 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextEditBench: Evaluating Reasoning-aware Text Editing Beyond Rendering
Dec 18, 2025Text rendering has recently emerged as one of the most challenging frontiers in visual generation, drawing significant attention from large-scale diffusion and multimodal models. However, text editing within images remains largely unexplored, as it requires generating legible characters while preserving semantic, geometric, and contextual coherence. To fill this gap, we introduce TextEditBench, a comprehensive evaluation benchmark that explicitly focuses on text-centric regions in images. Beyond basic pixel manipulations, our benchmark emphasizes reasoning-intensive editing scenarios that require models to understand physical plausibility, linguistic meaning, and cross-modal dependencies. We further propose a novel evaluation dimension, Semantic Expectation (SE), which measures reasoning ability of model to maintain semantic consistency, contextual coherence, and cross-modal alignment during text editing. Extensive experiments on state-of-the-art editing systems reveal that while current models can follow simple textual instructions, they still struggle with context-dependent reasoning, physical consistency, and layout-aware integration. By focusing evaluation on this long-overlooked yet fundamental capability, TextEditBench establishes a new testing ground for advancing text-guided image editing and reasoning in multimodal generation.
ContrastiveGaussian: High-Fidelity 3D Generation with Contrastive Learning and Gaussian Splatting
Apr 10, 2025Creating 3D content from single-view images is a challenging problem that has attracted considerable attention in recent years. Current approaches typically utilize score distillation sampling (SDS) from pre-trained 2D diffusion models to generate multi-view 3D representations. Although some methods have made notable progress by balancing generation speed and model quality, their performance is often limited by the visual inconsistencies of the diffusion model outputs. In this work, we propose ContrastiveGaussian, which integrates contrastive learning into the generative process. By using a perceptual loss, we effectively differentiate between positive and negative samples, leveraging the visual inconsistencies to improve 3D generation quality. To further enhance sample differentiation and improve contrastive learning, we incorporate a super-resolution model and introduce another Quantity-Aware Triplet Loss to address varying sample distributions during training. Our experiments demonstrate that our approach achieves superior texture fidelity and improved geometric consistency.
TextAtlas5M: A Large-scale Dataset for Dense Text Image Generation
Feb 11, 2025Text-conditioned image generation has gained significant attention in recent years and are processing increasingly longer and comprehensive text prompt. In everyday life, dense and intricate text appears in contexts like advertisements, infographics, and signage, where the integration of both text and visuals is essential for conveying complex information. However, despite these advances, the generation of images containing long-form text remains a persistent challenge, largely due to the limitations of existing datasets, which often focus on shorter and simpler text. To address this gap, we introduce TextAtlas5M, a novel dataset specifically designed to evaluate long-text rendering in text-conditioned image generation. Our dataset consists of 5 million long-text generated and collected images across diverse data types, enabling comprehensive evaluation of large-scale generative models on long-text image generation. We further curate 3000 human-improved test set TextAtlasEval across 3 data domains, establishing one of the most extensive benchmarks for text-conditioned generation. Evaluations suggest that the TextAtlasEval benchmarks present significant challenges even for the most advanced proprietary models (e.g. GPT4o with DallE-3), while their open-source counterparts show an even larger performance gap. These evidences position TextAtlas5M as a valuable dataset for training and evaluating future-generation text-conditioned image generation models.
VideoLLM-online: Online Video Large Language Model for Streaming Video
Jun 17, 2024
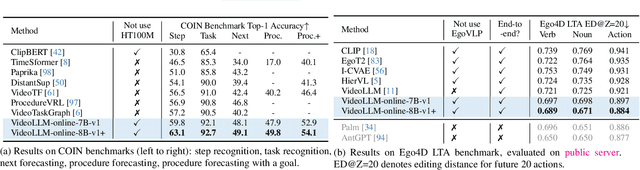
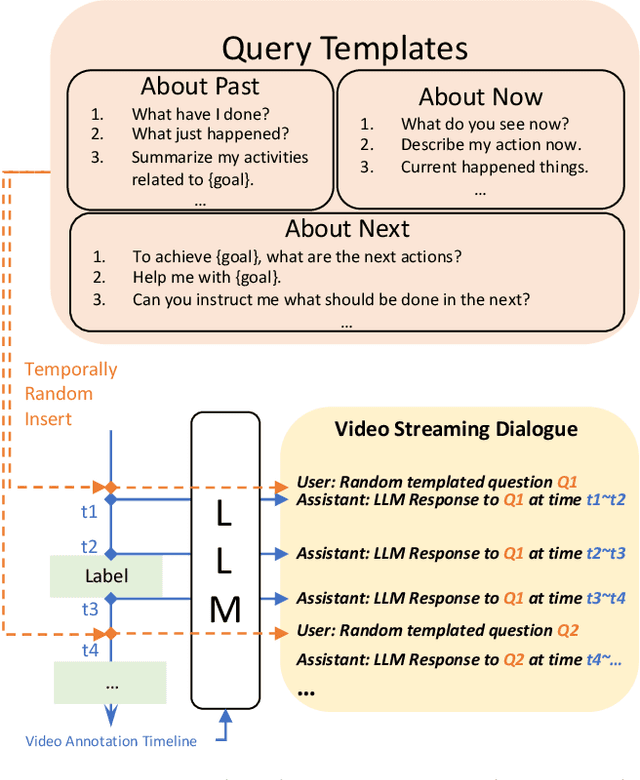
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.
