 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Enhancing Negation Comprehension in Remote Sensing MLLMs
Jun 18, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable success in various Remote Sensing (RS) tasks. However, their ability to comprehend negation remains underexplored, limiting deployment in real-world applications where models must explicitly identify what is false or absent, e.g., emergency responders need to locate non-flooded routes for evacuation. To comprehensively study this limitation, we introduce RS-Neg, the first benchmark to evaluate negation understanding across region-level to scene-level tasks. Specifically, we design an automated data generation pipeline for RS imagery, using LLMs to synthesize diverse negation queries, and introduce a dynamic visual focus module for verification. Our evaluation reveals that advanced RS MLLMs struggle with negation, exhibiting hallucinations and substantial performance degradation. To close this gap, we propose NeFo, a novel test-time learning method that explicitly incorporates the logical role of negation into the model optimization. Remarkably, using about 5\% unlabeled test samples, NeFo significantly improves the negation understanding of models and shows strong generalization to unseen tasks. Code and data will be released upon acceptance.
TextGround4M: A Prompt-Aligned Dataset for Layout-Aware Text Rendering
Apr 27, 2026Despite recent advances in text-to-image generation, models still struggle to accurately render prompt-specified text with correct spatial layout -- especially in multi-span, structured settings. This challenge is driven not only by the lack of datasets that align prompts with the exact text and layout expected in the image, but also by the absence of effective metrics for evaluating layout quality. To address these issues, we introduce TextGround4M, a large-scale dataset of over 4 million prompt-image pairs, each annotated with span-level text grounded in the prompt and corresponding bounding boxes. This enables fine-grained supervision for layout-aware, prompt-grounded text rendering. Building on this, we propose a lightweight training strategy for autoregressive T2I models that appends layout-aware span tokens during training, without altering model architecture or inference behavior. We further construct a benchmark with stratified layout complexity to evaluate both open-source and proprietary models in a zero-shot setting. In addition, we introduce two layout-aware metrics to address the long-standing lack of spatial evaluation in text rendering. Our results show that models trained on TextGround4M outperform strong baselines in text fidelity, spatial accuracy, and prompt consistency, highlighting the importance of fine-grained layout supervision for grounded T2I generation.
* aaai poster; Project page: https://dongxingmao.github.io/TextGround4M.github.io/
CharTide: Data-Centric Chart-to-Code Generation via Tri-Perspective Tuning and Inquiry-Driven Evolution
Apr 24, 2026Chart-to-code generation demands strict visual precision and syntactic correctness from Vision-Language Models (VLMs). However, existing approaches are fundamentally constrained by data-centric limitations: despite the availability of growing chart-to-code datasets, simply scaling homogeneous chart-code pairs conflates visual perception with program logic, preventing models from fully leveraging the richness of multimodal supervision. We present CharTide, a novel data-centric framework that systematically redesigns both training and alignment data for chart-to-code generation. First, we construct a 2M-sample dataset via a Tri-Perspective Tuning strategy, explicitly decoupling training into visual perception, pure-text code logic, and modality fusion streams, enabling a 7B model to surpass specialized baselines using only supervised data. Second, we reformulate alignment as a data verification problem rather than a heuristic scoring task. To this end, we introduce an Inquiry-Driven RL framework grounded in the principle of information invariance: a downstream model should yield consistent answers to identical visual queries across both original and generated charts. Moving beyond rigid rule matching or VLM scoring, we employ a frozen Inspector to objectively verify generated charts through atomic QA tasks, providing verifiable reward signals based on answer accuracy. Experiments on ChartMimic, Plot2Code, and ChartX show that CharTide-7B/8B significantly outperforms open-source baselines, surpasses GPT-4o, and is competitive with GPT-5.
