 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning
Mar 25, 2026While proprietary systems such as Seedance-2.0 have achieved remarkable success in omni-capable video generation, open-source alternatives significantly lag behind. Most academic models remain heavily fragmented, and the few existing efforts toward unified video generation still struggle to seamlessly integrate diverse tasks within a single framework. To bridge this gap, we propose OmniWeaving, an omni-level video generation model featuring powerful multimodal composition and reasoning-informed capabilities. By leveraging a massive-scale pretraining dataset that encompasses diverse compositional and reasoning-augmented scenarios, OmniWeaving learns to temporally bind interleaved text, multi-image, and video inputs while acting as an intelligent agent to infer complex user intentions for sophisticated video creation. Furthermore, we introduce IntelligentVBench, the first comprehensive benchmark designed to rigorously assess next-level intelligent unified video generation. Extensive experiments demonstrate that OmniWeaving achieves SoTA performance among open-source unified models. The codes and model will be made publicly available soon. Project Page: https://omniweaving.github.io.
Manifold-Aware Exploration for Reinforcement Learning in Video Generation
Mar 23, 2026Group Relative Policy Optimization (GRPO) methods for video generation like FlowGRPO remain far less reliable than their counterparts for language models and images. This gap arises because video generation has a complex solution space, and the ODE-to-SDE conversion used for exploration can inject excess noise, lowering rollout quality and making reward estimates less reliable, which destabilizes post-training alignment. To address this problem, we view the pre-trained model as defining a valid video data manifold and formulate the core problem