 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs for Divide-and-Conquer Reasoning Elevates Test-Time Scalability
Feb 02, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities through step-by-step chain-of-thought (CoT) reasoning. Nevertheless, at the limits of model capability, CoT often proves insufficient, and its strictly sequential nature constrains test-time scalability. A potential alternative is divide-and-conquer (DAC) reasoning, which decomposes a complex problem into subproblems to facilitate more effective exploration of the solution. Although promising, our analysis reveals a fundamental misalignment between general-purpose post-training and DAC-style inference, which limits the model's capacity to fully leverage this potential. To bridge this gap and fully unlock LLMs' reasoning capabilities on the most challenging tasks, we propose an end-to-end reinforcement learning (RL) framework to enhance their DAC-style reasoning capacity. At each step, the policy decomposes a problem into a group of subproblems, solves them sequentially, and addresses the original one conditioned on the subproblem solutions, with both decomposition and solution integrated into RL training. Under comparable training, our DAC-style framework endows the model with a higher performance ceiling and stronger test-time scalability, surpassing CoT by 8.6% in Pass@1 and 6.3% in Pass@32 on competition-level benchmarks.
Sigma-MoE-Tiny Technical Report
Dec 19, 2025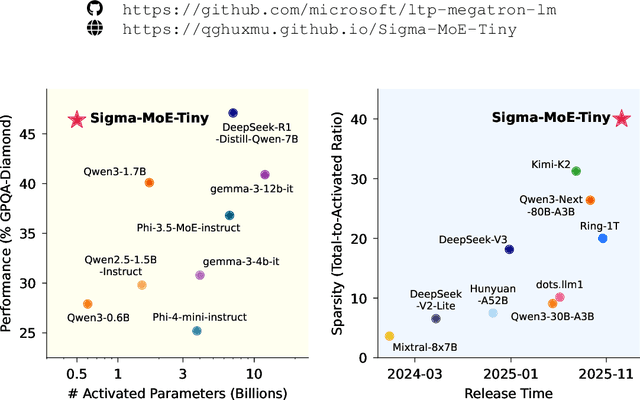

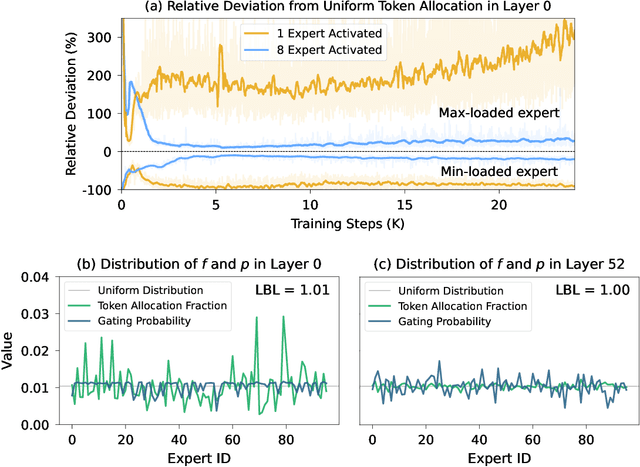
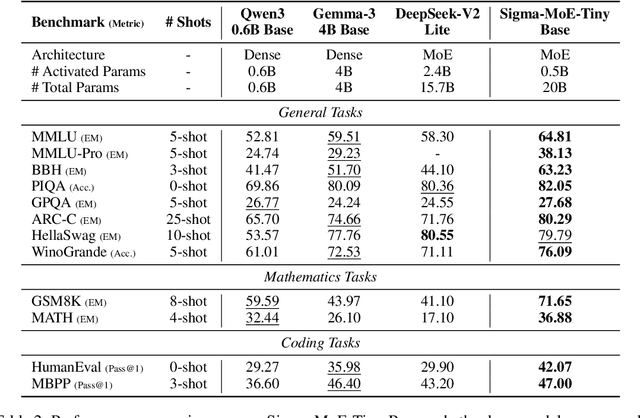
Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025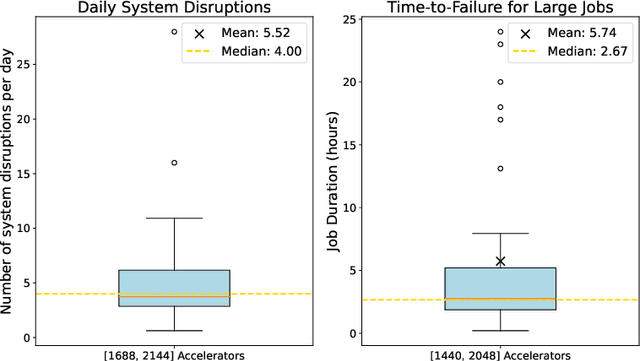

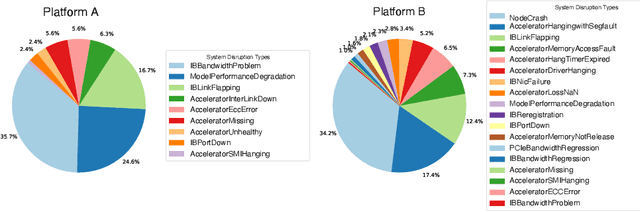

An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Generalized Category Discovery in Event-Centric Contexts: Latent Pattern Mining with LLMs
May 29, 2025Generalized Category Discovery (GCD) aims to classify both known and novel categories using partially labeled data that contains only known classes. Despite achieving strong performance on existing benchmarks, current textual GCD methods lack sufficient validation in realistic settings. We introduce Event-Centric GCD (EC-GCD), characterized by long, complex narratives and highly imbalanced class distributions, posing two main challenges: (1) divergent clustering versus classification groupings caused by