FlowInOne:Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Apr 08, 2026Multimodal generation has long been dominated by text-driven pipelines where language dictates vision but cannot reason or create within it. We challenge this paradigm by asking whether all modalities, including textual descriptions, spatial layouts, and editing instructions, can be unified into a single visual representation. We present FlowInOne, a framework that reformulates multimodal generation as a purely visual flow, converting all inputs into visual prompts and enabling a clean image-in, image-out pipeline governed by a single flow matching model. This vision-centric formulation naturally eliminates cross-modal alignment bottlenecks, noise scheduling, and task-specific architectural branches, unifying text-to-image generation, layout-guided editing, and visual instruction following under one coherent paradigm. To support this, we introduce VisPrompt-5M, a large-scale dataset of 5 million visual prompt pairs spanning diverse tasks including physics-aware force dynamics and trajectory prediction, alongside VP-Bench, a rigorously curated benchmark assessing instruction faithfulness, spatial precision, visual realism, and content consistency. Extensive experiments demonstrate that FlowInOne achieves state-of-the-art performance across all unified generation tasks, surpassing both open-source models and competitive commercial systems, establishing a new foundation for fully vision-centric generative modeling where perception and creation coexist within a single continuous visual space.
When the Prompt Becomes Visual: Vision-Centric Jailbreak Attacks for Large Image Editing Models
Feb 10, 2026Recent advances in large image editing models have shifted the paradigm from text-driven instructions to vision-prompt editing, where user intent is inferred directly from visual inputs such as marks, arrows, and visual-text prompts. While this paradigm greatly expands usability, it also introduces a critical and underexplored safety risk: the attack surface itself becomes visual. In this work, we propose Vision-Centric Jailbreak Attack (VJA), the first visual-to-visual jailbreak attack that conveys malicious instructions purely through visual inputs. To systematically study this emerging threat, we introduce IESBench, a safety-oriented benchmark for image editing models. Extensive experiments on IESBench demonstrate that VJA effectively compromises state-of-the-art commercial models, achieving attack success rates of up to 80.9% on Nano Banana Pro and 70.1% on GPT-Image-1.5. To mitigate this vulnerability, we propose a training-free defense based on introspective multimodal reasoning, which substantially improves the safety of poorly aligned models to a level comparable with commercial systems, without auxiliary guard models and with negligible computational overhead. Our findings expose new vulnerabilities, provide both a benchmark and practical defense to advance safe and trustworthy modern image editing systems. Warning: This paper contains offensive images created by large image editing models.
MIND: Benchmarking Memory Consistency and Action Control in World Models
Feb 08, 2026World models aim to understand, remember, and predict dynamic visual environments, yet a unified benchmark for evaluating their fundamental abilities remains lacking. To address this gap, we introduce MIND, the first open-domain closed-loop revisited benchmark for evaluating Memory consIstency and action coNtrol in worlD models. MIND contains 250 high-quality videos at 1080p and 24 FPS, including 100 (first-person) + 100 (third-person) video clips under a shared action space and 25 + 25 clips across varied action spaces covering eight diverse scenes. We design an efficient evaluation framework to measure two core abilities: memory consistency and action control, capturing temporal stability and contextual coherence across viewpoints. Furthermore, we design various action spaces, including different character movement speeds and camera rotation angles, to evaluate the action generalization capability across different action spaces under shared scenes. To facilitate future performance benchmarking on MIND, we introduce MIND-World, a novel interactive Video-to-World baseline. Extensive experiments demonstrate the completeness of MIND and reveal key challenges in current world models, including the difficulty of maintaining long-term memory consistency and generalizing across action spaces. Project page: https://csu-jpg.github.io/MIND.github.io/
TextEditBench: Evaluating Reasoning-aware Text Editing Beyond Rendering
Dec 18, 2025Text rendering has recently emerged as one of the most challenging frontiers in visual generation, drawing significant attention from large-scale diffusion and multimodal models. However, text editing within images remains largely unexplored, as it requires generating legible characters while preserving semantic, geometric, and contextual coherence. To fill this gap, we introduce TextEditBench, a comprehensive evaluation benchmark that explicitly focuses on text-centric regions in images. Beyond basic pixel manipulations, our benchmark emphasizes reasoning-intensive editing scenarios that require models to understand physical plausibility, linguistic meaning, and cross-modal dependencies. We further propose a novel evaluation dimension, Semantic Expectation (SE), which measures reasoning ability of model to maintain semantic consistency, contextual coherence, and cross-modal alignment during text editing. Extensive experiments on state-of-the-art editing systems reveal that while current models can follow simple textual instructions, they still struggle with context-dependent reasoning, physical consistency, and layout-aware integration. By focusing evaluation on this long-overlooked yet fundamental capability, TextEditBench establishes a new testing ground for advancing text-guided image editing and reasoning in multimodal generation.
