 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Guided Dynamic Retrieval for Improving Generation Quality in RAG Models
Apr 28, 2025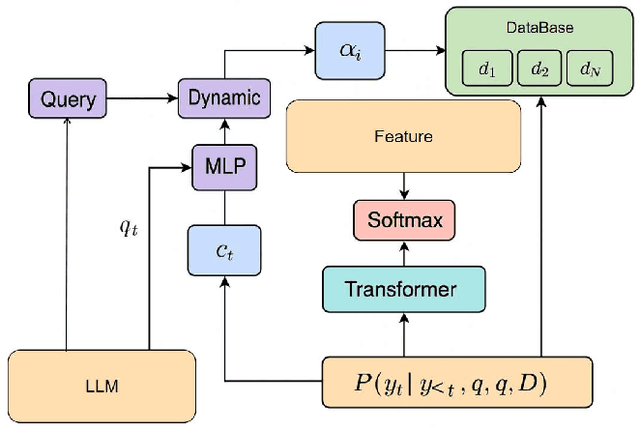
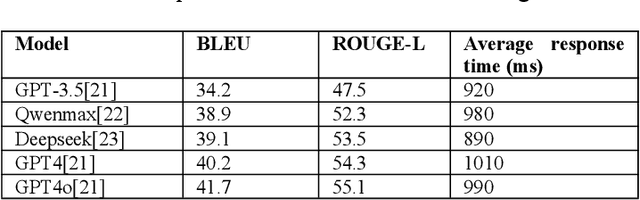
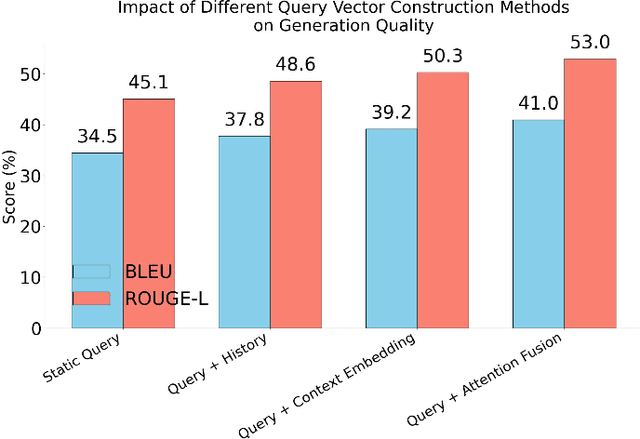
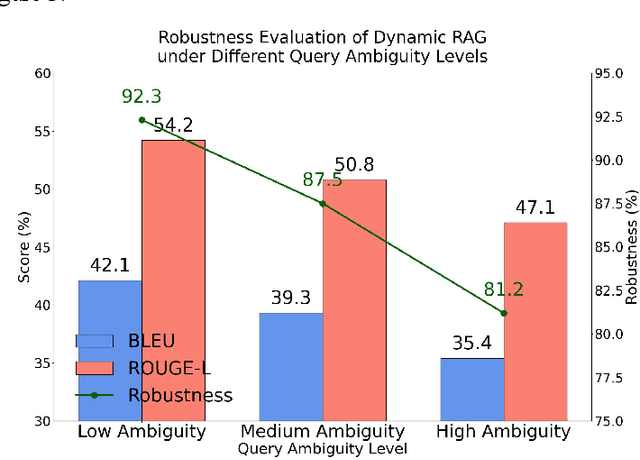
This paper focuses on the dynamic optimization of the Retrieval-Augmented Generation (RAG) architecture. It proposes a state-aware dynamic knowledge retrieval mechanism to enhance semantic understanding and knowledge scheduling efficiency in large language models for open-domain question answering and complex generation tasks. The method introduces a multi-level perceptive retrieval vector construction strategy and a differentiable document matching path. These components enable end-to-end joint training and collaborative optimization of the retrieval and generation modules. This effectively addresses the limitations of static RAG structures in context adaptation and knowledge access. Experiments are conducted on the Natural Questions dataset. The proposed structure is thoroughly evaluated across different large models, including GPT-4, GPT-4o, and DeepSeek. Comparative and ablation experiments from multiple perspectives confirm the significant improvements in BLEU and ROUGE-L scores. The approach also demonstrates stronger robustness and generation consistency in tasks involving semantic ambiguity and multi-document fusion. These results highlight its broad application potential and practical value in building high-quality language generation systems.
