 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies
May 09, 2025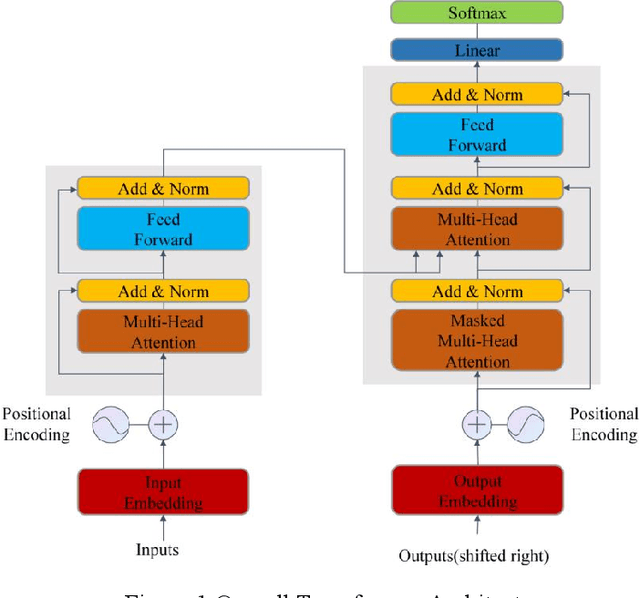
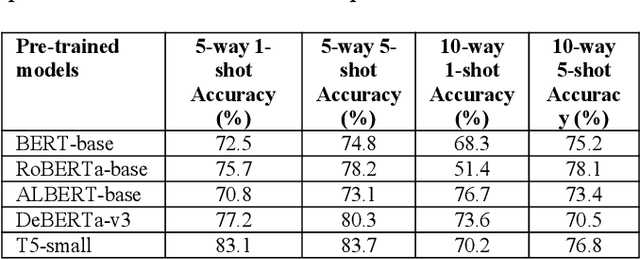
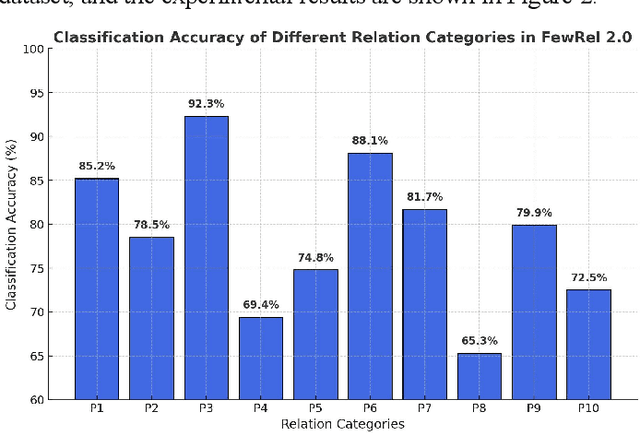
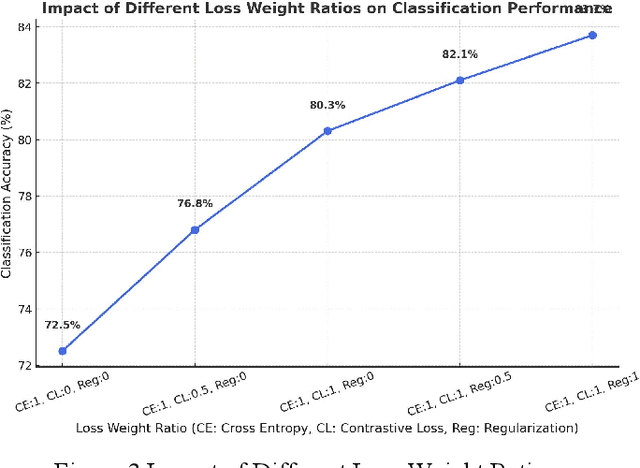
Few-shot text classification has important application value in low-resource environments. This paper proposes a strategy that combines adaptive fine-tuning, contrastive learning, and regularization optimization to improve the classification performance of Transformer-based models. Experiments on the FewRel 2.0 dataset show that T5-small, DeBERTa-v3, and RoBERTa-base perform well in few-shot tasks, especially in the 5-shot setting, which can more effectively capture text features and improve classification accuracy. The experiment also found that there are significant differences in the classification difficulty of different relationship categories. Some categories have fuzzy semantic boundaries or complex feature distributions, making it difficult for the standard cross entropy loss to learn the discriminative information required to distinguish categories. By introducing contrastive loss and regularization loss, the generalization ability of the model is enhanced, effectively alleviating the overfitting problem in few-shot environments. In addition, the research results show that the use of Transformer models or generative architectures with stronger self-attention mechanisms can help improve the stability and accuracy of few-shot classification.