Skeletons Speak Louder than Text: A Motion-Aware Pretraining Paradigm for Video-Based Person Re-Identification
Nov 17, 2025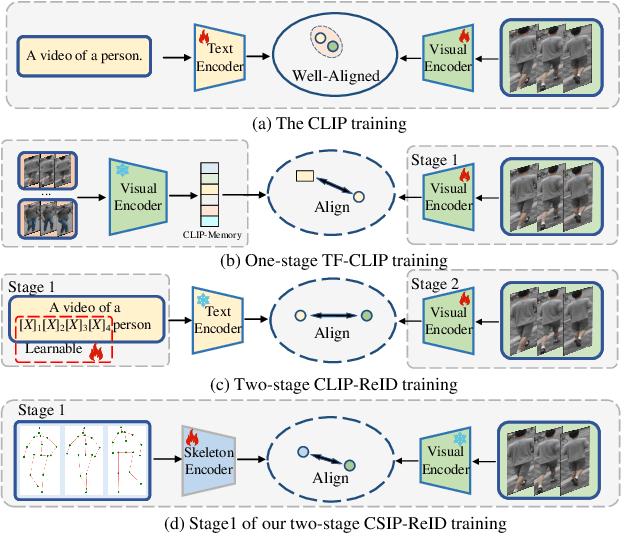
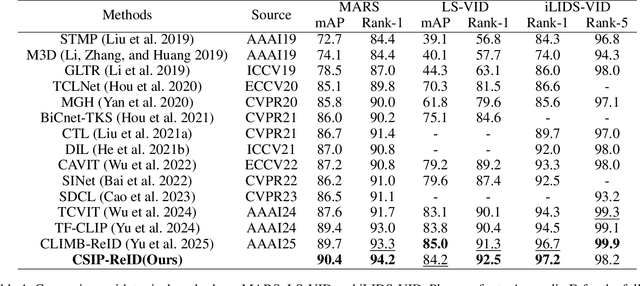
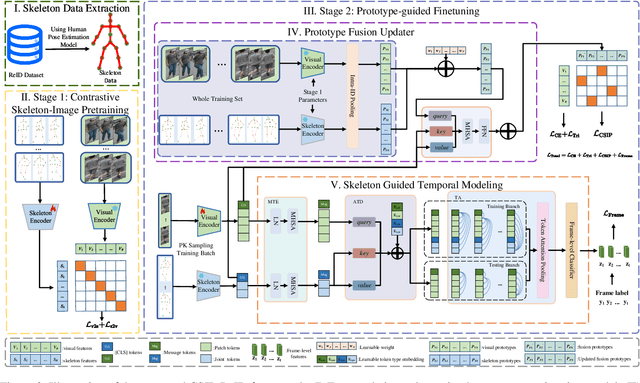

Multimodal pretraining has revolutionized visual understanding, but its impact on video-based person re-identification (ReID) remains underexplored. Existing approaches often rely on video-text pairs, yet suffer from two fundamental limitations: (1) lack of genuine multimodal pretraining, and (2) text poorly captures fine-grained temporal motion-an essential cue for distinguishing identities in video. In this work, we take a bold departure from text-based paradigms by introducing the first skeleton-driven pretraining framework for ReID. To achieve this, we propose Contrastive Skeleton-Image Pretraining for ReID (CSIP-ReID), a novel two-stage method that leverages skeleton sequences as a spatiotemporally informative modality aligned with video frames. In the first stage, we employ contrastive learning to align skeleton and visual features at sequence level. In the second stage, we introduce a dynamic Prototype Fusion Updater (PFU) to refine multimodal identity prototypes, fusing motion and appearance cues. Moreover, we propose a Skeleton Guided Temporal Modeling (SGTM) module that distills temporal cues from skeleton data and integrates them into visual features. Extensive experiments demonstrate that CSIP-ReID achieves new state-of-the-art results on standard video ReID benchmarks (MARS, LS-VID, iLIDS-VID). Moreover, it exhibits strong generalization to skeleton-only ReID tasks (BIWI, IAS), significantly outperforming previous methods. CSIP-ReID pioneers an annotation-free and motion-aware pretraining paradigm for ReID, opening a new frontier in multimodal representation learning.
