 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveCC: Learning Video LLM with Streaming Speech Transcription at Scale
Apr 22, 2025
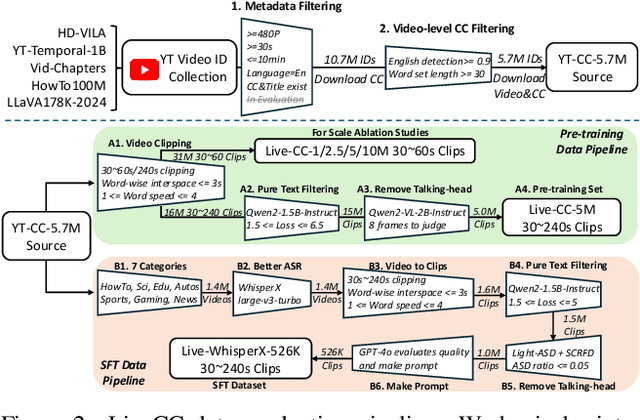
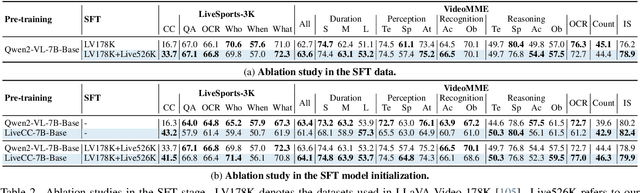
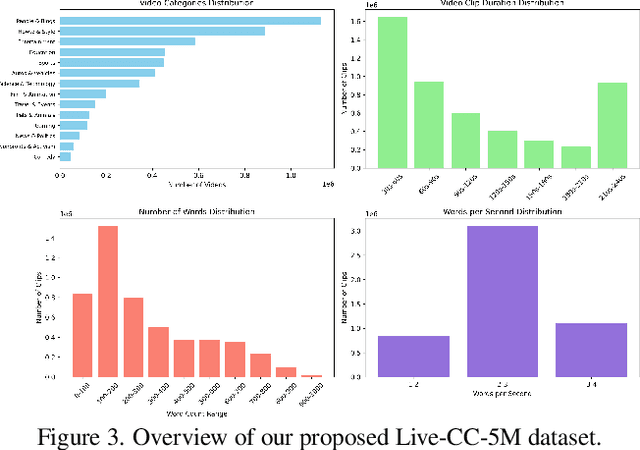
Recent video large language models (Video LLMs) often depend on costly human annotations or proprietary model APIs (e.g., GPT-4o) to produce training data, which limits their training at scale. In this paper, we explore large-scale training for Video LLM with cheap automatic speech recognition (ASR) transcripts. Specifically, we propose a novel streaming training approach that densely interleaves the ASR words and video frames according to their timestamps. Compared to previous studies in vision-language representation with ASR, our method naturally fits the streaming characteristics of ASR, thus enabling the model to learn temporally-aligned, fine-grained vision-language modeling. To support the training algorithm, we introduce a data production pipeline to process YouTube videos and their closed captions (CC, same as ASR), resulting in Live-CC-5M dataset for pre-training and Live-WhisperX-526K dataset for high-quality supervised fine-tuning (SFT). Remarkably, even without SFT, the ASR-only pre-trained LiveCC-7B-Base model demonstrates competitive general video QA performance and exhibits a new capability in real-time video commentary. To evaluate this, we carefully design a new LiveSports-3K benchmark, using LLM-as-a-judge to measure the free-form commentary. Experiments show our final LiveCC-7B-Instruct model can surpass advanced 72B models (Qwen2.5-VL-72B-Instruct, LLaVA-Video-72B) in commentary quality even working in a real-time mode. Meanwhile, it achieves state-of-the-art results at the 7B/8B scale on popular video QA benchmarks such as VideoMME and OVOBench, demonstrating the broad generalizability of our approach. All resources of this paper have been released at https://showlab.github.io/livecc.