Modeling Multi-Hop Semantic Paths for Recommendation in Heterogeneous Information Networks
May 09, 2025



This study focuses on the problem of path modeling in heterogeneous information networks and proposes a multi-hop path-aware recommendation framework. The method centers on multi-hop paths composed of various types of entities and relations. It models user preferences through three stages: path selection, semantic representation, and attention-based fusion. In the path selection stage, a path filtering mechanism is introduced to remove redundant and noisy information. In the representation learning stage, a sequential modeling structure is used to jointly encode entities and relations, preserving the semantic dependencies within paths. In the fusion stage, an attention mechanism assigns different weights to each path to generate a global user interest representation. Experiments conducted on real-world datasets such as Amazon-Book show that the proposed method significantly outperforms existing recommendation models across multiple evaluation metrics, including HR@10, Recall@10, and Precision@10. The results confirm the effectiveness of multi-hop paths in capturing high-order interaction semantics and demonstrate the expressive modeling capabilities of the framework in heterogeneous recommendation scenarios. This method provides both theoretical and practical value by integrating structural information modeling in heterogeneous networks with recommendation algorithm design. It offers a more expressive and flexible paradigm for learning user preferences in complex data environments.
Context-Guided Dynamic Retrieval for Improving Generation Quality in RAG Models
Apr 28, 2025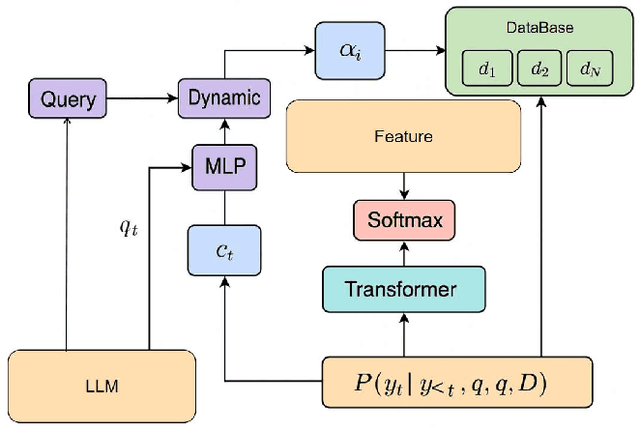
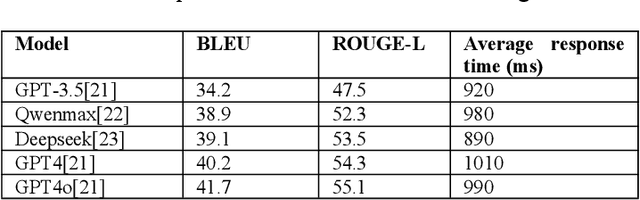
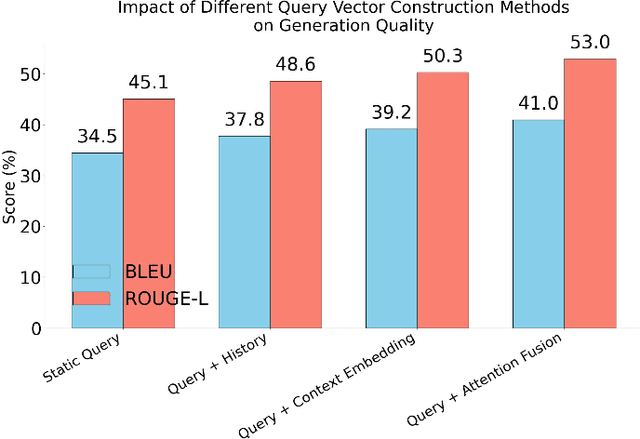
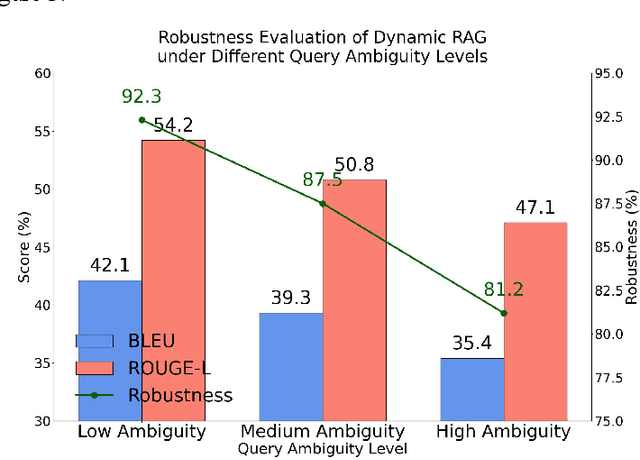
This paper focuses on the dynamic optimization of the Retrieval-Augmented Generation (RAG) architecture. It proposes a state-aware dynamic knowledge retrieval mechanism to enhance semantic understanding and knowledge scheduling efficiency in large language models for open-domain question answering and complex generation tasks. The method introduces a multi-level perceptive retrieval vector construction strategy and a differentiable document matching path. These components enable end-to-end joint training and collaborative optimization of the retrieval and generation modules. This effectively addresses the limitations of static RAG structures in context adaptation and knowledge access. Experiments are conducted on the Natural Questions dataset. The proposed structure is thoroughly evaluated across different large models, including GPT-4, GPT-4o, and DeepSeek. Comparative and ablation experiments from multiple perspectives confirm the significant improvements in BLEU and ROUGE-L scores. The approach also demonstrates stronger robustness and generation consistency in tasks involving semantic ambiguity and multi-document fusion. These results highlight its broad application potential and practical value in building high-quality language generation systems.