See the Text: From Tokenization to Visual Reading
Oct 21, 2025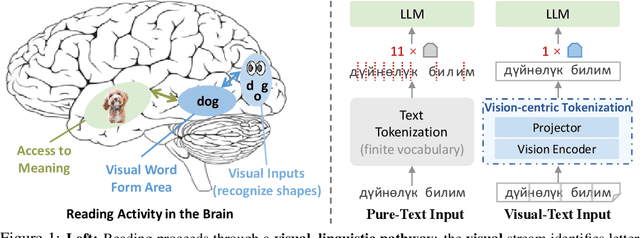

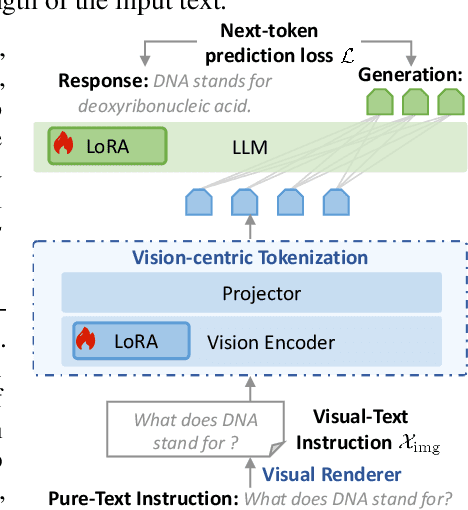

People see text. Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively. Modern large language models (LLMs), however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation. In this work, we challenge this entrenched paradigm and move toward a vision-centric alternative. Our method, SeeTok, renders text as images (visual-text) and leverages pretrained multimodal LLMs to interpret them, reusing strong OCR and text-vision alignment abilities learned from large-scale multimodal training. Across three different language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43 times fewer tokens and reducing FLOPs by 70.5%, with additional gains in cross-lingual generalization, robustness to typographic noise, and linguistic hierarchy. SeeTok signals a shift from symbolic tokenization to human-like visual reading, and takes a step toward more natural and cognitively inspired language models.
Seeing is Not Reasoning: MVPBench for Graph-based Evaluation of Multi-path Visual Physical CoT
May 30, 2025Understanding the physical world - governed by laws of motion, spatial relations, and causality - poses a fundamental challenge for multimodal large language models (MLLMs). While recent advances such as OpenAI o3 and GPT-4o demonstrate impressive perceptual and reasoning capabilities, our investigation reveals these models struggle profoundly with visual physical reasoning, failing to grasp basic physical laws, spatial interactions, and causal effects in complex scenes. More importantly, they often fail to follow coherent reasoning chains grounded in visual evidence, especially when multiple steps are needed to arrive at the correct answer. To rigorously evaluate this capability, we introduce MVPBench, a curated benchmark designed to rigorously evaluate visual physical reasoning through the lens of visual chain-of-thought (CoT). Each example features interleaved multi-image inputs and demands not only the correct final answer but also a coherent, step-by-step reasoning path grounded in evolving visual cues. This setup mirrors how humans reason through real-world physical processes over time. To ensure fine-grained evaluation, we introduce a graph-based CoT consistency metric that verifies whether the reasoning path of model adheres to valid physical logic. Additionally, we minimize shortcut exploitation from text priors, encouraging models to rely on visual understanding. Experimental results reveal a concerning trend: even cutting-edge MLLMs exhibit poor visual reasoning accuracy and weak image-text alignment in physical domains. Surprisingly, RL-based post-training alignment - commonly believed to improve visual reasoning performance - often harms spatial reasoning, suggesting a need to rethink current fine-tuning practices.