 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Meta Reinforcement Learning: Generalization Bounds and Convergence Guarantees
May 22, 2024


This research delves deeply into Meta Reinforcement Learning (Meta RL) through a exploration focusing on defining generalization limits and ensuring convergence. By employing a approach this article introduces an innovative theoretical framework to meticulously assess the effectiveness and performance of Meta RL algorithms. We present an explanation of generalization limits measuring how well these algorithms can adapt to learning tasks while maintaining consistent results. Our analysis delves into the factors that impact the adaptability of Meta RL revealing the relationship, between algorithm design and task complexity. Additionally we establish convergence assurances by proving conditions under which Meta RL strategies are guaranteed to converge towards solutions. We examine the convergence behaviors of Meta RL algorithms across scenarios providing a comprehensive understanding of the driving forces behind their long term performance. This exploration covers both convergence and real time efficiency offering a perspective, on the capabilities of these algorithms.
Adapting LLMs for Efficient Context Processing through Soft Prompt Compression
Apr 07, 2024



The rapid advancement of Large Language Models (LLMs) has inaugurated a transformative epoch in natural language processing, fostering unprecedented proficiency in text generation, comprehension, and contextual scrutiny. Nevertheless, effectively handling extensive contexts, crucial for myriad applications, poses a formidable obstacle owing to the intrinsic constraints of the models' context window sizes and the computational burdens entailed by their operations. This investigation presents an innovative framework that strategically tailors LLMs for streamlined context processing by harnessing the synergies among natural language summarization, soft prompt compression, and augmented utility preservation mechanisms. Our methodology, dubbed SoftPromptComp, amalgamates natural language prompts extracted from summarization methodologies with dynamically generated soft prompts to forge a concise yet semantically robust depiction of protracted contexts. This depiction undergoes further refinement via a weighting mechanism optimizing information retention and utility for subsequent tasks. We substantiate that our framework markedly diminishes computational overhead and enhances LLMs' efficacy across various benchmarks, while upholding or even augmenting the caliber of the produced content. By amalgamating soft prompt compression with sophisticated summarization, SoftPromptComp confronts the dual challenges of managing lengthy contexts and ensuring model scalability. Our findings point towards a propitious trajectory for augmenting LLMs' applicability and efficiency, rendering them more versatile and pragmatic for real-world applications. This research enriches the ongoing discourse on optimizing language models, providing insights into the potency of soft prompts and summarization techniques as pivotal instruments for the forthcoming generation of NLP solutions.
Enhancing Multi-Hop Knowledge Graph Reasoning through Reward Shaping Techniques
Mar 09, 2024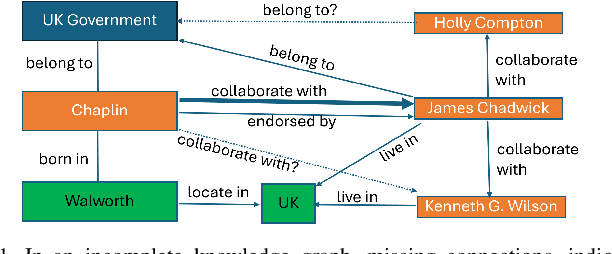
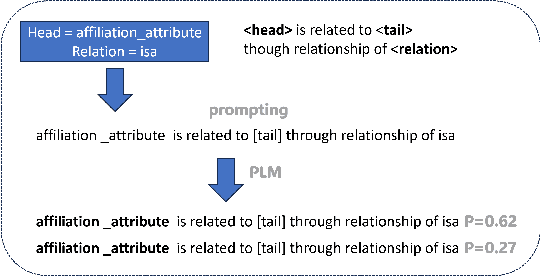


In the realm of computational knowledge representation, Knowledge Graph Reasoning (KG-R) stands at the forefront of facilitating sophisticated inferential capabilities across multifarious domains. The quintessence of this research elucidates the employment of reinforcement learning (RL) strategies, notably the REINFORCE algorithm, to navigate the intricacies inherent in multi-hop KG-R. This investigation critically addresses the prevalent challenges introduced by the inherent incompleteness of Knowledge Graphs (KGs), which frequently results in erroneous inferential outcomes, manifesting as both false negatives and misleading positives. By partitioning the Unified Medical Language System (UMLS) benchmark dataset into rich and sparse subsets, we investigate the efficacy of pre-trained BERT embeddings and Prompt Learning methodologies to refine the reward shaping process. This approach not only enhances the precision of multi-hop KG-R but also sets a new precedent for future research in the field, aiming to improve the robustness and accuracy of knowledge inference within complex KG frameworks. Our work contributes a novel perspective to the discourse on KG reasoning, offering a methodological advancement that aligns with the academic rigor and scholarly aspirations of the Natural journal, promising to invigorate further advancements in the realm of computational knowledge representation.
Intelligent Agricultural Greenhouse Control System Based on Internet of Things and Machine Learning
Feb 14, 2024



This study endeavors to conceptualize and execute a sophisticated agricultural greenhouse control system grounded in the amalgamation of the Internet of Things (IoT) and machine learning. Through meticulous monitoring of intrinsic environmental parameters within the greenhouse and the integration of machine learning algorithms, the conditions within the greenhouse are aptly modulated. The envisaged outcome is an enhancement in crop growth efficiency and yield, accompanied by a reduction in resource wastage. In the backdrop of escalating global population figures and the escalating exigencies of climate change, agriculture confronts unprecedented challenges. Conventional agricultural paradigms have proven inadequate in addressing the imperatives of food safety and production efficiency. Against this backdrop, greenhouse agriculture emerges as a viable solution, proffering a controlled milieu for crop cultivation to augment yields, refine quality, and diminish reliance on natural resources [b1]. Nevertheless, greenhouse agriculture contends with a gamut of challenges. Traditional greenhouse management strategies, often grounded in experiential knowledge and predefined rules, lack targeted personalized regulation, thereby resulting in resource inefficiencies. The exigencies of real-time monitoring and precise control of the greenhouse's internal environment gain paramount importance with the burgeoning scale of agriculture. To redress this challenge, the study introduces IoT technology and machine learning algorithms into greenhouse agriculture, aspiring to institute an intelligent agricultural greenhouse control system conducive to augmenting the efficiency and sustainability of agricultural production.