 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic and Structural Analysis of Implicit Biases in Large Language Models: An Interpretable Approach
Aug 08, 2025This paper addresses the issue of implicit stereotypes that may arise during the generation process of large language models. It proposes an interpretable bias detection method aimed at identifying hidden social biases in model outputs, especially those semantic tendencies that are not easily captured through explicit linguistic features. The method combines nested semantic representation with a contextual contrast mechanism. It extracts latent bias features from the vector space structure of model outputs. Using attention weight perturbation, it analyzes the model's sensitivity to specific social attribute terms, thereby revealing the semantic pathways through which bias is formed. To validate the effectiveness of the method, this study uses the StereoSet dataset, which covers multiple stereotype dimensions including gender, profession, religion, and race. The evaluation focuses on several key metrics, such as bias detection accuracy, semantic consistency, and contextual sensitivity. Experimental results show that the proposed method achieves strong detection performance across various dimensions. It can accurately identify bias differences between semantically similar texts while maintaining high semantic alignment and output stability. The method also demonstrates high interpretability in its structural design. It helps uncover the internal bias association mechanisms within language models. This provides a more transparent and reliable technical foundation for bias detection. The approach is suitable for real-world applications where high trustworthiness of generated content is required.
Semantic and Contextual Modeling for Malicious Comment Detection with BERT-BiLSTM
Mar 14, 2025



This study aims to develop an efficient and accurate model for detecting malicious comments, addressing the increasingly severe issue of false and harmful content on social media platforms. We propose a deep learning model that combines BERT and BiLSTM. The BERT model, through pre-training, captures deep semantic features of text, while the BiLSTM network excels at processing sequential data and can further model the contextual dependencies of text. Experimental results on the Jigsaw Unintended Bias in Toxicity Classification dataset demonstrate that the BERT+BiLSTM model achieves superior performance in malicious comment detection tasks, with a precision of 0.94, recall of 0.93, and accuracy of 0.94. This surpasses other models, including standalone BERT, TextCNN, TextRNN, and traditional machine learning algorithms using TF-IDF features. These results confirm the superiority of the BERT+BiLSTM model in handling imbalanced data and capturing deep semantic features of malicious comments, providing an effective technical means for social media content moderation and online environment purification.
A LongFormer-Based Framework for Accurate and Efficient Medical Text Summarization
Mar 10, 2025This paper proposes a medical text summarization method based on LongFormer, aimed at addressing the challenges faced by existing models when processing long medical texts. Traditional summarization methods are often limited by short-term memory, leading to information loss or reduced summary quality in long texts. LongFormer, by introducing long-range self-attention, effectively captures long-range dependencies in the text, retaining more key information and improving the accuracy and information retention of summaries. Experimental results show that the LongFormer-based model outperforms traditional models, such as RNN, T5, and BERT in automatic evaluation metrics like ROUGE. It also receives high scores in expert evaluations, particularly excelling in information retention and grammatical accuracy. However, there is still room for improvement in terms of conciseness and readability. Some experts noted that the generated summaries contain redundant information, which affects conciseness. Future research will focus on further optimizing the model structure to enhance conciseness and fluency, achieving more efficient medical text summarization. As medical data continues to grow, automated summarization technology will play an increasingly important role in fields such as medical research, clinical decision support, and knowledge management.
Generating Multimodal Images with GAN: Integrating Text, Image, and Style
Jan 04, 2025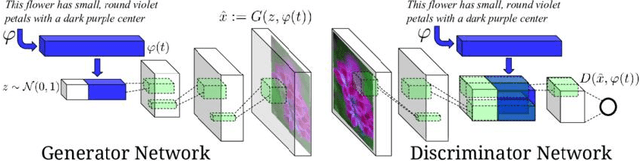
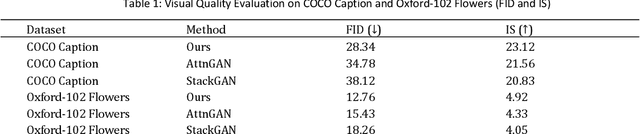
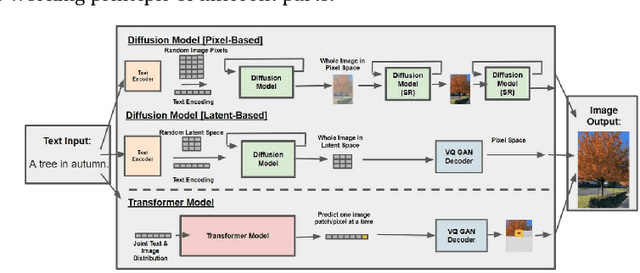

