 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Large; Data Reduction for Vision-Language Pre-Training
Jun 01, 2023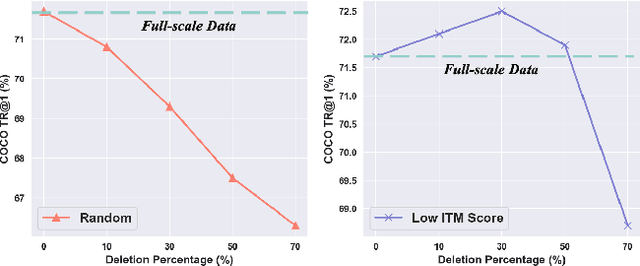



This paper examines the problems of severe image-text misalignment and high redundancy in the widely-used large-scale Vision-Language Pre-Training (VLP) datasets. To address these issues, we propose an efficient and straightforward Vision-Language learning algorithm called TL;DR, which aims to compress the existing large VLP data into a small, high-quality set. Our approach consists of two major steps. First, a codebook-based encoder-decoder captioner is developed to select representative samples. Second, a new caption is generated to complement the original captions for selected samples, mitigating the text-image misalignment problem while maintaining uniqueness. As the result, TL;DR enables us to reduce the large dataset into a small set of high-quality data, which can serve as an alternative pre-training dataset. This algorithm significantly speeds up the time-consuming pretraining process. Specifically, TL;DR can compress the mainstream VLP datasets at a high ratio, e.g., reduce well-cleaned CC3M dataset from 2.82M to 0.67M ($\sim$24\%) and noisy YFCC15M from 15M to 2.5M ($\sim$16.7\%). Extensive experiments with three popular VLP models over seven downstream tasks show that VLP model trained on the compressed dataset provided by TL;DR can perform similar or even better results compared with training on the full-scale dataset. The code will be made available at \url{https://github.com/showlab/data-centric.vlp}.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 29, 2022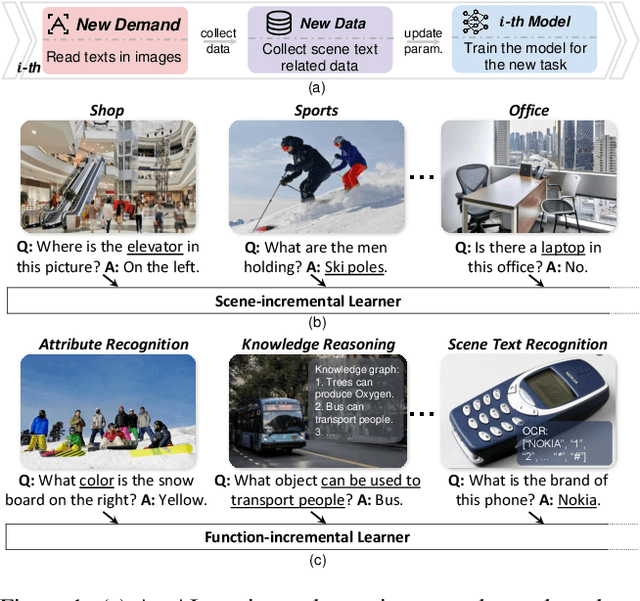
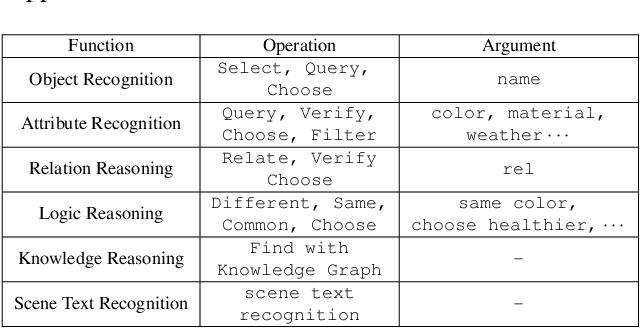
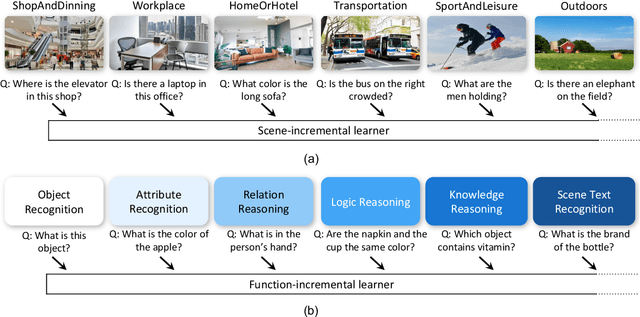
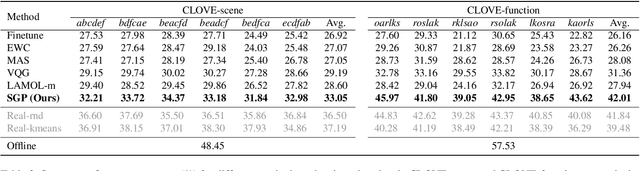
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
GEB+: A benchmark for generic event boundary captioning, grounding and text-based retrieval
Apr 10, 2022