subjective criteria, and (2) Unfair alignment for minority classes. To tackle these, we propose PaMA, a framework leveraging LLMs to extract and refine event patterns for improved cluster-class alignment. Additionally, a ranking-filtering-mining pipeline ensures balanced representation of prototypes across imbalanced categories. Evaluations on two EC-GCD benchmarks, including a newly constructed Scam Report dataset, demonstrate that PaMA outperforms prior methods with up to 12.58% H-score gains, while maintaining strong generalization on base GCD datasets.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
Dec 23, 2024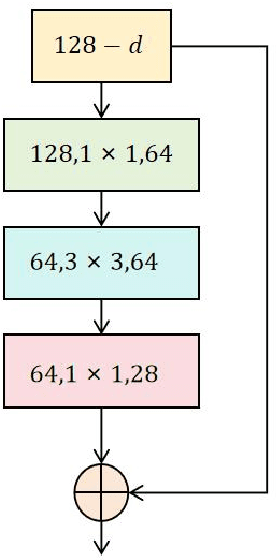

This study proposes a multi-task learning framework based on ResNeXt, aiming to solve the problem of feature extraction and task collaborative optimization in financial data mining. Financial data usually has the complex characteristics of high dimensionality, nonlinearity, and time series, and is accompanied by potential correlations between multiple tasks, making it difficult for traditional methods to meet the needs of data mining. This study introduces the ResNeXt model into the multi-task learning framework and makes full use of its group convolution mechanism to achieve efficient extraction of local patterns and global features of financial data. At the same time, through the design of task sharing layers and dedicated layers, it is established between multiple related tasks. Deep collaborative optimization relationships. Through flexible multi-task loss weight design, the model can effectively balance the learning needs of different tasks and improve overall performance. Experiments are conducted on a real S&P 500 financial data set, verifying the significant advantages of the proposed framework in classification and regression tasks. The results indicate that, when compared to other conventional deep learning models, the proposed method delivers superior performance in terms of accuracy, F1 score, root mean square error, and other metrics, highlighting its outstanding effectiveness and robustness in handling complex financial data. This research provides an efficient and adaptable solution for financial data mining, and at the same time opens up a new research direction for the combination of multi-task learning and deep learning, which has important theoretical significance and practical application value.
