server (HPS), an industry-leading distributed recommendation inference framework, that combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. Among other things, HPS features (1) a redundant hierarchical storage system, (2) a novel high-bandwidth cache to accelerate parallel embedding lookup on NVIDIA GPUs, (3) online training support and (4) light-weight APIs for easy integration into existing large-scale recommendation workflows. To demonstrate its capabilities, we conduct extensive studies using both synthetically engineered and public datasets. We show that our HPS can dramatically reduce end-to-end inference latency, achieving 5~62x speedup (depending on the batch size) over CPU baseline implementations for popular recommendation models. Through multi-GPU concurrent deployment, the HPS can also greatly increase the inference QPS.
* 12 pages
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
Oct 17, 2022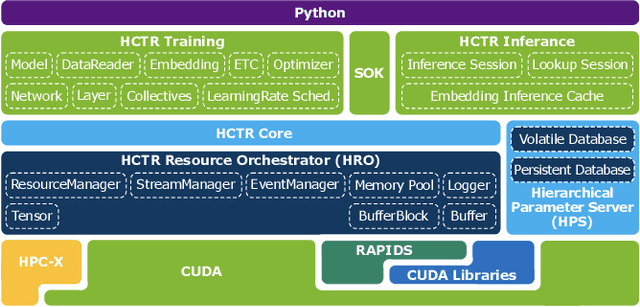
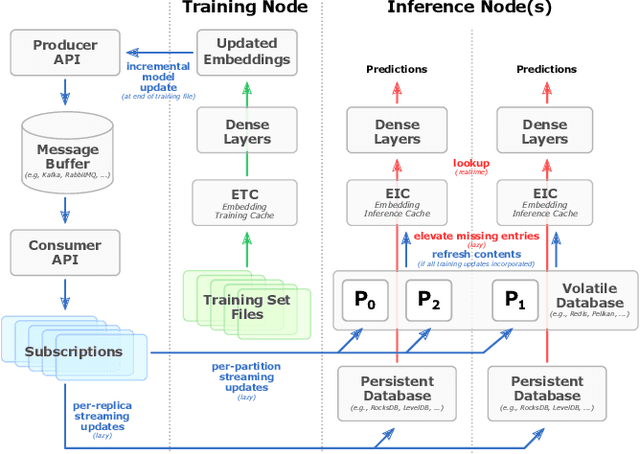
In this talk, we introduce Merlin HugeCTR. Merlin HugeCTR is an open source, GPU-accelerated integration framework for click-through rate estimation. It optimizes both training and inference, whilst enabling model training at scale with model-parallel embeddings and data-parallel neural networks. In particular, Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. In the MLPerf v1.0 DLRM model training benchmark, Merlin HugeCTR achieves a speedup of up to 24.6x on a single DGX A100 (8x A100) over PyTorch on 4x4-socket CPU nodes (4x4x28 cores). Merlin HugeCTR can also take advantage of multi-node environments to accelerate training even further. Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference. Using this HPS, Merlin HugeCTR users can achieve a 5~62x speedup (batch size dependent) for popular recommendation models over CPU baseline implementations, and dramatically reduce their end-to-end inference latency.
* 4 pages