In the field of computer vision, multimodal image generation has become a research hotspot, especially the task of integrating text, image, and style. In this study, we propose a multimodal image generation method based on Generative Adversarial Networks (GAN), capable of effectively combining text descriptions, reference images, and style information to generate images that meet multimodal requirements. This method involves the design of a text encoder, an image feature extractor, and a style integration module, ensuring that the generated images maintain high quality in terms of visual content and style consistency. We also introduce multiple loss functions, including adversarial loss, text-image consistency loss, and style matching loss, to optimize the generation process. Experimental results show that our method produces images with high clarity and consistency across multiple public datasets, demonstrating significant performance improvements compared to existing methods. The outcomes of this study provide new insights into multimodal image generation and present broad application prospects.
Feature Alignment-Based Knowledge Distillation for Efficient Compression of Large Language Models
Dec 27, 2024


This study proposes a knowledge distillation algorithm based on large language models and feature alignment, aiming to effectively transfer the knowledge of large pre-trained models into lightweight student models, thereby reducing computational costs while maintaining high model performance. Different from the traditional soft label distillation method, this method introduces a multi-layer feature alignment strategy to deeply align the intermediate features and attention mechanisms of the teacher model and the student model, maximally retaining the semantic expression ability and context modeling ability of the teacher model. In terms of method design, a multi-task loss function is constructed, including feature matching loss, attention alignment loss, and output distribution matching loss, to ensure multi-level information transfer through joint optimization. The experiments were comprehensively evaluated on the GLUE data set and various natural language processing tasks. The results show that the proposed model performs very close to the state-of-the-art GPT-4 model in terms of evaluation indicators such as perplexity, BLEU, ROUGE, and CER. At the same time, it far exceeds baseline models such as DeBERTa, XLNet, and GPT-3, showing significant performance improvements and computing efficiency advantages. Research results show that the feature alignment distillation strategy is an effective model compression method that can significantly reduce computational overhead and storage requirements while maintaining model capabilities. Future research can be further expanded in the directions of self-supervised learning, cross-modal feature alignment, and multi-task transfer learning to provide more flexible and efficient solutions for the deployment and optimization of deep learning models.
Optimizing Large Language Models with an Enhanced LoRA Fine-Tuning Algorithm for Efficiency and Robustness in NLP Tasks
Dec 25, 2024


This study proposes a large language model optimization method based on the improved LoRA fine-tuning algorithm, aiming to improve the accuracy and computational efficiency of the model in natural language processing tasks. We fine-tune the large language model through a low-rank adaptation strategy, which significantly reduces the consumption of computing resources while maintaining the powerful capabilities of the pre-trained model. The experiment uses the QQP task as the evaluation scenario. The results show that the improved LoRA algorithm shows significant improvements in accuracy, F1 score, and MCC compared with traditional models such as BERT, Roberta, T5, and GPT-4. In particular, in terms of F1 score and MCC, our model shows stronger robustness and discrimination ability, which proves the potential of the improved LoRA algorithm in fine-tuning large-scale pre-trained models. In addition, this paper also discusses the application prospects of the improved LoRA algorithm in other natural language processing tasks, emphasizing its advantages in multi-task learning and scenarios with limited computing resources. Future research can further optimize the LoRA fine-tuning strategy and expand its application in larger-scale pre-trained models to improve the generalization ability and task adaptability of the model.
Detecting and Classifying Defective Products in Images Using YOLO
Dec 22, 2024



With the continuous advancement of industrial automation, product quality inspection has become increasingly important in the manufacturing process. Traditional inspection methods, which often rely on manual checks or simple machine vision techniques, suffer from low efficiency and insufficient accuracy. In recent years, deep learning technology, especially the YOLO (You Only Look Once) algorithm, has emerged as a prominent solution in the field of product defect detection due to its efficient real-time detection capabilities and excellent classification performance. This study aims to use the YOLO algorithm to detect and classify defects in product images. By constructing and training a YOLO model, we conducted experiments on multiple industrial product datasets. The results demonstrate that this method can achieve real-time detection while maintaining high detection accuracy, significantly improving the efficiency and accuracy of product quality inspection. This paper further analyzes the advantages and limitations of the YOLO algorithm in practical applications and explores future research directions.
DTSGAN: Learning Dynamic Textures via Spatiotemporal Generative Adversarial Network
Dec 22, 2024



