 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Roads Lead to Rome: Incentivizing Divergent Thinking in Vision-Language Models
Apr 01, 2026Recent studies have demonstrated that Reinforcement Learning (RL), notably Group Relative Policy Optimization (GRPO), can intrinsically elicit and enhance the reasoning capabilities of Vision-Language Models (VLMs). However, despite the promise, the underlying mechanisms that drive the effectiveness of RL models as well as their limitations remain underexplored. In this paper, we highlight a fundamental behavioral distinction between RL and base models, where the former engages in deeper yet narrow reasoning, while base models, despite less refined along individual path, exhibit broader and more diverse thinking patterns. Through further analysis of training dynamics, we show that GRPO is prone to diversity collapse, causing models to prematurely converge to a limited subset of reasoning strategies while discarding the majority of potential alternatives, leading to local optima and poor scalability. To address this, we propose Multi-Group Policy Optimization (MUPO), a simple yet effective approach designed to incentivize divergent thinking across multiple solutions, and demonstrate its effectiveness on established benchmarks. Project page: https://xytian1008.github.io/MUPO/
Generative Score Inference for Multimodal Data
Mar 27, 2026Accurate uncertainty quantification is crucial for making reliable decisions in various supervised learning scenarios, particularly when dealing with complex, multimodal data such as images and text. Current approaches often face notable limitations, including rigid assumptions and limited generalizability, constraining their effectiveness across diverse supervised learning tasks. To overcome these limitations, we introduce Generative Score Inference (GSI), a flexible inference framework capable of constructing statistically valid and informative prediction and confidence sets across a wide range of multimodal learning problems. GSI utilizes synthetic samples generated by deep generative models to approximate conditional score distributions, facilitating precise uncertainty quantification without imposing restrictive assumptions about the data or tasks. We empirically validate GSI's capabilities through two representative scenarios: hallucination detection in large language models and uncertainty estimation in image captioning. Our method achieves state-of-the-art performance in hallucination detection and robust predictive uncertainty in image captioning, and its performance is positively influenced by the quality of the underlying generative model. These findings underscore the potential of GSI as a versatile inference framework, significantly enhancing uncertainty quantification and trustworthiness in multimodal learning.
Manifold-Aligned Generative Transport
Feb 23, 2026High-dimensional generative modeling is fundamentally a manifold-learning problem: real data concentrate near a low-dimensional structure embedded in the ambient space. Effective generators must therefore balance support fidelity -- placing probability mass near the data manifold -- with sampling efficiency. Diffusion models often capture near-manifold structure but require many iterative denoising steps and can leak off-support; normalizing flows sample in one pass but are limited by invertibility and dimension preservation. We propose MAGT (Manifold-Aligned Generative Transport), a flow-like generator that learns a one-shot, manifold-aligned transport from a low-dimensional base distribution to the data space. Training is performed at a fixed Gaussian smoothing level, where the score is well-defined and numerically stable. We approximate this fixed-level score using a finite set of latent anchor points with self-normalized importance sampling, yielding a tractable objective. MAGT samples in a single forward pass, concentrates probability near the learned support, and induces an intrinsic density with respect to the manifold volume measure, enabling principled likelihood evaluation for generated samples. We establish finite-sample Wasserstein bounds linking smoothing level and score-approximation accuracy to generative fidelity, and empirically improve fidelity and manifold concentration across synthetic and benchmark datasets while sampling substantially faster than diffusion models.
Few Tokens Matter: Entropy Guided Attacks on Vision-Language Models
Dec 26, 2025Vision-language models (VLMs) achieve remarkable performance but remain vulnerable to adversarial attacks. Entropy, a measure of model uncertainty, is strongly correlated with the reliability of VLM. Prior entropy-based attacks maximize uncertainty at all decoding steps, implicitly assuming that every token contributes equally to generation instability. We show instead that a small fraction (about 20%) of high-entropy tokens, i.e., critical decision points in autoregressive generation, disproportionately governs output trajectories. By concentrating adversarial perturbations on these positions, we achieve semantic degradation comparable to global methods while using substantially smaller budgets. More importantly, across multiple representative VLMs, such selective attacks convert 35-49% of benign outputs into harmful ones, exposing a more critical safety risk. Remarkably, these vulnerable high-entropy forks recur across architecturally diverse VLMs, enabling feasible transferability (17-26% harmful rates on unseen targets). Motivated by these findings, we propose Entropy-bank Guided Adversarial attacks (EGA), which achieves competitive attack success rates (93-95%) alongside high harmful conversion, thereby revealing new weaknesses in current VLM safety mechanisms.
