 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Fishing for Answers: Exploring One-shot vs. Iterative Retrieval Strategies for Retrieval Augmented Generation
Sep 05, 2025Retrieval-Augmented Generation (RAG) based on Large Language Models (LLMs) is a powerful solution to understand and query the industry's closed-source documents. However, basic RAG often struggles with complex QA tasks in legal and regulatory domains, particularly when dealing with numerous government documents. The top-$k$ strategy frequently misses golden chunks, leading to incomplete or inaccurate answers. To address these retrieval bottlenecks, we explore two strategies to improve evidence coverage and answer quality. The first is a One-SHOT retrieval method that adaptively selects chunks based on a token budget, allowing as much relevant content as possible to be included within the model's context window. Additionally, we design modules to further filter and refine the chunks. The second is an iterative retrieval strategy built on a Reasoning Agentic RAG framework, where a reasoning LLM dynamically issues search queries, evaluates retrieved results, and progressively refines the context over multiple turns. We identify query drift and retrieval laziness issues and further design two modules to tackle them. Through extensive experiments on a dataset of government documents, we aim to offer practical insights and guidance for real-world applications in legal and regulatory domains.
Gradient Rectification for Robust Calibration under Distribution Shift
Aug 27, 2025Deep neural networks often produce overconfident predictions, undermining their reliability in safety-critical applications. This miscalibration is further exacerbated under distribution shift, where test data deviates from the training distribution due to environmental or acquisition changes. While existing approaches improve calibration through training-time regularization or post-hoc adjustment, their reliance on access to or simulation of target domains limits their practicality in real-world scenarios. In this paper, we propose a novel calibration framework that operates without access to target domain information. From a frequency-domain perspective, we identify that distribution shifts often distort high-frequency visual cues exploited by deep models, and introduce a low-frequency filtering strategy to encourage reliance on domain-invariant features. However, such information loss may degrade In-Distribution (ID) calibration performance. Therefore, we further propose a gradient-based rectification mechanism that enforces ID calibration as a hard constraint during optimization. Experiments on synthetic and real-world shifted datasets, including CIFAR-10/100-C and WILDS, demonstrate that our method significantly improves calibration under distribution shift while maintaining strong in-distribution performance.
Reasoning RAG via System 1 or System 2: A Survey on Reasoning Agentic Retrieval-Augmented Generation for Industry Challenges
Jun 12, 2025Retrieval-Augmented Generation (RAG) has emerged as a powerful framework to overcome the knowledge limitations of Large Language Models (LLMs) by integrating external retrieval with language generation. While early RAG systems based on static pipelines have shown effectiveness in well-structured tasks, they struggle in real-world scenarios requiring complex reasoning, dynamic retrieval, and multi-modal integration. To address these challenges, the field has shifted toward Reasoning Agentic RAG, a paradigm that embeds decision-making and adaptive tool use directly into the retrieval process. In this paper, we present a comprehensive review of Reasoning Agentic RAG methods, categorizing them into two primary systems: predefined reasoning, which follows fixed modular pipelines to boost reasoning, and agentic reasoning, where the model autonomously orchestrates tool interaction during inference. We analyze representative techniques under both paradigms, covering architectural design, reasoning strategies, and tool coordination. Finally, we discuss key research challenges and propose future directions to advance the flexibility, robustness, and applicability of reasoning agentic RAG systems. Our collection of the relevant research has been organized into a https://github.com/ByebyeMonica/Reasoning-Agentic-RAG.