TextAtlas5M: A Large-scale Dataset for Dense Text Image Generation
Feb 11, 2025Text-conditioned image generation has gained significant attention in recent years and are processing increasingly longer and comprehensive text prompt. In everyday life, dense and intricate text appears in contexts like advertisements, infographics, and signage, where the integration of both text and visuals is essential for conveying complex information. However, despite these advances, the generation of images containing long-form text remains a persistent challenge, largely due to the limitations of existing datasets, which often focus on shorter and simpler text. To address this gap, we introduce TextAtlas5M, a novel dataset specifically designed to evaluate long-text rendering in text-conditioned image generation. Our dataset consists of 5 million long-text generated and collected images across diverse data types, enabling comprehensive evaluation of large-scale generative models on long-text image generation. We further curate 3000 human-improved test set TextAtlasEval across 3 data domains, establishing one of the most extensive benchmarks for text-conditioned generation. Evaluations suggest that the TextAtlasEval benchmarks present significant challenges even for the most advanced proprietary models (e.g. GPT4o with DallE-3), while their open-source counterparts show an even larger performance gap. These evidences position TextAtlas5M as a valuable dataset for training and evaluating future-generation text-conditioned image generation models.
Leveraging Visual Tokens for Extended Text Contexts in Multi-Modal Learning
Jun 04, 2024Training models with longer in-context lengths is a significant challenge for multimodal model due to substantial GPU memory and computational costs. This exploratory study does not present state-of-the-art models; rather, it introduces an innovative method designed to increase in-context text length in multi-modality large language models (MLLMs) efficiently. We present Visualized In-Context Text Processing (VisInContext), which processes long in-context text using visual tokens. This technique significantly reduces GPU memory usage and floating point operations (FLOPs) for both training and inferenceing stage. For instance, our method expands the pre-training in-context text length from 256 to 2048 tokens with nearly same FLOPs for a 56 billion parameter MOE model. Experimental results demonstrate that model trained with VisInContext delivers superior performance on common downstream benchmarks for in-context few-shot evaluation. Additionally, VisInContext is complementary to existing methods for increasing in-context text length and enhances document understanding capabilities, showing great potential in document QA tasks and sequential document retrieval.
Parrot Captions Teach CLIP to Spot Text
Dec 28, 2023Despite CLIP being the foundation model in numerous vision-language applications, the CLIP suffers from a severe text spotting bias. Such bias causes CLIP models to 'Parrot' the visual text embedded within images while disregarding the authentic visual semantics. We uncover that in the most popular image-text dataset LAION-2B, the captions also densely parrot (spell) the text embedded in images. Our analysis shows that around 50% of images are embedded with visual text content, and 90% of their captions more or less parrot the visual text. Based on such observation, we thoroughly inspect the different released versions of CLIP models and verify that the visual text is the dominant factor in measuring the LAION-style image-text similarity for these models. To examine whether these parrot captions shape the text spotting bias, we train a series of CLIP models with LAION subsets curated by different parrot-caption-oriented criteria. We show that training with parrot captions easily shapes such bias but harms the expected visual-language representation learning in CLIP models. This suggests that it is urgent to revisit either the design of CLIP-like models or the existing image-text dataset curation pipeline built on CLIP score filtering.