Pre-trained Language Models and Few-shot Learning for Medical Entity Extraction
Apr 06, 2025This study proposes a medical entity extraction method based on Transformer to enhance the information extraction capability of medical literature. Considering the professionalism and complexity of medical texts, we compare the performance of different pre-trained language models (BERT, BioBERT, PubMedBERT, ClinicalBERT) in medical entity extraction tasks. Experimental results show that PubMedBERT achieves the best performance (F1-score = 88.8%), indicating that a language model pre-trained on biomedical literature is more effective in the medical domain. In addition, we analyze the impact of different entity extraction methods (CRF, Span-based, Seq2Seq) and find that the Span-based approach performs best in medical entity extraction tasks (F1-score = 88.6%). It demonstrates superior accuracy in identifying entity boundaries. In low-resource scenarios, we further explore the application of Few-shot Learning in medical entity extraction. Experimental results show that even with only 10-shot training samples, the model achieves an F1-score of 79.1%, verifying the effectiveness of Few-shot Learning under limited data conditions. This study confirms that the combination of pre-trained language models and Few-shot Learning can enhance the accuracy of medical entity extraction. Future research can integrate knowledge graphs and active learning strategies to improve the model's generalization and stability, providing a more effective solution for medical NLP research. Keywords- Natural Language Processing, medical named entity recognition, pre-trained language model, Few-shot Learning, information extraction, deep learning
Semantic and Contextual Modeling for Malicious Comment Detection with BERT-BiLSTM
Mar 14, 2025



This study aims to develop an efficient and accurate model for detecting malicious comments, addressing the increasingly severe issue of false and harmful content on social media platforms. We propose a deep learning model that combines BERT and BiLSTM. The BERT model, through pre-training, captures deep semantic features of text, while the BiLSTM network excels at processing sequential data and can further model the contextual dependencies of text. Experimental results on the Jigsaw Unintended Bias in Toxicity Classification dataset demonstrate that the BERT+BiLSTM model achieves superior performance in malicious comment detection tasks, with a precision of 0.94, recall of 0.93, and accuracy of 0.94. This surpasses other models, including standalone BERT, TextCNN, TextRNN, and traditional machine learning algorithms using TF-IDF features. These results confirm the superiority of the BERT+BiLSTM model in handling imbalanced data and capturing deep semantic features of malicious comments, providing an effective technical means for social media content moderation and online environment purification.
A LongFormer-Based Framework for Accurate and Efficient Medical Text Summarization
Mar 10, 2025This paper proposes a medical text summarization method based on LongFormer, aimed at addressing the challenges faced by existing models when processing long medical texts. Traditional summarization methods are often limited by short-term memory, leading to information loss or reduced summary quality in long texts. LongFormer, by introducing long-range self-attention, effectively captures long-range dependencies in the text, retaining more key information and improving the accuracy and information retention of summaries. Experimental results show that the LongFormer-based model outperforms traditional models, such as RNN, T5, and BERT in automatic evaluation metrics like ROUGE. It also receives high scores in expert evaluations, particularly excelling in information retention and grammatical accuracy. However, there is still room for improvement in terms of conciseness and readability. Some experts noted that the generated summaries contain redundant information, which affects conciseness. Future research will focus on further optimizing the model structure to enhance conciseness and fluency, achieving more efficient medical text summarization. As medical data continues to grow, automated summarization technology will play an increasingly important role in fields such as medical research, clinical decision support, and knowledge management.
A Fine-Tuning Approach for T5 Using Knowledge Graphs to Address Complex Tasks
Feb 23, 2025



With the development of deep learning technology, large language models have achieved remarkable results in many natural language processing tasks. However, these models still have certain limitations in handling complex reasoning tasks and understanding rich background knowledge. To solve this problem, this study proposed a T5 model fine-tuning method based on knowledge graphs, which enhances the model's reasoning ability and context understanding ability by introducing external knowledge graphs. We used the SQuAD1.1 dataset for experiments. The experimental results show that the T5 model based on knowledge graphs is significantly better than other baseline models in reasoning accuracy, context understanding, and the ability to handle complex problems. At the same time, we also explored the impact of knowledge graphs of different scales on model performance and found that as the scale of the knowledge graph increases, the performance of the model gradually improves. Especially when dealing with complex problems, the introduction of knowledge graphs greatly improves the reasoning ability of the T5 model. Ablation experiments further verify the importance of entity and relationship embedding in the model and prove that a complete knowledge graph is crucial to improving the various capabilities of the T5 model. In summary, this study provides an effective method to enhance the reasoning and understanding capabilities of large language models and provides new directions for future research.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm