 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Overload-Aware Graph-Based Index Construction for 10-Billion-Scale Vector Similarity Search
Feb 28, 2025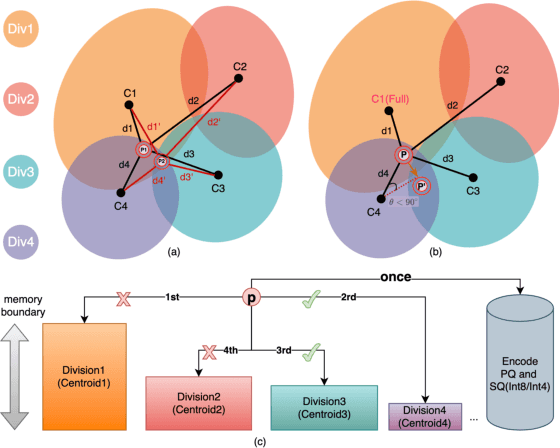
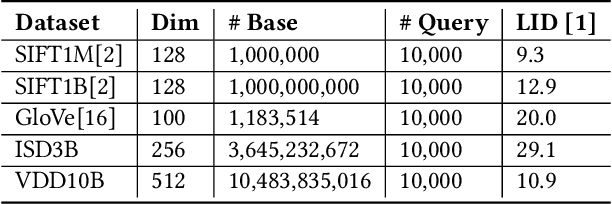
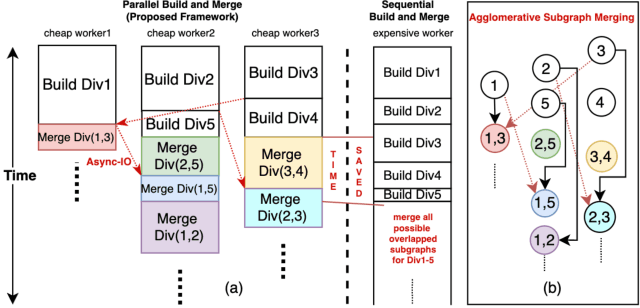
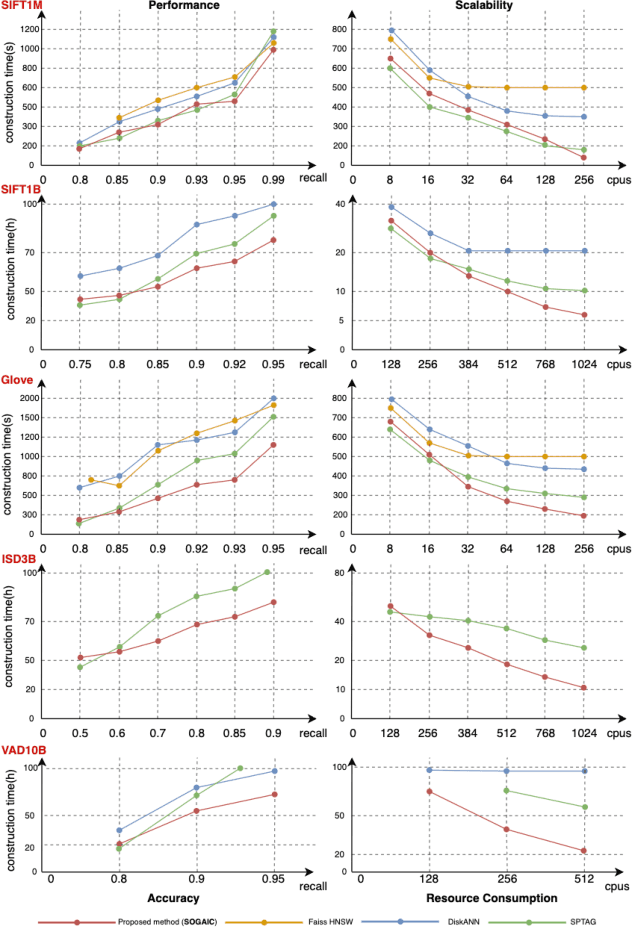
Approximate Nearest Neighbor Search (ANNS) is essential for modern data-driven applications that require efficient retrieval of top-k results from massive vector databases. Although existing graph-based ANNS algorithms achieve a high recall rate on billion-scale datasets, their slow construction speed and limited scalability hinder their applicability to large-scale industrial scenarios. In this paper, we introduce SOGAIC, the first Scalable Overload-Aware Graph-Based ANNS Index Construction system tailored for ultra-large-scale vector databases: 1) We propose a dynamic data partitioning algorithm with overload constraints that adaptively introduces overlaps among subsets; 2) To enable efficient distributed subgraph construction, we employ a load-balancing task scheduling framework combined with an agglomerative merging strategy; 3) Extensive experiments on various datasets demonstrate a reduction of 47.3% in average construction time compared to existing methods. The proposed method has also been successfully deployed in a real-world industrial search engine, managing over 10 billion daily updated vectors and serving hundreds of millions of users.
A Real-Time Adaptive Multi-Stream GPU System for Online Approximate Nearest Neighborhood Search
Aug 06, 2024In recent years, Approximate Nearest Neighbor Search (ANNS) has played a pivotal role in modern search and recommendation systems, especially in emerging LLM applications like Retrieval-Augmented Generation. There is a growing exploration into harnessing the parallel computing capabilities of GPUs to meet the substantial demands of ANNS. However, existing systems primarily focus on offline scenarios, overlooking the distinct requirements of online applications that necessitate real-time insertion of new vectors. This limitation renders such systems inefficient for real-world scenarios. Moreover, previous architectures struggled to effectively support real-time insertion due to their reliance on serial execution streams. In this paper, we introduce a novel Real-Time Adaptive Multi-Stream GPU ANNS System (RTAMS-GANNS). Our architecture achieves its objectives through three key advancements: 1) We initially examined the real-time insertion mechanisms in existing GPU ANNS systems and discovered their reliance on repetitive copying and memory allocation, which significantly hinders real-time effectiveness on GPUs. As a solution, we introduce a dynamic vector insertion algorithm based on memory blocks, which includes in-place rearrangement. 2) To enable real-time vector insertion in parallel, we introduce a multi-stream parallel execution mode, which differs from existing systems that operate serially within a single stream. Our system utilizes a dynamic resource pool, allowing multiple streams to execute concurrently without additional execution blocking. 3) Through extensive experiments and comparisons, our approach effectively handles varying QPS levels across different datasets, reducing latency by up to 40%-80%. The proposed system has also been deployed in real-world industrial search and recommendation systems, serving hundreds of millions of users daily, and has achieved good results.
A Global-Local Attention Mechanism for Relation Classification
Jul 01, 2024Relation classification, a crucial component of relation extraction, involves identifying connections between two entities. Previous studies have predominantly focused on integrating the attention mechanism into relation classification at a global scale, overlooking the importance of the local context. To address this gap, this paper introduces a novel global-local attention mechanism for relation classification, which enhances global attention with a localized focus. Additionally, we propose innovative hard and soft localization mechanisms to identify potential keywords for local attention. By incorporating both hard and soft localization strategies, our approach offers a more nuanced and comprehensive understanding of the contextual cues that contribute to effective relation classification. Our experimental results on the SemEval-2010 Task 8 dataset highlight the superior performance of our method compared to previous attention-based approaches in relation classification.
TransTARec: Time-Adaptive Translating Embedding Model for Next POI Recommendation
Apr 10, 2024



The rapid growth of location acquisition technologies makes Point-of-Interest(POI) recommendation possible due to redundant user check-in records. In this paper, we focus on next POI recommendation in which next POI is based on previous POI. We observe that time plays an important role in next POI recommendation but is neglected in the recent proposed translating embedding methods. To tackle this shortage, we propose a time-adaptive translating embedding model (TransTARec) for next POI recommendation that naturally incorporates temporal influence, sequential dynamics, and user preference within a single component. Methodologically, we treat a (previous timestamp, user, next timestamp) triplet as a union translation vector and develop a neural-based fusion operation to fuse user preference and temporal influence. The superiority of TransTARec, which is confirmed by extensive experiments on real-world datasets, comes from not only the introduction of temporal influence but also the direct unification with user preference and sequential dynamics.
Enhancing Multi-Hop Knowledge Graph Reasoning through Reward Shaping Techniques
Mar 09, 2024


In the realm of computational knowledge representation, Knowledge Graph Reasoning (KG-R) stands at the forefront of facilitating sophisticated inferential capabilities across multifarious domains. The quintessence of this research elucidates the employment of reinforcement learning (RL) strategies, notably the REINFORCE algorithm, to navigate the intricacies inherent in multi-hop KG-R. This investigation critically addresses the prevalent challenges introduced by the inherent incompleteness of Knowledge Graphs (KGs), which frequently results in erroneous inferential outcomes, manifesting as both false negatives and misleading positives. By partitioning the Unified Medical Language System (UMLS) benchmark dataset into rich and sparse subsets, we investigate the efficacy of pre-trained BERT embeddings and Prompt Learning methodologies to refine the reward shaping process. This approach not only enhances the precision of multi-hop KG-R but also sets a new precedent for future research in the field, aiming to improve the robustness and accuracy of knowledge inference within complex KG frameworks. Our work contributes a novel perspective to the discourse on KG reasoning, offering a methodological advancement that aligns with the academic rigor and scholarly aspirations of the Natural journal, promising to invigorate further advancements in the realm of computational knowledge representation.