Dynamic PlenOctree for Adaptive Sampling Refinement in Explicit NeRF
Jul 28, 2023The explicit neural radiance field (NeRF) has gained considerable interest for its efficient training and fast inference capabilities, making it a promising direction such as virtual reality and gaming. In particular, PlenOctree (POT)[1], an explicit hierarchical multi-scale octree representation, has emerged as a structural and influential framework. However, POT's fixed structure for direct optimization is sub-optimal as the scene complexity evolves continuously with updates to cached color and density, necessitating refining the sampling distribution to capture signal complexity accordingly. To address this issue, we propose the dynamic PlenOctree DOT, which adaptively refines the sample distribution to adjust to changing scene complexity. Specifically, DOT proposes a concise yet novel hierarchical feature fusion strategy during the iterative rendering process. Firstly, it identifies the regions of interest through training signals to ensure adaptive and efficient refinement. Next, rather than directly filtering out valueless nodes, DOT introduces the sampling and pruning operations for octrees to aggregate features, enabling rapid parameter learning. Compared with POT, our DOT outperforms it by enhancing visual quality, reducing over $55.15$/$68.84\%$ parameters, and providing 1.7/1.9 times FPS for NeRF-synthetic and Tanks $\&$ Temples, respectively. Project homepage:https://vlislab22.github.io/DOT. [1] Yu, Alex, et al. "Plenoctrees for real-time rendering of neural radiance fields." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
Towards Language-guided Interactive 3D Generation: LLMs as Layout Interpreter with Generative Feedback
May 25, 2023Generating and editing a 3D scene guided by natural language poses a challenge, primarily due to the complexity of specifying the positional relations and volumetric changes within the 3D space. Recent advancements in Large Language Models (LLMs) have demonstrated impressive reasoning, conversational, and zero-shot generation abilities across various domains. Surprisingly, these models also show great potential in realizing and interpreting the 3D space. In light of this, we propose a novel language-guided interactive 3D generation system, dubbed LI3D, that integrates LLMs as a 3D layout interpreter into the off-the-shelf layout-to-3D generative models, allowing users to flexibly and interactively generate visual content. Specifically, we design a versatile layout structure base on the bounding boxes and semantics to prompt the LLMs to model the spatial generation and reasoning from language. Our system also incorporates LLaVA, a large language and vision assistant, to provide generative feedback from the visual aspect for improving the visual quality of generated content. We validate the effectiveness of LI3D, primarily in 3D generation and editing through multi-round interactions, which can be flexibly extended to 2D generation and editing. Various experiments demonstrate the potential benefits of incorporating LLMs in generative AI for applications, e.g., metaverse. Moreover, we benchmark the layout reasoning performance of LLMs with neural visual artist tasks, revealing their emergent ability in the spatial layout domain.
CompoNeRF: Text-guided Multi-object Compositional NeRF with Editable 3D Scene Layout
Mar 24, 2023


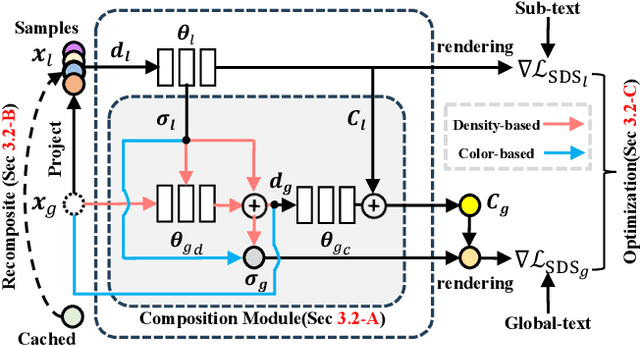
Recent research endeavors have shown that combining neural radiance fields (NeRFs) with pre-trained diffusion models holds great potential for text-to-3D generation.However, a hurdle is that they often encounter guidance collapse when rendering complex scenes from multi-object texts. Because the text-to-image diffusion models are inherently unconstrained, making them less competent to accurately associate object semantics with specific 3D structures. To address this issue, we propose a novel framework, dubbed CompoNeRF, that explicitly incorporates an editable 3D scene layout to provide effective guidance at the single object (i.e., local) and whole scene (i.e., global) levels. Firstly, we interpret the multi-object text as an editable 3D scene layout containing multiple local NeRFs associated with the object-specific 3D box coordinates and text prompt, which can be easily collected from users. Then, we introduce a global MLP to calibrate the compositional latent features from local NeRFs, which surprisingly improves the view consistency across different local NeRFs. Lastly, we apply the text guidance on global and local levels through their corresponding views to avoid guidance ambiguity. This way, our CompoNeRF allows for flexible scene editing and re-composition of trained local NeRFs into a new scene by manipulating the 3D layout or text prompt. Leveraging the open-source Stable Diffusion model, our CompoNeRF can generate faithful and editable text-to-3D results while opening a potential direction for text-guided multi-object composition via the editable 3D scene layout.