as constraining exploration within the vicinity of this manifold, ensuring that rollout quality is preserved and reward estimates remain reliable. We propose SAGE-GRPO (Stable Alignment via Exploration), which applies constraints at both micro and macro levels. At the micro level, we derive a precise manifold-aware SDE with a logarithmic curvature correction and introduce a gradient norm equalizer to stabilize sampling and updates across timesteps. At the macro level, we use a dual trust region with a periodic moving anchor and stepwise constraints so that the trust region tracks checkpoints that are closer to the manifold and limits long-horizon drift. We evaluate SAGE-GRPO on HunyuanVideo1.5 using the original VideoAlign as the reward model and observe consistent gains over previous methods in VQ, MQ, TA, and visual metrics (CLIPScore, PickScore), demonstrating superior performance in both reward maximization and overall video quality. The code and visual gallery are available at https://dungeonmassster.github.io/SAGE-GRPO-Page/.
IG-RFT: An Interaction-Guided RL Framework for VLA Models in Long-Horizon Robotic Manipulation
Feb 24, 2026Vision-Language-Action (VLA) models have demonstrated significant potential for generalist robotic policies; however, they struggle to generalize to long-horizon complex tasks in novel real-world domains due to distribution shifts and the scarcity of high-quality demonstrations. Although reinforcement learning (RL) offers a promising avenue for policy improvement, applying it to real-world VLA fine-tuning faces challenges regarding exploration efficiency, training stability, and sample cost. To address these issues, we propose IG-RFT, a novel Interaction-Guided Reinforced Fine-Tuning system designed for flow-based VLA models. Firstly, to facilitate effective policy optimization, we introduce Interaction-Guided Advantage Weighted Regression (IG-AWR), an RL algorithm that dynamically modulates exploration intensity based on the robot's interaction status. Furthermore, to address the limitations of sparse or task-specific rewards, we design a novel hybrid dense reward function that integrates the trajectory-level reward and the subtask-level reward. Finally, we construct a three-stage RL system comprising SFT, Offline RL, and Human-in-the-Loop RL for fine-tuning VLA models. Extensive real-world experiments on four challenging long-horizon tasks demonstrate that IG-RFT achieves an average success rate of 85.0%, significantly outperforming SFT (18.8%) and standard Offline RL baselines (40.0%). Ablation studies confirm the critical contributions of IG-AWR and hybrid reward shaping. In summary, our work establishes and validates a novel reinforced fine-tuning system for VLA models in real-world robotic manipulation.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025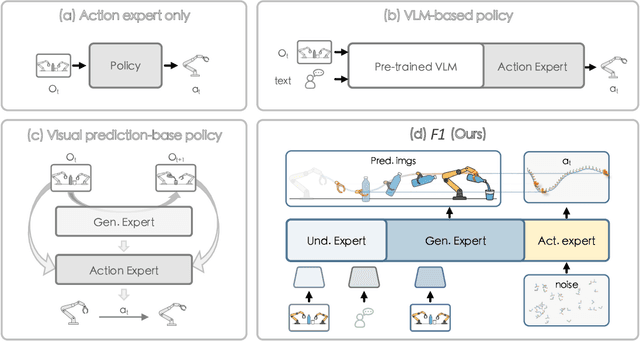

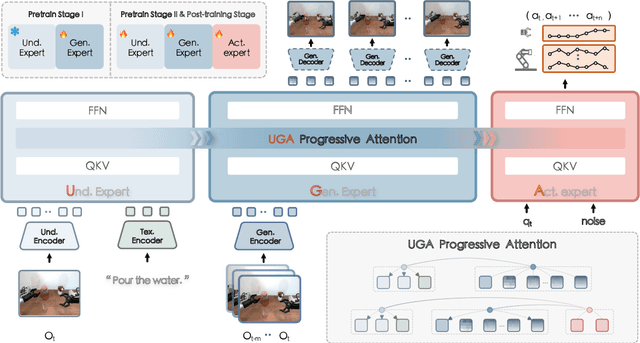

Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Global and Local Semantic Completion Learning for Vision-Language Pre-training
Jun 12, 2023
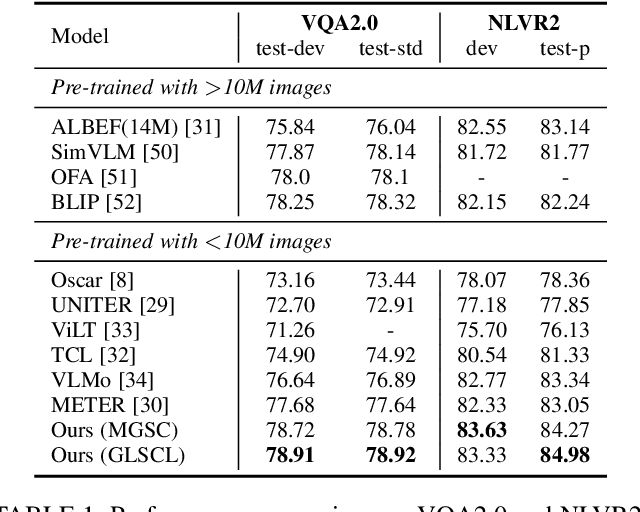
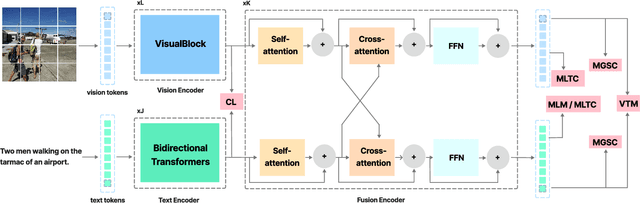
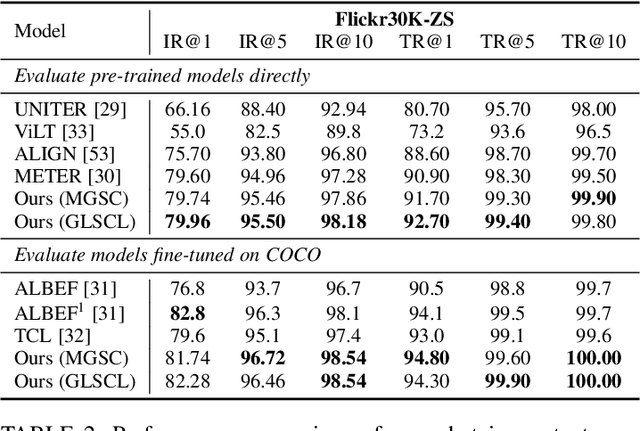
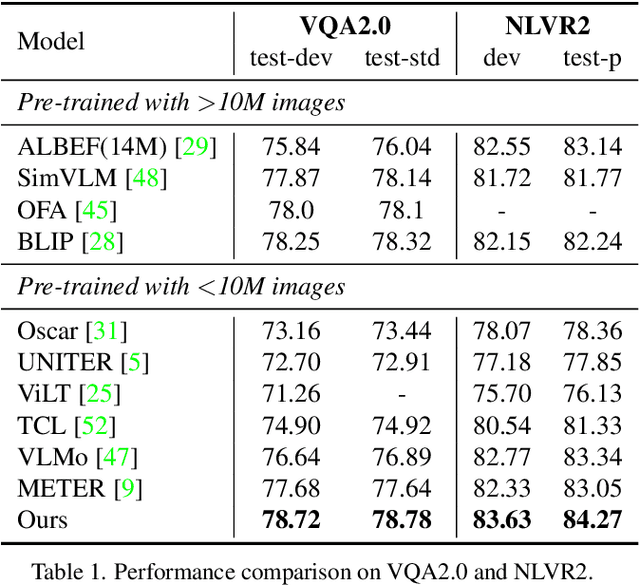
Cross-modal alignment plays a crucial role in vision-language pre-training (VLP) models, enabling them to capture meaningful associations across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-local alignment, i.e., associations between image patches and text tokens. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in a limited cross-modal alignment ability of global representations to local features of the other modality. Therefore, in this paper, we propose a novel Global and Local Semantic Completion Learning (GLSCL) task to facilitate global-local