In-Context Brush: Zero-shot Customized Subject Insertion with Context-Aware Latent Space Manipulation
May 26, 2025Recent advances in diffusion models have enhanced multimodal-guided visual generation, enabling customized subject insertion that seamlessly "brushes" user-specified objects into a given image guided by textual prompts. However, existing methods often struggle to insert customized subjects with high fidelity and align results with the user's intent through textual prompts. In this work, we propose "In-Context Brush", a zero-shot framework for customized subject insertion by reformulating the task within the paradigm of in-context learning. Without loss of generality, we formulate the object image and the textual prompts as cross-modal demonstrations, and the target image with the masked region as the query. The goal is to inpaint the target image with the subject aligning textual prompts without model tuning. Building upon a pretrained MMDiT-based inpainting network, we perform test-time enhancement via dual-level latent space manipulation: intra-head "latent feature shifting" within each attention head that dynamically shifts attention outputs to reflect the desired subject semantics and inter-head "attention reweighting" across different heads that amplifies prompt controllability through differential attention prioritization. Extensive experiments and applications demonstrate that our approach achieves superior identity preservation, text alignment, and image quality compared to existing state-of-the-art methods, without requiring dedicated training or additional data collection.
Learning Occlusion-Robust Vision Transformers for Real-Time UAV Tracking
Apr 12, 2025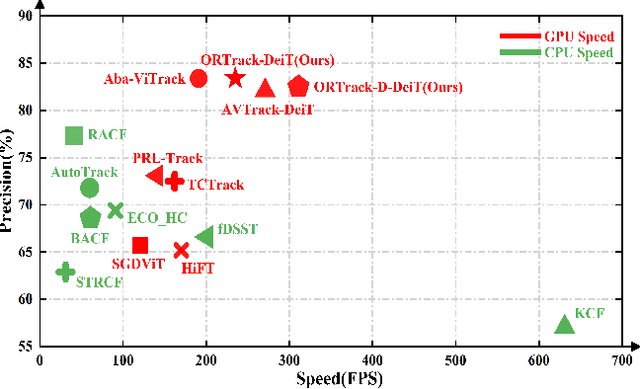
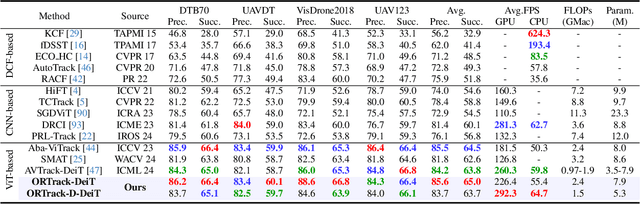
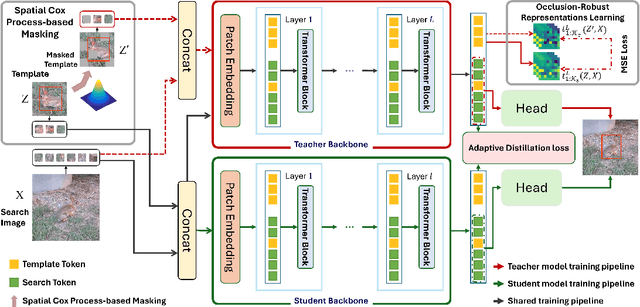

Single-stream architectures using Vision Transformer (ViT) backbones show great potential for real-time UAV tracking recently. However, frequent occlusions from obstacles like buildings and trees expose a major drawback: these models often lack strategies to handle occlusions effectively. New methods are needed to enhance the occlusion resilience of single-stream ViT models in aerial tracking. In this work, we propose to learn Occlusion-Robust Representations (ORR) based on ViTs for UAV tracking by enforcing an invariance of the feature representation of a target with respect to random masking operations modeled by a spatial Cox process. Hopefully, this random masking approximately simulates target occlusions, thereby enabling us to learn ViTs that are robust to target occlusion for UAV tracking. This framework is termed ORTrack. Additionally, to facilitate real-time applications, we propose an Adaptive Feature-Based Knowledge Distillation (AFKD) method to create a more compact tracker, which adaptively mimics the behavior of the teacher model ORTrack according to the task's difficulty. This student model, dubbed ORTrack-D, retains much of ORTrack's performance while offering higher efficiency. Extensive experiments on multiple benchmarks validate the effectiveness of our method, demonstrating its state-of-the-art performance. Codes is available at https://github.com/wuyou3474/ORTrack.
