 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on Key Technologies for Cross-Cloud Federated Training of Large Language Models
Oct 24, 2024With the rapid development of natural language processing technology, large language models have demonstrated exceptional performance in various application scenarios. However, training these models requires significant computational resources and data processing capabilities. Cross-cloud federated training offers a new approach to addressing the resource bottlenecks of a single cloud platform, allowing the computational resources of multiple clouds to collaboratively complete the training tasks of large models. This study analyzes the key technologies of cross-cloud federated training, including data partitioning and distribution, communication optimization, model aggregation algorithms, and the compatibility of heterogeneous cloud platforms. Additionally, the study examines data security and privacy protection strategies in cross-cloud training, particularly the application of data encryption and differential privacy techniques. Through experimental validation, the proposed technical framework demonstrates enhanced training efficiency, ensured data security, and reduced training costs, highlighting the broad application prospects of cross-cloud federated training.
Analysis and Design of a Personalized Recommendation System Based on a Dynamic User Interest Model
Oct 13, 2024With the rapid development of the internet and the explosion of information, providing users with accurate personalized recommendations has become an important research topic. This paper designs and analyzes a personalized recommendation system based on a dynamic user interest model. The system captures user behavior data, constructs a dynamic user interest model, and combines multiple recommendation algorithms to provide personalized content to users. The research results show that this system significantly improves recommendation accuracy and user satisfaction. This paper discusses the system's architecture design, algorithm implementation, and experimental results in detail and explores future research directions.
Deep Learning-Based Channel Squeeze U-Structure for Lung Nodule Detection and Segmentation
Sep 20, 2024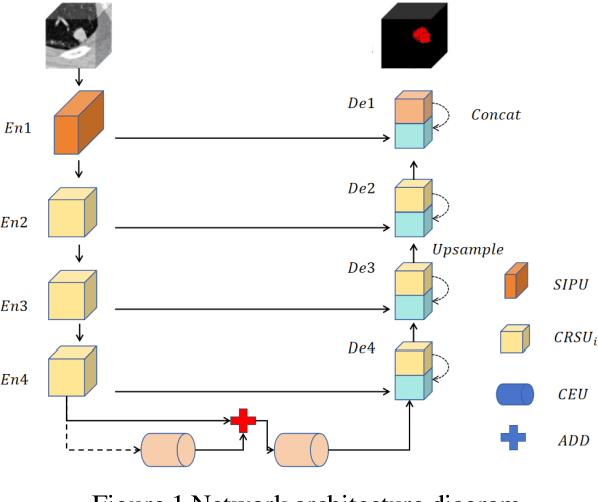
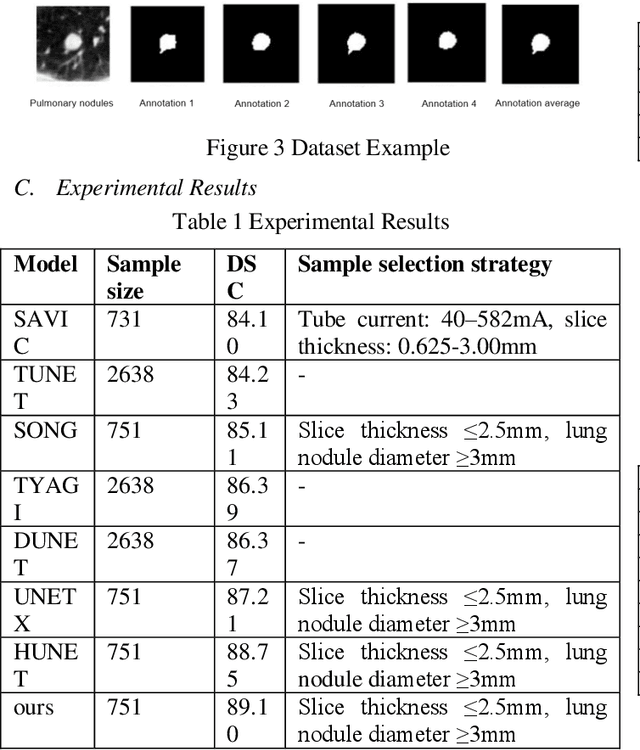
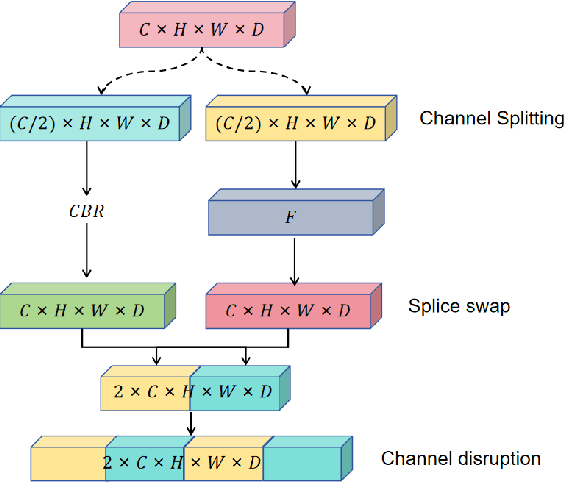
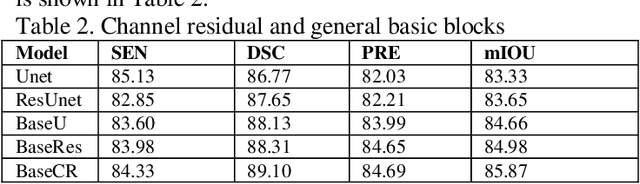
This paper introduces a novel deep-learning method for the automatic detection and segmentation of lung nodules, aimed at advancing the accuracy of early-stage lung cancer diagnosis. The proposed approach leverages a unique "Channel Squeeze U-Structure" that optimizes feature extraction and information integration across multiple semantic levels of the network. This architecture includes three key modules: shallow information processing, channel residual structure, and channel squeeze integration. These modules enhance the model's ability to detect and segment small, imperceptible, or ground-glass nodules, which are critical for early diagnosis. The method demonstrates superior performance in terms of sensitivity, Dice similarity coefficient, precision, and mean Intersection over Union (IoU). Extensive experiments were conducted on the Lung Image Database Consortium (LIDC) dataset using five-fold cross-validation, showing excellent stability and robustness. The results indicate that this approach holds significant potential for improving computer-aided diagnosis systems, providing reliable support for radiologists in clinical practice and aiding in the early detection of lung cancer, especially in resource-limited settings