Pre-trained Language Models and Few-shot Learning for Medical Entity Extraction
Apr 06, 2025This study proposes a medical entity extraction method based on Transformer to enhance the information extraction capability of medical literature. Considering the professionalism and complexity of medical texts, we compare the performance of different pre-trained language models (BERT, BioBERT, PubMedBERT, ClinicalBERT) in medical entity extraction tasks. Experimental results show that PubMedBERT achieves the best performance (F1-score = 88.8%), indicating that a language model pre-trained on biomedical literature is more effective in the medical domain. In addition, we analyze the impact of different entity extraction methods (CRF, Span-based, Seq2Seq) and find that the Span-based approach performs best in medical entity extraction tasks (F1-score = 88.6%). It demonstrates superior accuracy in identifying entity boundaries. In low-resource scenarios, we further explore the application of Few-shot Learning in medical entity extraction. Experimental results show that even with only 10-shot training samples, the model achieves an F1-score of 79.1%, verifying the effectiveness of Few-shot Learning under limited data conditions. This study confirms that the combination of pre-trained language models and Few-shot Learning can enhance the accuracy of medical entity extraction. Future research can integrate knowledge graphs and active learning strategies to improve the model's generalization and stability, providing a more effective solution for medical NLP research. Keywords- Natural Language Processing, medical named entity recognition, pre-trained language model, Few-shot Learning, information extraction, deep learning
Semantic and Contextual Modeling for Malicious Comment Detection with BERT-BiLSTM
Mar 14, 2025



This study aims to develop an efficient and accurate model for detecting malicious comments, addressing the increasingly severe issue of false and harmful content on social media platforms. We propose a deep learning model that combines BERT and BiLSTM. The BERT model, through pre-training, captures deep semantic features of text, while the BiLSTM network excels at processing sequential data and can further model the contextual dependencies of text. Experimental results on the Jigsaw Unintended Bias in Toxicity Classification dataset demonstrate that the BERT+BiLSTM model achieves superior performance in malicious comment detection tasks, with a precision of 0.94, recall of 0.93, and accuracy of 0.94. This surpasses other models, including standalone BERT, TextCNN, TextRNN, and traditional machine learning algorithms using TF-IDF features. These results confirm the superiority of the BERT+BiLSTM model in handling imbalanced data and capturing deep semantic features of malicious comments, providing an effective technical means for social media content moderation and online environment purification.