Dynamic texture synthesis aims to generate sequences that are visually similar to a reference video texture and exhibit specific stationary properties in time. In this paper, we introduce a spatiotemporal generative adversarial network (DTSGAN) that can learn from a single dynamic texture by capturing its motion and content distribution. With the pipeline of DTSGAN, a new video sequence is generated from the coarsest scale to the finest one. To avoid mode collapse, we propose a novel strategy for data updates that helps improve the diversity of generated results. Qualitative and quantitative experiments show that our model is able to generate high quality dynamic textures and natural motion.
Optimizing Multi-Task Learning for Enhanced Performance in Large Language Models
Dec 09, 2024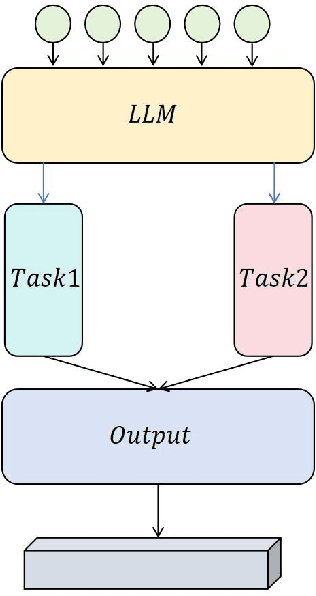
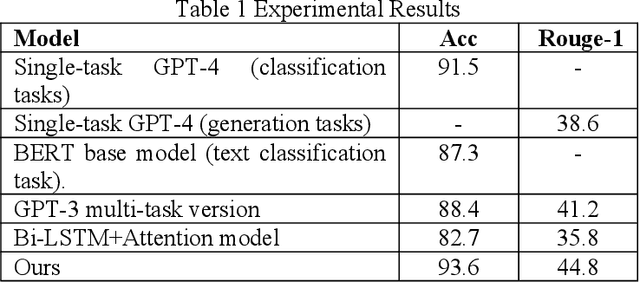

This study aims to explore the performance improvement method of large language models based on GPT-4 under the multi-task learning framework and conducts experiments on two tasks: text classification and automatic summary generation. Through the combined design of shared feature extractors and task-specific modules, we achieve knowledge-sharing and optimization of multiple tasks in the same model. The experiment uses multiple subtasks of the GLUE dataset to compare the performance of the multi-task model with the single-task GPT-4, the multi-task version of GPT-3, the BERT basic model, and the classic Bi-LSTM with Attention model. The results show that the proposed multi-task learning model outperforms other comparison models in terms of text classification accuracy and ROUGE value of summary generation, demonstrating the advantages of multi-task learning in improving model generalization ability and collaborative learning between tasks. The model maintains a stable loss convergence rate during training, showing good learning efficiency and adaptability to the test set. This study verifies the applicability of the multi-task learning framework in large language models, especially in improving the model's ability to balance different tasks. In the future, with the combination of large language models and multimodal data and the application of dynamic task adjustment technology, the framework based on multi-task learning is expected to play a greater role in practical applications across fields and provide new ideas for the development of general artificial intelligence.
Few-Shot Learning with Adaptive Weight Masking in Conditional GANs
Dec 04, 2024



Deep learning has revolutionized various fields, yet its efficacy is hindered by overfitting and the requirement of extensive annotated data, particularly in few-shot learning scenarios where limited samples are available. This paper introduces a novel approach to few-shot learning by employing a Residual Weight Masking Conditional Generative Adversarial Network (RWM-CGAN) for data augmentation. The proposed model integrates residual units within the generator to enhance network depth and sample quality, coupled with a weight mask regularization technique in the discriminator to improve feature learning from small-sample categories. This method addresses the core issues of robustness and generalization in few-shot learning by providing a controlled and clear augmentation of the sample space. Extensive experiments demonstrate that RWM-CGAN not only expands the sample space effectively but also enriches the diversity and quality of generated samples, leading to significant improvements in detection and classification accuracy on public datasets. The paper contributes to the advancement of few-shot learning by offering a practical solution to the challenges posed by data scarcity and the need for rapid generalization to new tasks or categories.