Affordable AI Assistants with Knowledge Graph of Thoughts
Apr 03, 2025Large Language Models (LLMs) are revolutionizing the development of AI assistants capable of performing diverse tasks across domains. However, current state-of-the-art LLM-driven agents face significant challenges, including high operational costs and limited success rates on complex benchmarks like GAIA. To address these issues, we propose the Knowledge Graph of Thoughts (KGoT), an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. For example, KGoT achieves a 29% improvement in task success rates on the GAIA benchmark compared to Hugging Face Agents with GPT-4o mini, while reducing costs by over 36x compared to GPT-4o. Improvements for recent reasoning models are similar, e.g., 36% and 37.5% for Qwen2.5-32B and Deepseek-R1-70B, respectively. KGoT offers a scalable, affordable, and high-performing solution for AI assistants.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Learning Adaptive and View-Invariant Vision Transformer with Multi-Teacher Knowledge Distillation for Real-Time UAV Tracking
Dec 28, 2024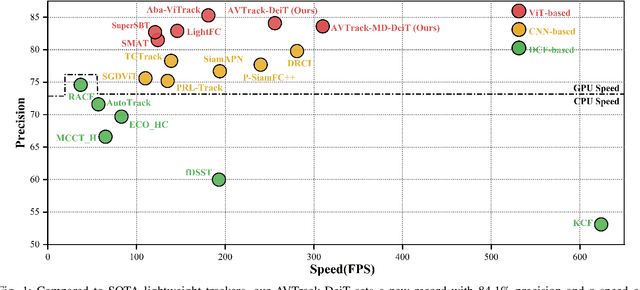
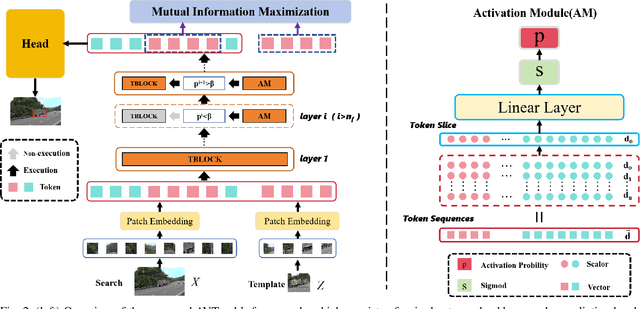
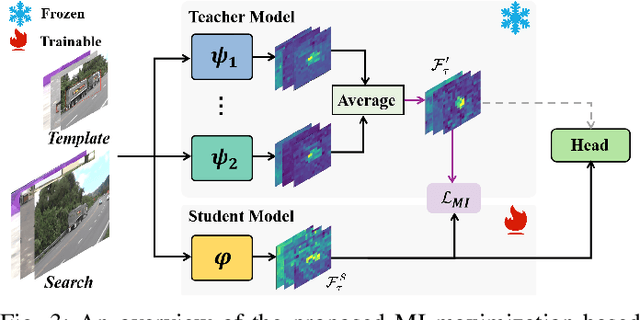
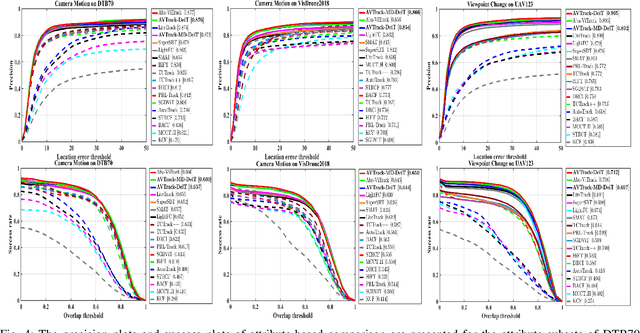
Visual tracking has made significant strides due to the adoption of transformer-based models. Most state-of-the-art trackers struggle to meet real-time processing demands on mobile platforms with constrained computing resources, particularly for real-time unmanned aerial vehicle (UAV) tracking. To achieve a better balance between performance and efficiency, we introduce AVTrack, an adaptive computation framework designed to selectively activate transformer blocks for real-time UAV tracking. The proposed Activation Module (AM) dynamically optimizes the ViT architecture by selectively engaging relevant components, thereby enhancing inference efficiency without significant compromise to tracking performance. Furthermore, to tackle the challenges posed by extreme changes in viewing angles often encountered in UAV tracking, the proposed method enhances ViTs' effectiveness by learning view-invariant representations through mutual information (MI) maximization. Two effective design principles are proposed in the AVTrack. Building on it, we propose an improved tracker, dubbed AVTrack-MD, which introduces the novel MI maximization-based multi-teacher knowledge distillation (MD) framework. It harnesses the benefits of multiple teachers, specifically the off-the-shelf tracking models from the AVTrack, by integrating and refining their outputs, thereby guiding the learning process of the compact student network. Specifically, we maximize the MI between the softened feature representations from the multi-teacher models and the student model, leading to improved generalization and performance of the student model, particularly in noisy conditions. Extensive experiments on multiple UAV tracking benchmarks demonstrate that AVTrack-MD not only achieves performance comparable to the AVTrack baseline but also reduces model complexity, resulting in a significant 17\% increase in average tracking speed.