ASSISTGUI: Task-Oriented Desktop Graphical User Interface Automation
Jan 01, 2024Graphical User Interface (GUI) automation holds significant promise for assisting users with complex tasks, thereby boosting human productivity. Existing works leveraging Large Language Model (LLM) or LLM-based AI agents have shown capabilities in automating tasks on Android and Web platforms. However, these tasks are primarily aimed at simple device usage and entertainment operations. This paper presents a novel benchmark, AssistGUI, to evaluate whether models are capable of manipulating the mouse and keyboard on the Windows platform in response to user-requested tasks. We carefully collected a set of 100 tasks from nine widely-used software applications, such as, After Effects and MS Word, each accompanied by the necessary project files for better evaluation. Moreover, we propose an advanced Actor-Critic Embodied Agent framework, which incorporates a sophisticated GUI parser driven by an LLM-agent and an enhanced reasoning mechanism adept at handling lengthy procedural tasks. Our experimental results reveal that our GUI Parser and Reasoning mechanism outshine existing methods in performance. Nevertheless, the potential remains substantial, with the best model attaining only a 46% success rate on our benchmark. We conclude with a thorough analysis of the current methods' limitations, setting the stage for future breakthroughs in this domain.
AssistQ: Affordance-centric Question-driven Task Completion for Egocentric Assistant
Mar 08, 2022
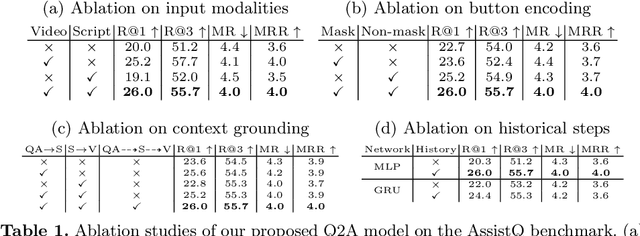
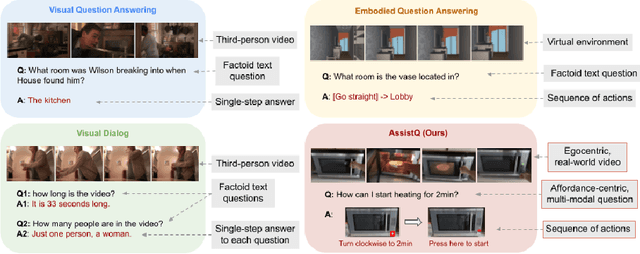

A long-standing goal of intelligent assistants such as AR glasses/robots has been to assist users in affordance-centric real-world scenarios, such as "how can I run the microwave for 1 minute?". However, there is still no clear task definition and suitable benchmarks. In this paper, we define a new task called Affordance-centric Question-driven Task Completion, where the AI assistant should learn from instructional videos and scripts to guide the user step-by-step. To support the task, we constructed AssistQ, a new dataset comprising 529 question-answer samples derived from 100 newly filmed first-person videos. Each question should be completed with multi-step guidances by inferring from visual details (e.g., buttons' position) and textural details (e.g., actions like press/turn). To address this unique task, we developed a Question-to-Actions (Q2A) model that significantly outperforms several baseline methods while still having large room for improvement. We expect our task and dataset to advance Egocentric AI Assistant's development. Our project page is available at: https://showlab.github.io/assistq
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Dec 06, 2021



It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.