Cognitive science has shown that humans perceive videos in terms of events separated by state changes of dominant subjects. State changes trigger new events and are one of the most useful among the large amount of redundant information perceived. However, previous research focuses on the overall understanding of segments without evaluating the fine-grained status changes inside. In this paper, we introduce a new dataset called Kinetic-GEBC (Generic Event Boundary Captioning). The dataset consists of over 170k boundaries associated with captions describing status changes in the generic events in 12K videos. Upon this new dataset, we propose three tasks supporting the development of a more fine-grained, robust, and human-like understanding of videos through status changes. We evaluate many representative baselines in our dataset, where we also design a new TPD (Temporal-based Pairwise Difference) Modeling method for current state-of-the-art backbones and achieve significant performance improvements. Besides, the results show there are still formidable challenges for current methods in the utilization of different granularities, representation of visual difference, and the accurate localization of status changes. Further analysis shows that our dataset can drive developing more powerful methods to understand status changes and thus improve video level comprehension.
AssistQ: Affordance-centric Question-driven Task Completion for Egocentric Assistant
Mar 08, 2022
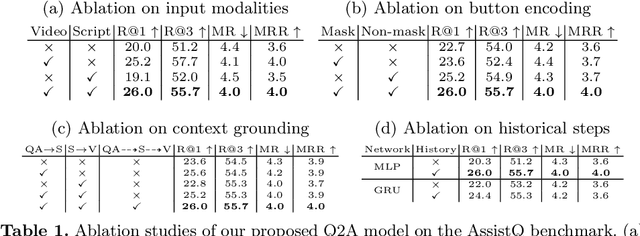
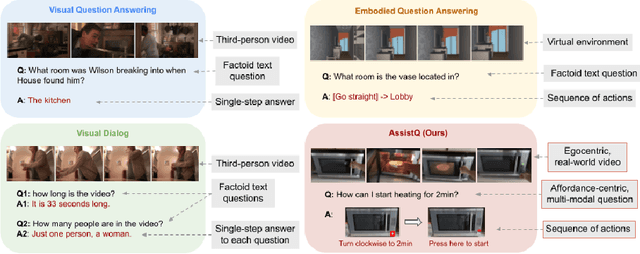

A long-standing goal of intelligent assistants such as AR glasses/robots has been to assist users in affordance-centric real-world scenarios, such as "how can I run the microwave for 1 minute?". However, there is still no clear task definition and suitable benchmarks. In this paper, we define a new task called Affordance-centric Question-driven Task Completion, where the AI assistant should learn from instructional videos and scripts to guide the user step-by-step. To support the task, we constructed AssistQ, a new dataset comprising 529 question-answer samples derived from 100 newly filmed first-person videos. Each question should be completed with multi-step guidances by inferring from visual details (e.g., buttons' position) and textural details (e.g., actions like press/turn). To address this unique task, we developed a Question-to-Actions (Q2A) model that significantly outperforms several baseline methods while still having large room for improvement. We expect our task and dataset to advance Egocentric AI Assistant's development. Our project page is available at: https://showlab.github.io/assistq
AssistSR: Affordance-centric Question-driven Video Segment Retrieval
Dec 06, 2021



It is still a pipe dream that AI assistants on phone and AR glasses can assist our daily life in addressing our questions like "how to adjust the date for this watch?" and "how to set its heating duration? (while pointing at an oven)". The queries used in conventional tasks (i.e. Video Question Answering, Video Retrieval, Moment Localization) are often factoid and based on pure text. In contrast, we present a new task called Affordance-centric Question-driven Video Segment Retrieval (AQVSR). Each of our questions is an image-box-text query that focuses on affordance of items in our daily life and expects relevant answer segments to be retrieved from a corpus of instructional video-transcript segments. To support the study of this AQVSR task, we construct a new dataset called AssistSR. We design novel guidelines to create high-quality samples. This dataset contains 1.4k multimodal questions on 1k video segments from instructional videos on diverse daily-used items. To address AQVSR, we develop a straightforward yet effective model called Dual Multimodal Encoders (DME) that significantly outperforms several baseline methods while still having large room for improvement in the future. Moreover, we present detailed ablation analyses. Our codes and data are available at https://github.com/StanLei52/AQVSR.