SEPT: Towards Scalable and Efficient Visual Pre-Training
Dec 11, 2022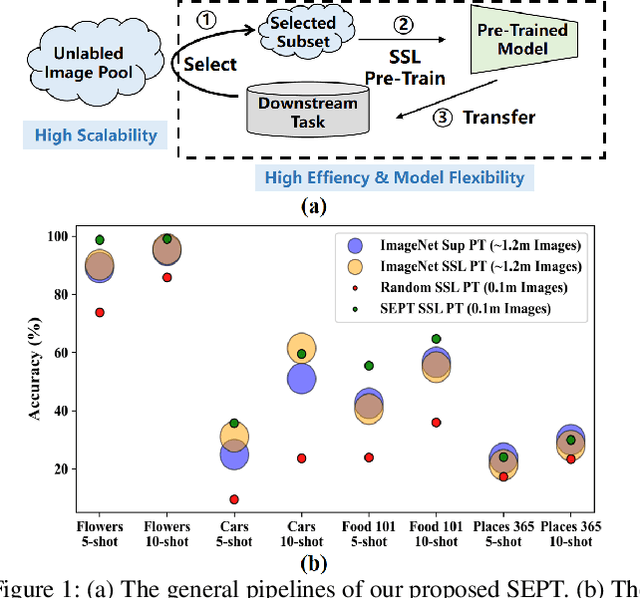
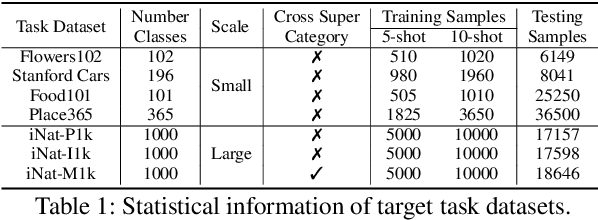

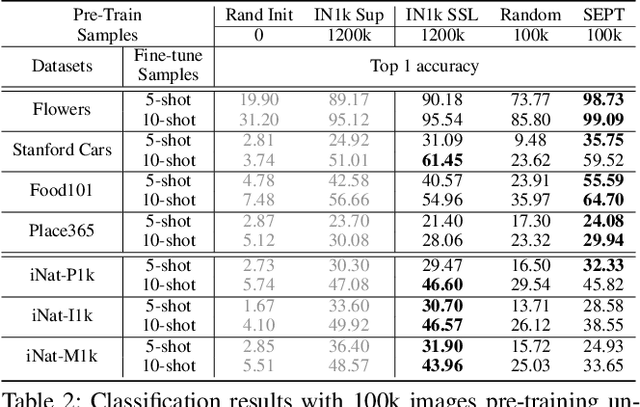
Recently, the self-supervised pre-training paradigm has shown great potential in leveraging large-scale unlabeled data to improve downstream task performance. However, increasing the scale of unlabeled pre-training data in real-world scenarios requires prohibitive computational costs and faces the challenge of uncurated samples. To address these issues, we build a task-specific self-supervised pre-training framework from a data selection perspective based on a simple hypothesis that pre-training on the unlabeled samples with similar distribution to the target task can bring substantial performance gains. Buttressed by the hypothesis, we propose the first yet novel framework for Scalable and Efficient visual Pre-Training (SEPT) by introducing a retrieval pipeline for data selection. SEPT first leverage a self-supervised pre-trained model to extract the features of the entire unlabeled dataset for retrieval pipeline initialization. Then, for a specific target task, SEPT retrievals the most similar samples from the unlabeled dataset based on feature similarity for each target instance for pre-training. Finally, SEPT pre-trains the target model with the selected unlabeled samples in a self-supervised manner for target data finetuning. By decoupling the scale of pre-training and available upstream data for a target task, SEPT achieves high scalability of the upstream dataset and high efficiency of pre-training, resulting in high model architecture flexibility. Results on various downstream tasks demonstrate that SEPT can achieve competitive or even better performance compared with ImageNet pre-training while reducing the size of training samples by one magnitude without resorting to any extra annotations.
On the instrumental variable estimation with many weak and invalid instruments
Jul 07, 2022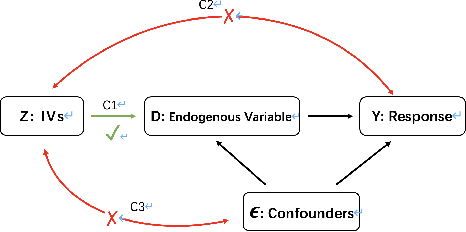


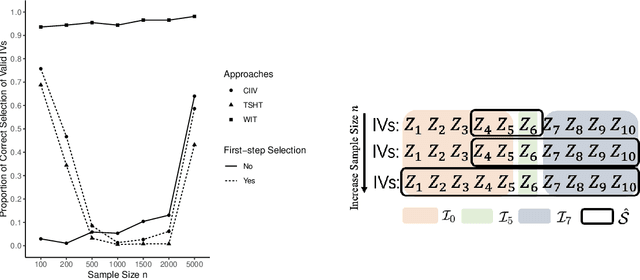
We discuss the fundamental issue of identification in linear instrumental variable (IV) models with unknown IV validity. We revisit the popular majority and plurality rules and show that no identification condition can be "if and only if" in general. With the assumption of the "sparsest rule", which is equivalent to the plurality rule but becomes operational in computation algorithms, we investigate and prove the advantages of non-convex penalized approaches over other IV estimators based on two-step selections, in terms of selection consistency and accommodation for individually weak IVs. Furthermore, we propose a surrogate sparsest penalty that aligns with the identification condition and provides oracle sparse structure simultaneously. Desirable theoretical properties are derived for the proposed estimator with weaker IV strength conditions compared to the previous literature. Finite sample properties are demonstrated using simulations and the selection and estimation method is applied to an empirical study concerning the effect of trade on economic growth.
All One Needs to Know about Priors for Deep Image Restoration and Enhancement: A Survey
Jun 04, 2022

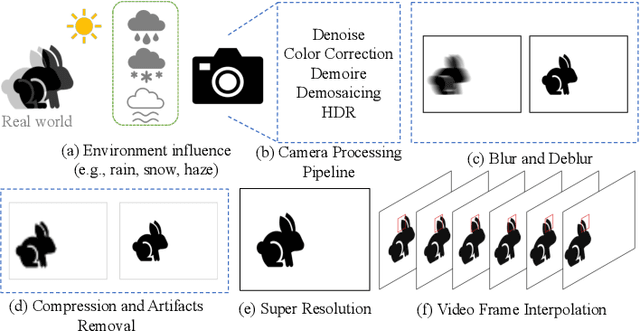

Image restoration and enhancement is a process of improving the image quality by removing degradations, such as noise, blur, and resolution degradation. Deep learning (DL) has recently been applied to image restoration and enhancement. Due to its ill-posed property, plenty of works have explored priors to facilitate training deep neural networks (DNNs). However, the importance of priors has not been systematically studied and analyzed by far in the research community. Therefore, this paper serves as the first study that provides a comprehensive overview of recent advancements of priors for deep image restoration and enhancement. Our work covers five primary contents: (1) A theoretical analysis of priors for deep image restoration and enhancement; (2) A hierarchical and structural taxonomy of priors commonly used in the DL-based methods; (3) An insightful discussion on each prior regarding its principle, potential, and applications; (4) A summary of crucial problems by highlighting the potential future directions to spark more research in the community; (5) An open-source repository that provides a taxonomy of all mentioned works and code links.