A LongFormer-Based Framework for Accurate and Efficient Medical Text Summarization
Mar 10, 2025This paper proposes a medical text summarization method based on LongFormer, aimed at addressing the challenges faced by existing models when processing long medical texts. Traditional summarization methods are often limited by short-term memory, leading to information loss or reduced summary quality in long texts. LongFormer, by introducing long-range self-attention, effectively captures long-range dependencies in the text, retaining more key information and improving the accuracy and information retention of summaries. Experimental results show that the LongFormer-based model outperforms traditional models, such as RNN, T5, and BERT in automatic evaluation metrics like ROUGE. It also receives high scores in expert evaluations, particularly excelling in information retention and grammatical accuracy. However, there is still room for improvement in terms of conciseness and readability. Some experts noted that the generated summaries contain redundant information, which affects conciseness. Future research will focus on further optimizing the model structure to enhance conciseness and fluency, achieving more efficient medical text summarization. As medical data continues to grow, automated summarization technology will play an increasingly important role in fields such as medical research, clinical decision support, and knowledge management.
A Fine-Tuning Approach for T5 Using Knowledge Graphs to Address Complex Tasks
Feb 23, 2025



With the development of deep learning technology, large language models have achieved remarkable results in many natural language processing tasks. However, these models still have certain limitations in handling complex reasoning tasks and understanding rich background knowledge. To solve this problem, this study proposed a T5 model fine-tuning method based on knowledge graphs, which enhances the model's reasoning ability and context understanding ability by introducing external knowledge graphs. We used the SQuAD1.1 dataset for experiments. The experimental results show that the T5 model based on knowledge graphs is significantly better than other baseline models in reasoning accuracy, context understanding, and the ability to handle complex problems. At the same time, we also explored the impact of knowledge graphs of different scales on model performance and found that as the scale of the knowledge graph increases, the performance of the model gradually improves. Especially when dealing with complex problems, the introduction of knowledge graphs greatly improves the reasoning ability of the T5 model. Ablation experiments further verify the importance of entity and relationship embedding in the model and prove that a complete knowledge graph is crucial to improving the various capabilities of the T5 model. In summary, this study provides an effective method to enhance the reasoning and understanding capabilities of large language models and provides new directions for future research.
A Hybrid Model for Few-Shot Text Classification Using Transfer and Meta-Learning
Feb 13, 2025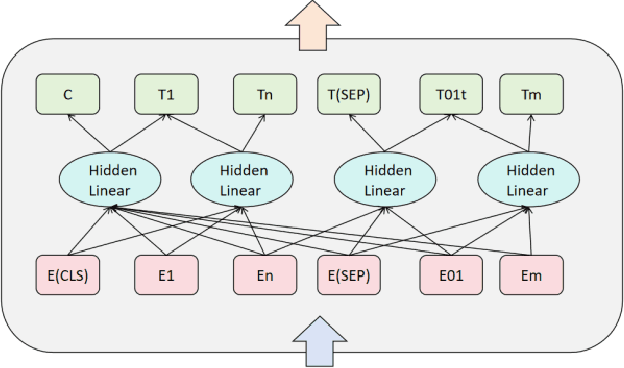
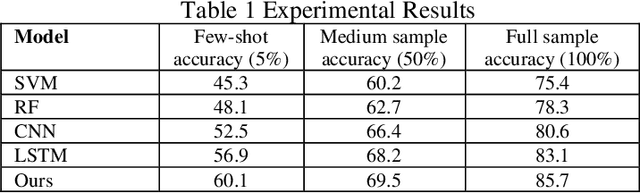
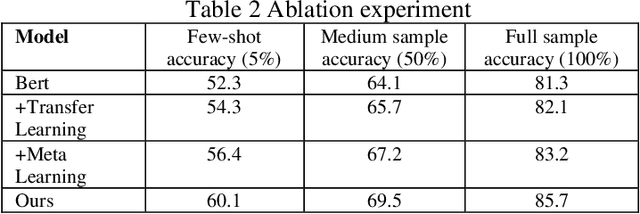
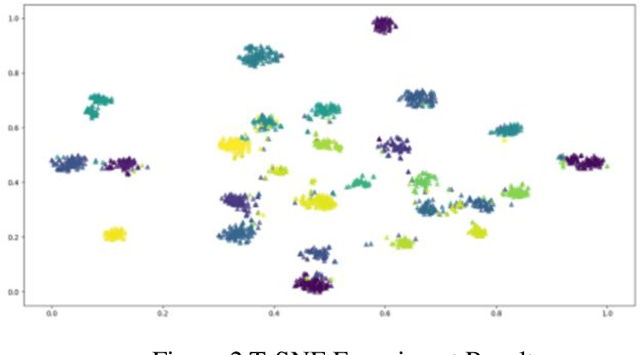
With the continuous development of natural language processing (NLP) technology, text classification tasks have been widely used in multiple application fields. However, obtaining labeled data is often expensive and difficult, especially in few-shot learning scenarios. To solve this problem, this paper proposes a few-shot text classification model based on transfer learning and meta-learning. The model uses the knowledge of the pre-trained model for transfer and optimizes the model's rapid adaptability in few-sample tasks through a meta-learning mechanism. Through a series of comparative experiments and ablation experiments, we verified the effectiveness of the proposed method. The experimental results show that under the conditions of few samples and medium samples, the model based on transfer learning and meta-learning significantly outperforms traditional machine learning and deep learning methods. In addition, ablation experiments further analyzed the contribution of each component to the model performance and confirmed the key role of transfer learning and meta-learning in improving model accuracy. Finally, this paper discusses future research directions and looks forward to the potential of this method in practical applications.