Unlocking Vision-Language Models for Video Anomaly Detection via Fine-Grained Prompting
Oct 02, 2025
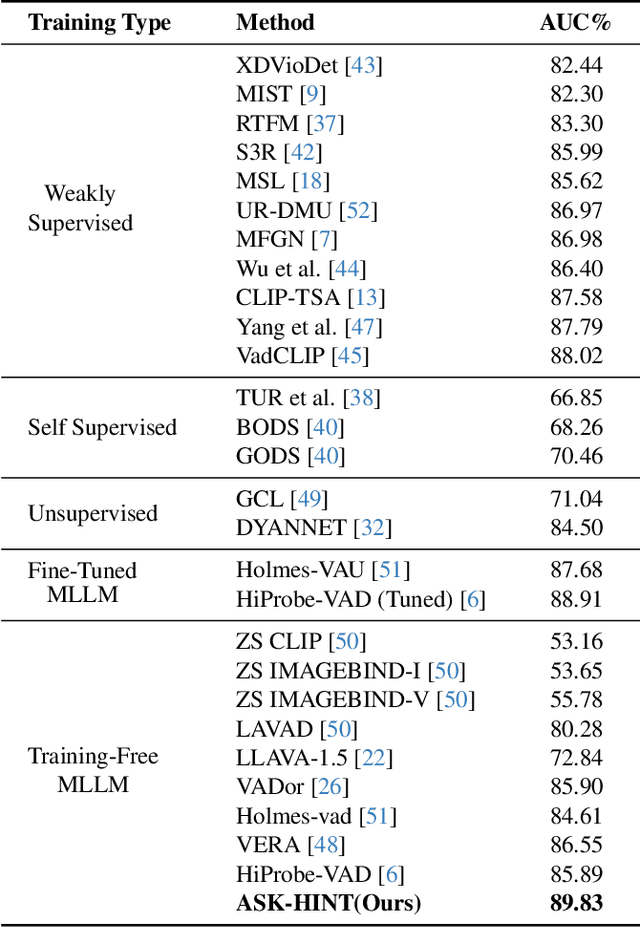
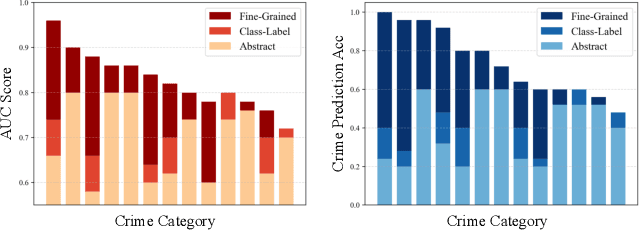
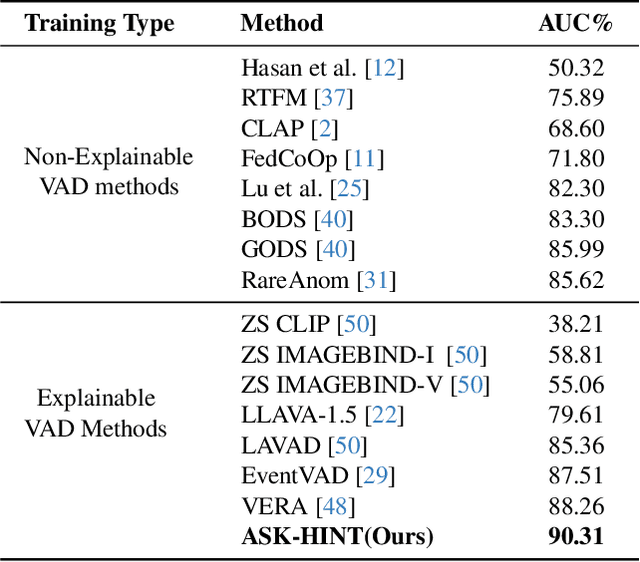
Prompting has emerged as a practical way to adapt frozen vision-language models (VLMs) for video anomaly detection (VAD). Yet, existing prompts are often overly abstract, overlooking the fine-grained human-object interactions or action semantics that define complex anomalies in surveillance videos. We propose ASK-Hint, a structured prompting framework that leverages action-centric knowledge to elicit more accurate and interpretable reasoning from frozen VLMs. Our approach organizes prompts into semantically coherent groups (e.g. violence, property crimes, public safety) and formulates fine-grained guiding questions that align model predictions with discriminative visual cues. Extensive experiments on UCF-Crime and XD-Violence show that ASK-Hint consistently improves AUC over prior baselines, achieving state-of-the-art performance compared to both fine-tuned and training-free methods. Beyond