Integrative Analysis of Financial Market Sentiment Using CNN and GRU for Risk Prediction and Alert Systems
Dec 13, 2024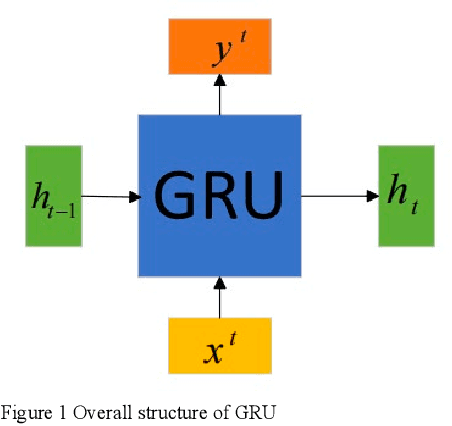
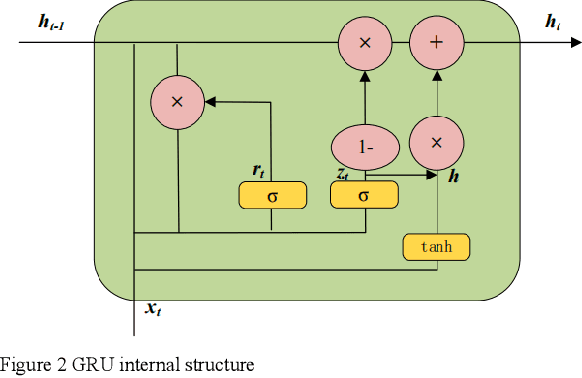
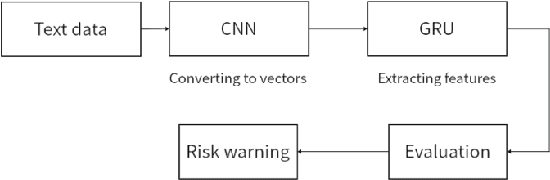
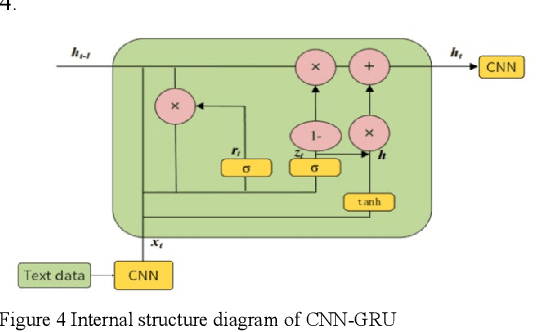
This document presents an in-depth examination of stock market sentiment through the integration of Convolutional Neural Networks (CNN) and Gated Recurrent Units (GRU), enabling precise risk alerts. The robust feature extraction capability of CNN is utilized to preprocess and analyze extensive network text data, identifying local features and patterns. The extracted feature sequences are then input into the GRU model to understand the progression of emotional states over time and their potential impact on future market sentiment and risk. This approach addresses the order dependence and long-term dependencies inherent in time series data, resulting in a detailed analysis of stock market sentiment and effective early warnings of future risks.