Dynamic Adaptation of LoRA Fine-Tuning for Efficient and Task-Specific Optimization of Large Language Models
Jan 24, 2025



This paper presents a novel methodology of fine-tuning for large language models-dynamic LoRA. Building from the standard Low-Rank Adaptation framework, this methodology further adds dynamic adaptation mechanisms to improve efficiency and performance. The key contribution of dynamic LoRA lies within its adaptive weight allocation mechanism coupled with an input feature-based adaptive strategy. These enhancements allow for a more precise fine-tuning process that is more tailored to specific tasks. Traditional LoRA methods use static adapter settings, not considering the different importance of model layers. In contrast, dynamic LoRA introduces a mechanism that dynamically evaluates the layer's importance during fine-tuning. This evaluation enables the reallocation of adapter parameters to fit the unique demands of each individual task, which leads to better optimization results. Another gain in flexibility arises from the consideration of the input feature distribution, which helps the model generalize better when faced with complicated and diverse datasets. The joint approach boosts not only the performance over each single task but also the generalization ability of the model. The efficiency of the dynamic LoRA was validated in experiments on benchmark datasets, such as GLUE, with surprising results. More specifically, this method achieved 88.1% accuracy with an F1-score of 87.3%. Noticeably, these improvements were made at a slight increase in computational costs: only 0.1% more resources than standard LoRA. This balance between performance and efficiency positions dynamic LoRA as a practical, scalable solution for fine-tuning LLMs, especially in resource-constrained scenarios. To take it a step further, its adaptability makes it a promising foundation for much more advanced applications, including multimodal tasks.
Feature Alignment-Based Knowledge Distillation for Efficient Compression of Large Language Models
Dec 27, 2024


This study proposes a knowledge distillation algorithm based on large language models and feature alignment, aiming to effectively transfer the knowledge of large pre-trained models into lightweight student models, thereby reducing computational costs while maintaining high model performance. Different from the traditional soft label distillation method, this method introduces a multi-layer feature alignment strategy to deeply align the intermediate features and attention mechanisms of the teacher model and the student model, maximally retaining the semantic expression ability and context modeling ability of the teacher model. In terms of method design, a multi-task loss function is constructed, including feature matching loss, attention alignment loss, and output distribution matching loss, to ensure multi-level information transfer through joint optimization. The experiments were comprehensively evaluated on the GLUE data set and various natural language processing tasks. The results show that the proposed model performs very close to the state-of-the-art GPT-4 model in terms of evaluation indicators such as perplexity, BLEU, ROUGE, and CER. At the same time, it far exceeds baseline models such as DeBERTa, XLNet, and GPT-3, showing significant performance improvements and computing efficiency advantages. Research results show that the feature alignment distillation strategy is an effective model compression method that can significantly reduce computational overhead and storage requirements while maintaining model capabilities. Future research can be further expanded in the directions of self-supervised learning, cross-modal feature alignment, and multi-task transfer learning to provide more flexible and efficient solutions for the deployment and optimization of deep learning models.