 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
A GPU-specialized Inference Parameter Server for Large-Scale Deep Recommendation Models
Oct 17, 2022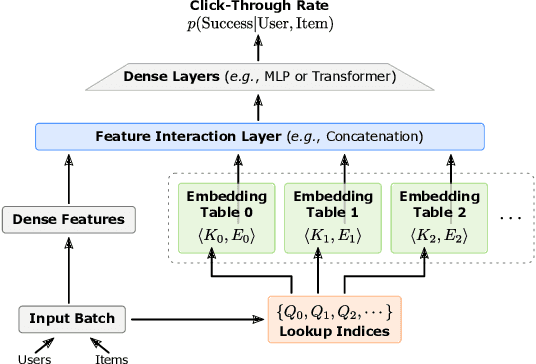
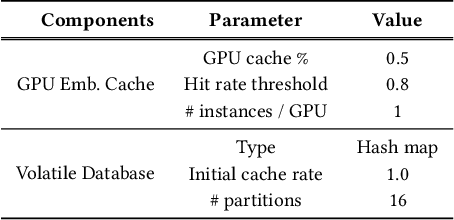
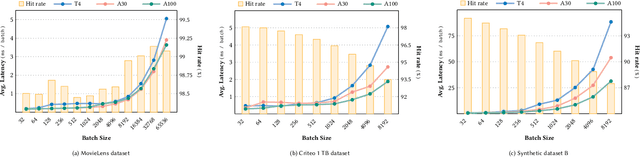
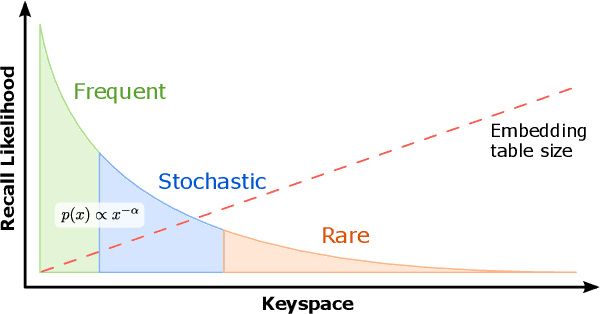
Recommendation systems are of crucial importance for a variety of modern apps and web services, such as news feeds, social networks, e-commerce, search, etc. To achieve peak prediction accuracy, modern recommendation models combine deep learning with terabyte-scale embedding tables to obtain a fine-grained representation of the underlying data. Traditional inference serving architectures require deploying the whole model to standalone servers, which is infeasible at such massive scale. In this paper, we provide insights into the intriguing and challenging inference domain of online recommendation systems. We propose the HugeCTR Hierarchical Parameter Server (HPS), an industry-leading distributed recommendation inference framework, that combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. Among other things, HPS features (1) a redundant hierarchical storage system, (2) a novel high-bandwidth cache to accelerate parallel embedding lookup on NVIDIA GPUs, (3) online training support and (4) light-weight APIs for easy integration into existing large-scale recommendation workflows. To demonstrate its capabilities, we conduct extensive studies using both synthetically engineered and public datasets. We show that our HPS can dramatically reduce end-to-end inference latency, achieving 5~62x speedup (depending on the batch size) over CPU baseline implementations for popular recommendation models. Through multi-GPU concurrent deployment, the HPS can also greatly increase the inference QPS.
* 12 pages
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
Oct 17, 2022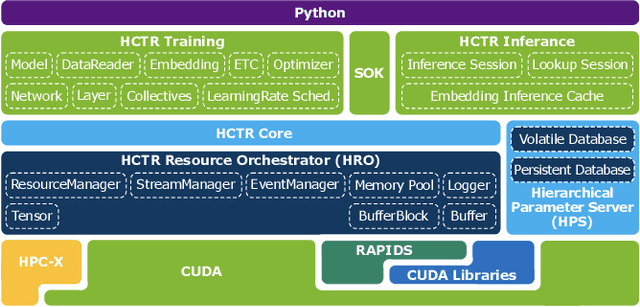
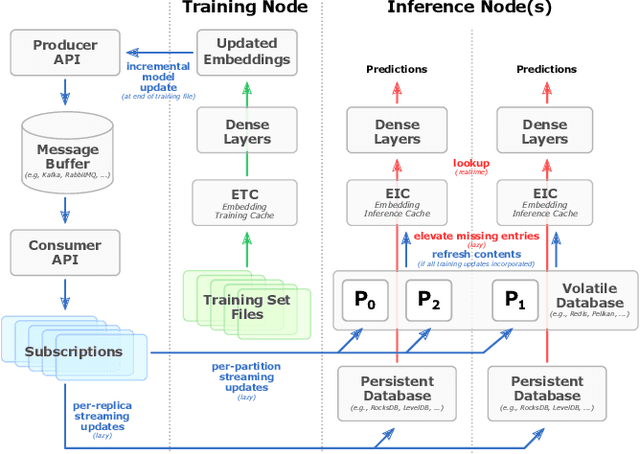
In this talk, we introduce Merlin HugeCTR. Merlin HugeCTR is an open source, GPU-accelerated integration framework for click-through rate estimation. It optimizes both training and inference, whilst enabling model training at scale with model-parallel embeddings and data-parallel neural networks. In particular, Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. In the MLPerf v1.0 DLRM model training benchmark, Merlin HugeCTR achieves a speedup of up to 24.6x on a single DGX A100 (8x A100) over PyTorch on 4x4-socket CPU nodes (4x4x28 cores). Merlin HugeCTR can also take advantage of multi-node environments to accelerate training even further. Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference. Using this HPS, Merlin HugeCTR users can achieve a 5~62x speedup (batch size dependent) for popular recommendation models over CPU baseline implementations, and dramatically reduce their end-to-end inference latency.
* 4 pages