Interpretable Crowd Flow Prediction with Spatial-Temporal Self-Attention
Feb 22, 2020
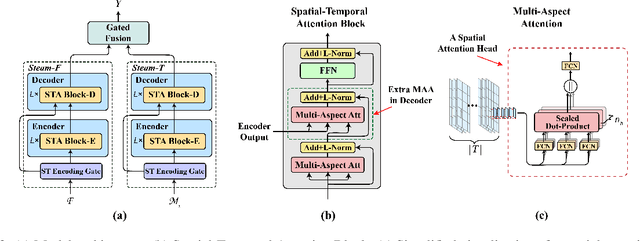
Crowd flow prediction has been increasingly investigated in intelligent urban computing field as a fundamental component of urban management system. The most challenging part of predicting crowd flow is to measure the complicated spatial-temporal dependencies. A prevalent solution employed in current methods is to divide and conquer the spatial and temporal information by various architectures (e.g., CNN/GCN, LSTM). However, this strategy has two disadvantages: (1) the sophisticated dependencies are also divided and therefore partially isolated; (2) the spatial-temporal features are transformed into latent representations when passing through different architectures, making it hard to interpret the predicted crowd flow. To address these issues, we propose a Spatial-Temporal Self-Attention Network (STSAN) with an ST encoding gate that calculates the entire spatial-temporal representation with positional and time encodings and therefore avoids dividing the dependencies. Furthermore, we develop a Multi-aspect attention mechanism that applies scaled dot-product attention over spatial-temporal information and measures the attention weights that explicitly indicate the dependencies. Experimental results on traffic and mobile data demonstrate that the proposed method reduces inflow and outflow RMSE by 16% and 8% on the Taxi-NYC dataset compared to the SOTA baselines.
Spatial-Temporal Self-Attention Network for Flow Prediction
Dec 23, 2019
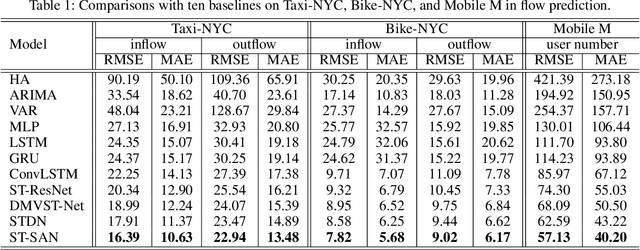
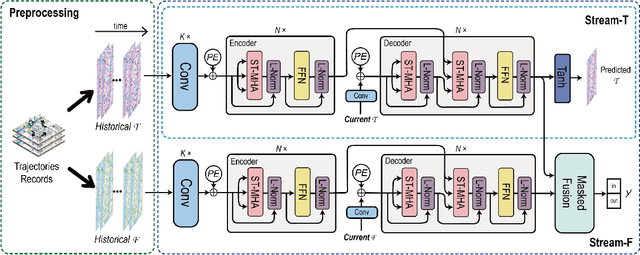
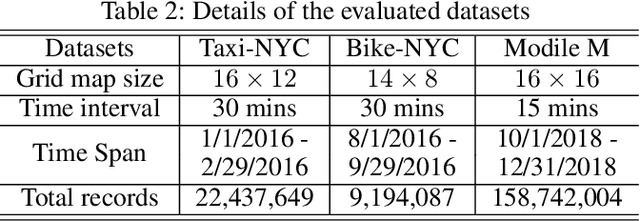
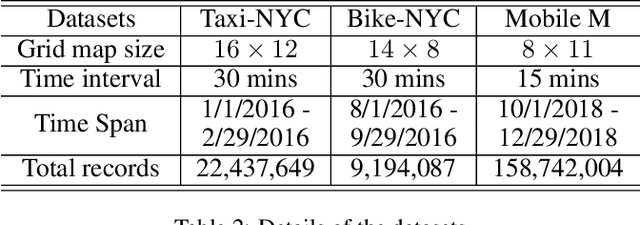
Flow prediction (e.g., crowd flow, traffic flow) with features of spatial-temporal is increasingly investigated in AI research field. It is very challenging due to the complicated spatial dependencies between different locations and dynamic temporal dependencies among different time intervals. Although measurements of both dependencies are employed, existing methods suffer from the following two problems. First, the temporal dependencies are measured either uniformly or bias against long-term dependencies, which overlooks the distinctive impacts of short-term and long-term temporal dependencies. Second, the existing methods capture spatial and temporal dependencies independently, which wrongly assumes that the correlations between these dependencies are weak and ignores the complicated mutual influences between them. To address these issues, we propose a Spatial-Temporal Self-Attention Network (ST-SAN). As the path-length of attending long-term dependency is shorter in the self-attention mechanism, the vanishing of long-term temporal dependencies is prevented. In addition, since our model relies solely on attention mechanisms, the spatial and temporal dependencies can be simultaneously measured. Experimental results on real-world data demonstrate that, in comparison with state-of-the-art methods, our model reduces the root mean square errors by 9% in inflow prediction and 4% in outflow prediction on Taxi-NYC data, which is very significant compared to the previous improvement.