Integrative Analysis of Financial Market Sentiment Using CNN and GRU for Risk Prediction and Alert Systems
Dec 13, 2024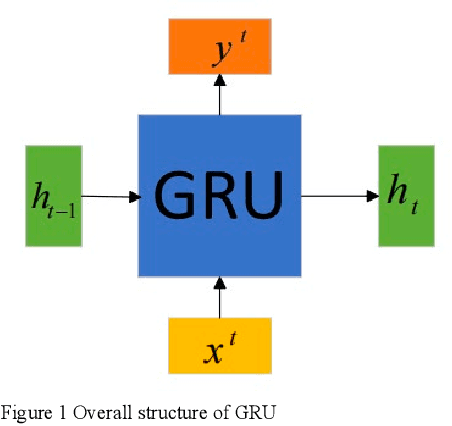
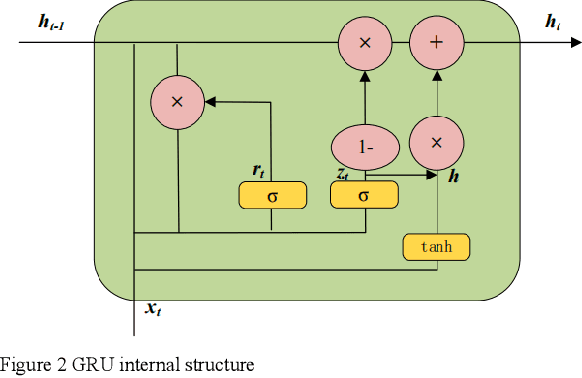
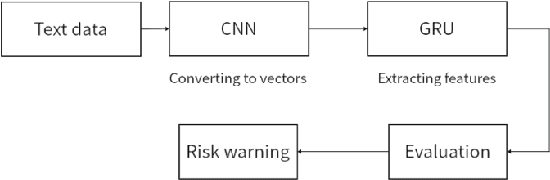
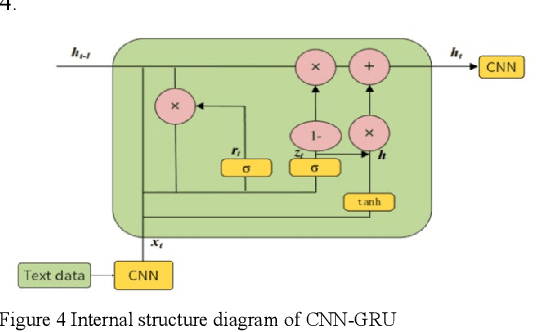
This document presents an in-depth examination of stock market sentiment through the integration of Convolutional Neural Networks (CNN) and Gated Recurrent Units (GRU), enabling precise risk alerts. The robust feature extraction capability of CNN is utilized to preprocess and analyze extensive network text data, identifying local features and patterns. The extracted feature sequences are then input into the GRU model to understand the progression of emotional states over time and their potential impact on future market sentiment and risk. This approach addresses the order dependence and long-term dependencies inherent in time series data, resulting in a detailed analysis of stock market sentiment and effective early warnings of future risks.