Revolutionizing Database Q&A with Large Language Models: Comprehensive Benchmark and Evaluation
Sep 05, 2024
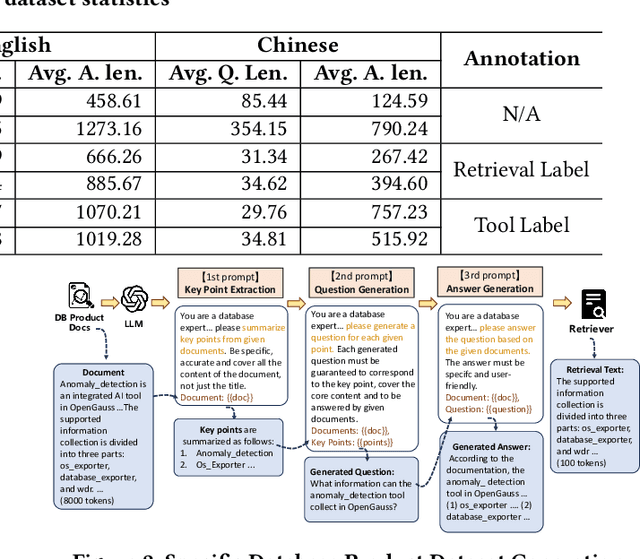
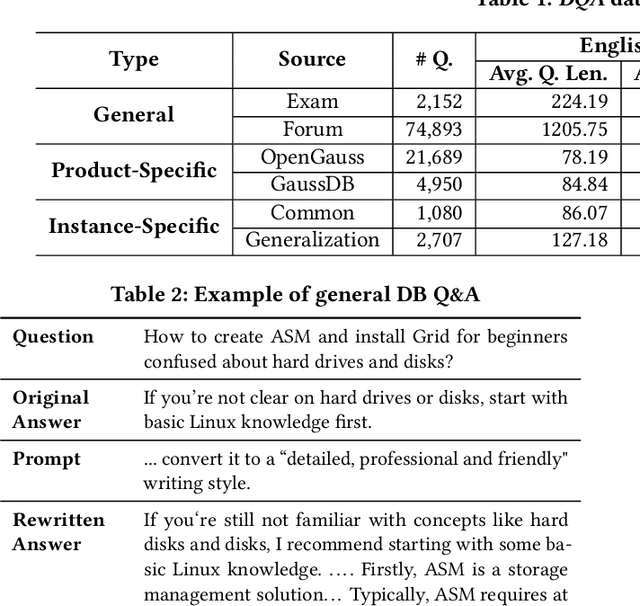

The development of Large Language Models (LLMs) has revolutionized Q&A across various industries, including the database domain. However, there is still a lack of a comprehensive benchmark to evaluate the capabilities of different LLMs and their modular components in database Q&A. To this end, we introduce DQA, the first comprehensive database Q&A benchmark. DQA features an innovative LLM-based method for automating the generation, cleaning, and rewriting of database Q&A, resulting in over 240,000 Q&A pairs in English and Chinese. These Q&A pairs cover nearly all aspects of database knowledge, including database manuals, database blogs, and database tools. This inclusion allows for additional assessment of LLMs' Retrieval-Augmented Generation (RAG) and Tool Invocation Generation (TIG) capabilities in the database Q&A task. Furthermore, we propose a comprehensive LLM-based database Q&A testbed on DQA. This testbed is highly modular and scalable, with both basic and advanced components like Question Classification Routing (QCR), RAG, TIG, and Prompt Template Engineering (PTE). Besides, DQA provides a complete evaluation pipeline, featuring diverse metrics and a standardized evaluation process to ensure comprehensiveness, accuracy, and fairness. We use DQA to evaluate the database Q&A capabilities under the proposed testbed comprehensively. The evaluation reveals findings like (i) the strengths and limitations of nine different LLM-based Q&A bots and (ii) the performance impact and potential improvements of various service components (e.g., QCR, RAG, TIG). We hope our benchmark and findings will better guide the future development of LLM-based database Q&A research.
Rho-1: Not All Tokens Are What You Need
Apr 11, 2024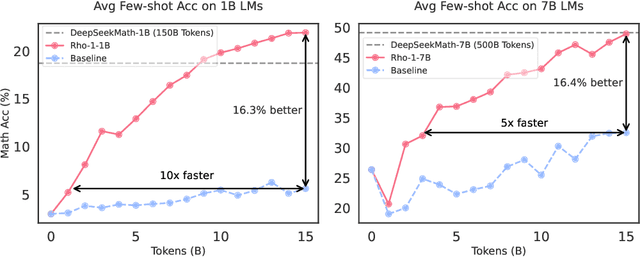
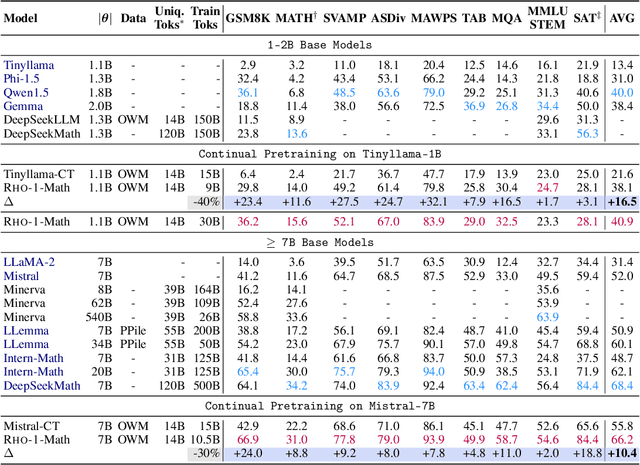
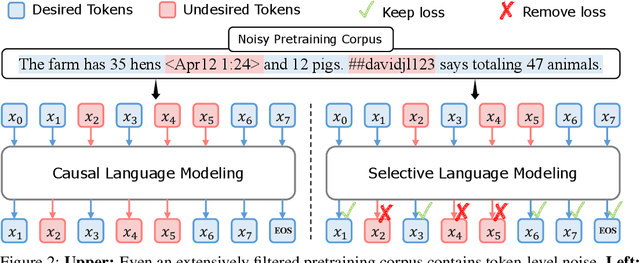
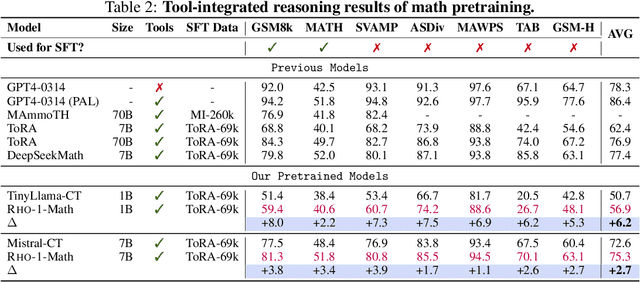
Previous language model pre-training methods have uniformly applied a next-token prediction loss to all training tokens. Challenging this norm, we posit that "Not all tokens in a corpus are equally important for language model training". Our initial analysis delves into token-level training dynamics of language model, revealing distinct loss patterns for different tokens. Leveraging these insights, we introduce a new language