alignment and local-local alignment simultaneously. Specifically, the GLSCL task complements the missing semantics of masked data and recovers global and local features by cross-modal interactions. Our GLSCL consists of masked global semantic completion (MGSC) and masked local token completion (MLTC). MGSC promotes learning more representative global features which have a great impact on the performance of downstream tasks, and MLTC can further enhance accurate comprehension on multimodal data. Moreover, we present a flexible vision encoder, enabling our model to simultaneously perform image-text and video-text multimodal tasks. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Seeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022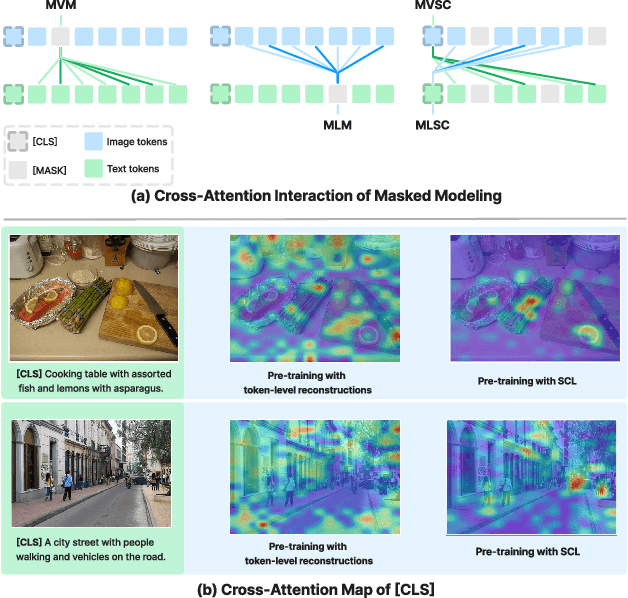
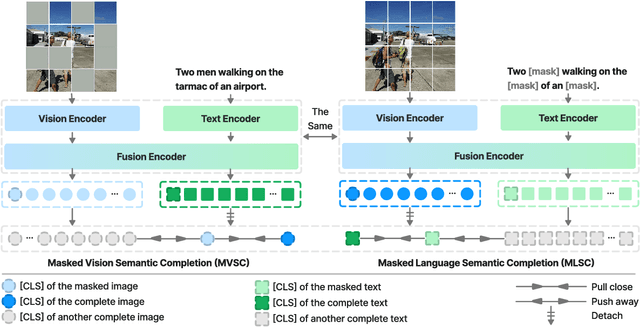
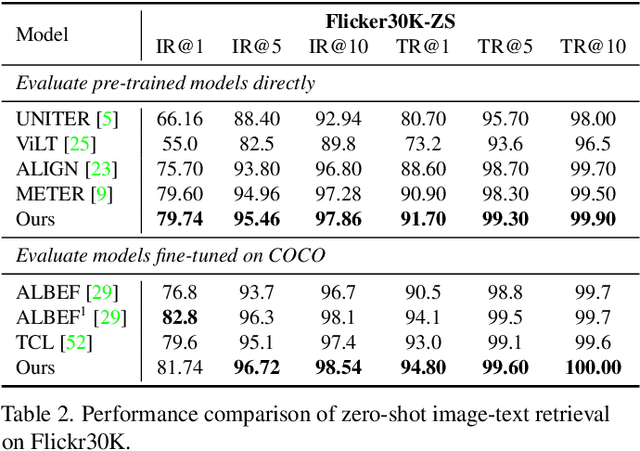
Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022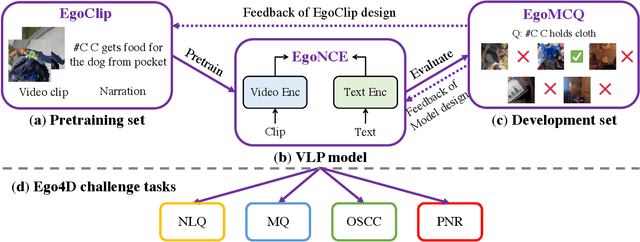
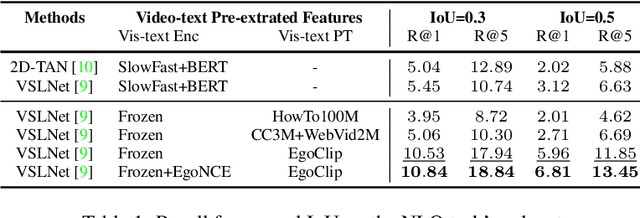
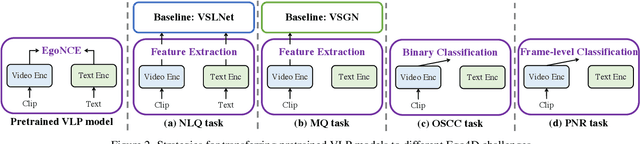
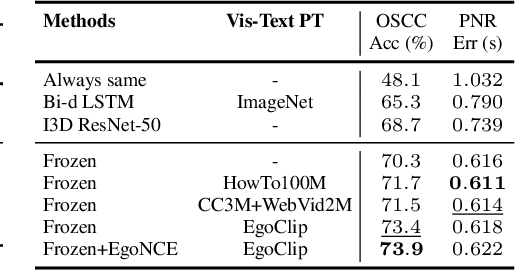
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining @ EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jul 04, 2022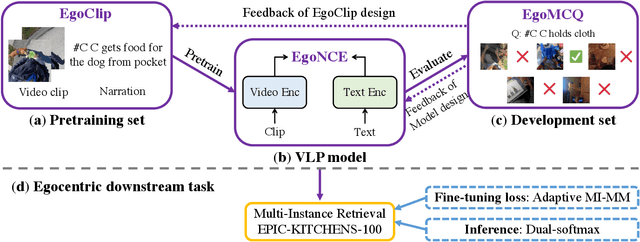
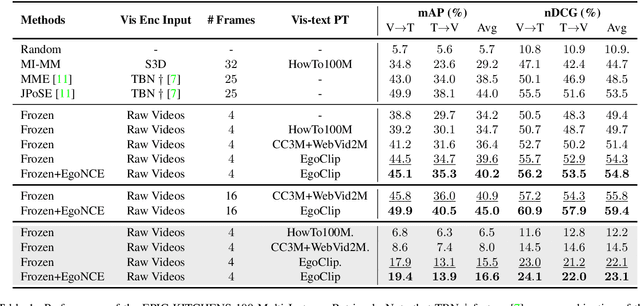
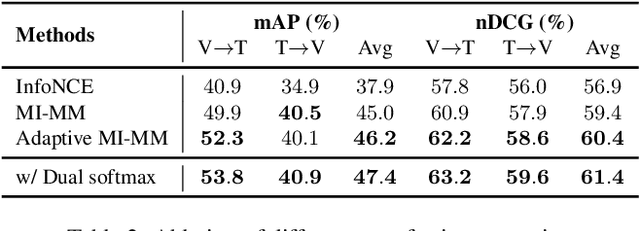
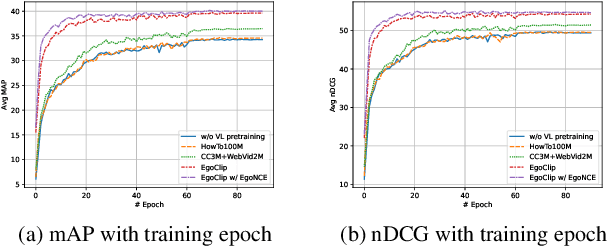
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for the EPIC-KITCHENS-100 Multi-Instance Retrieval (MIR) challenge. Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation to MIR benchmark. Furthermore, we devise an adaptive multi-instance max-margin loss to effectively fine-tune the model and equip the dual-softmax technique for reliable inference. Our best single model obtains strong performance on the challenge test set with 47.39% mAP and 61.44% nDCG. The code is available at https://github.com/showlab/EgoVLP.