 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Multi-Task Learning for Enhanced Performance in Large Language Models
Dec 09, 2024
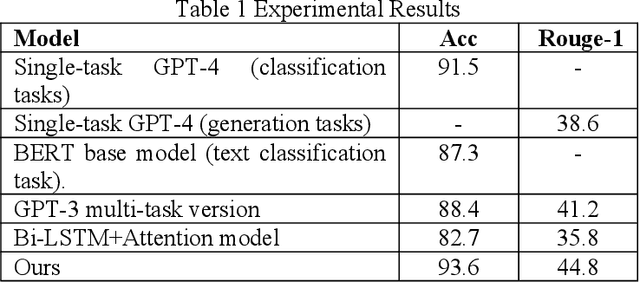

This study aims to explore the performance improvement method of large language models based on GPT-4 under the multi-task learning framework and conducts experiments on two tasks: text classification and automatic summary generation. Through the combined design of shared feature extractors and task-specific modules, we achieve knowledge-sharing and optimization of multiple tasks in the same model. The experiment uses multiple subtasks of the GLUE dataset to compare the performance of the multi-task model with the single-task GPT-4, the multi-task version of GPT-3, the BERT basic model, and the classic Bi-LSTM with Attention model. The results show that the proposed multi-task learning model outperforms other comparison models in terms of text classification accuracy and ROUGE value of summary generation, demonstrating the advantages of multi-task learning in improving model generalization ability and collaborative learning between tasks. The model maintains a stable loss convergence rate during training, showing good learning efficiency and adaptability to the test set. This study verifies the applicability of the multi-task learning framework in large language models, especially in improving the model's ability to balance different tasks. In the future, with the combination of large language models and multimodal data and the application of dynamic task adjustment technology, the framework based on multi-task learning is expected to play a greater role in practical applications across fields and provide new ideas for the development of general artificial intelligence.
Adaptive Optimization for Enhanced Efficiency in Large-Scale Language Model Training
Dec 06, 2024



With the rapid development of natural language processing technology, large-scale language models (LLM) have achieved remarkable results in a variety of tasks. However, how to effectively train these huge models and improve their performance and computational efficiency remains an important challenge. This paper proposes an improved method based on adaptive optimization algorithm, aiming to improve the training efficiency and final performance of LLM. Through comparative experiments on the SQuAD and GLUE data sets, the experimental results show that compared with traditional optimization algorithms (such as SGD, Momentum, AdaGrad, RMSProp and Adam), the adaptive optimization algorithm we proposed has better accuracy and F1 score. Both have achieved significant improvements, especially showed stronger training capabilities when processed large-scale texts and complex tasks. The research results verify the advantages of adaptive optimization algorithms in large-scale language model training and provide new ideas and directions for future optimization methods.
Research on Key Technologies for Cross-Cloud Federated Training of Large Language Models
Oct 24, 2024With the rapid development of natural language processing technology, large language models have demonstrated exceptional performance in various application scenarios. However, training these models requires significant computational resources and data processing capabilities. Cross-cloud federated training offers a new approach to addressing the resource bottlenecks of a single cloud platform, allowing the computational resources of multiple clouds to collaboratively complete the training tasks of large models. This study analyzes the key technologies of cross-cloud federated training, including data partitioning and distribution, communication optimization, model aggregation algorithms, and the compatibility of heterogeneous cloud platforms. Additionally, the study examines data security and privacy protection strategies in cross-cloud training, particularly the application of data encryption and differential privacy techniques. Through experimental validation, the proposed technical framework demonstrates enhanced training efficiency, ensured data security, and reduced training costs, highlighting the broad application prospects of cross-cloud federated training.