model called Rho-1. Unlike traditional LMs that learn to predict every next token in a corpus, Rho-1 employs Selective Language Modeling (SLM), which selectively trains on useful tokens that aligned with the desired distribution. This approach involves scoring pretraining tokens using a reference model, and then training the language model with a focused loss on tokens with higher excess loss. When continual pretraining on 15B OpenWebMath corpus, Rho-1 yields an absolute improvement in few-shot accuracy of up to 30% in 9 math tasks. After fine-tuning, Rho-1-1B and 7B achieved state-of-the-art results of 40.6% and 51.8% on MATH dataset, respectively - matching DeepSeekMath with only 3% of the pretraining tokens. Furthermore, when pretraining on 80B general tokens, Rho-1 achieves 6.8% average enhancement across 15 diverse tasks, increasing both efficiency and performance of the language model pre-training.
Ensuring Safe and High-Quality Outputs: A Guideline Library Approach for Language Models
Mar 23, 2024Large Language Models (LLMs) exhibit impressive capabilities but also present risks such as biased content generation and privacy issues. One of the current alignment techniques includes principle-driven integration, but it faces challenges arising from the imprecision of manually crafted rules and inadequate risk perception in models without safety training. To address these, we introduce Guide-Align, a two-stage approach. Initially, a safety-trained model identifies potential risks and formulates specific guidelines for various inputs, establishing a comprehensive library of guidelines and a model for input-guidelines retrieval. Subsequently, the retrieval model correlates new inputs with relevant guidelines, which guide LLMs in response generation to ensure safe and high-quality outputs, thereby aligning with human values. An additional optional stage involves fine-tuning a model with well-aligned datasets generated through the process implemented in the second stage. Our method customizes guidelines to accommodate diverse inputs, thereby enhancing the fine-grainedness and comprehensiveness of the guideline library. Furthermore, it incorporates safety expertise from a safety-trained LLM through a lightweight retrieval model. We evaluate our approach on three benchmarks, demonstrating significant improvements in LLM security and quality. Notably, our fine-tuned model, Labrador, even at 13 billion parameters, outperforms GPT-3.5-turbo and surpasses GPT-4 in alignment capabilities.