Enhancing Convolutional Neural Networks with Higher-Order Numerical Difference Methods
Sep 08, 2024

With the rise of deep learning technology in practical applications, Convolutional Neural Networks (CNNs) have been able to assist humans in solving many real-world problems. To enhance the performance of CNNs, numerous network architectures have been explored. Some of these architectures are designed based on the accumulated experience of researchers over time, while others are designed through neural architecture search methods. The improvements made to CNNs by the aforementioned methods are quite significant, but most of the improvement methods are limited in reality by model size and environmental constraints, making it difficult to fully realize the improved performance. In recent years, research has found that many CNN structures can be explained by the discretization of ordinary differential equations. This implies that we can design theoretically supported deep network structures using higher-order numerical difference methods. It should be noted that most of the previous CNN model structures are based on low-order numerical methods. Therefore, considering that the accuracy of linear multi-step numerical difference methods is higher than that of the forward Euler method, this paper proposes a stacking scheme based on the linear multi-step method. This scheme enhances the performance of ResNet without increasing the model size and compares it with the Runge-Kutta scheme. The experimental results show that the performance of the stacking scheme proposed in this paper is superior to existing stacking schemes (ResNet and HO-ResNet), and it has the capability to be extended to other types of neural networks.
Theoretical Analysis of Meta Reinforcement Learning: Generalization Bounds and Convergence Guarantees
May 22, 2024


This research delves deeply into Meta Reinforcement Learning (Meta RL) through a exploration focusing on defining generalization limits and ensuring convergence. By employing a approach this article introduces an innovative theoretical framework to meticulously assess the effectiveness and performance of Meta RL algorithms. We present an explanation of generalization limits measuring how well these algorithms can adapt to learning tasks while maintaining consistent results. Our analysis delves into the factors that impact the adaptability of Meta RL revealing the relationship, between algorithm design and task complexity. Additionally we establish convergence assurances by proving conditions under which Meta RL strategies are guaranteed to converge towards solutions. We examine the convergence behaviors of Meta RL algorithms across scenarios providing a comprehensive understanding of the driving forces behind their long term performance. This exploration covers both convergence and real time efficiency offering a perspective, on the capabilities of these algorithms.