accuracy, our framework provides interpretable reasoning traces towards anomaly and demonstrates strong generalization across datasets and VLM backbones. These results highlight the critical role of prompt granularity and establish ASK-Hint as a new training-free and generalizable solution for explainable video anomaly detection.
Simple Radiology VLLM Test-time Scaling with Thought Graph Traversal
Jun 13, 2025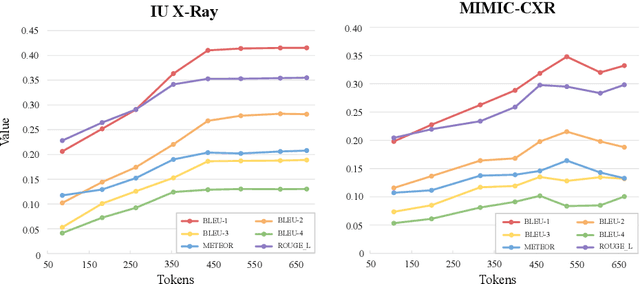
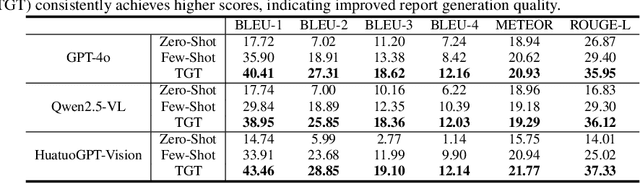
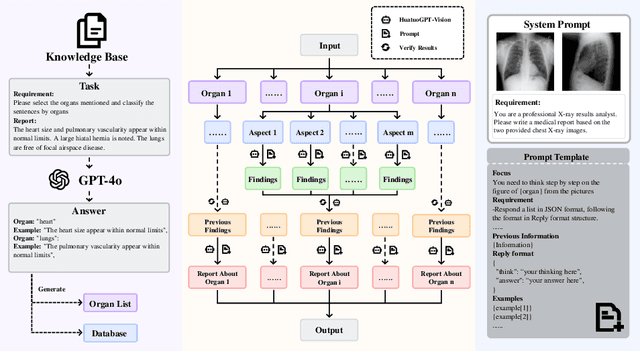
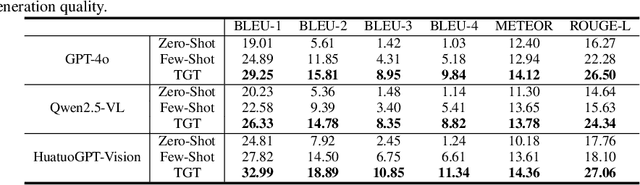
Test-time scaling offers a promising way to improve the reasoning performance of vision-language large models (VLLMs) without additional training. In this paper, we explore a simple but effective approach for applying test-time scaling to radiology report generation. Specifically, we introduce a lightweight Thought Graph Traversal (TGT) framework that guides the model to reason through organ-specific findings in a medically coherent order. This framework integrates structured medical priors into the prompt, enabling deeper and more logical analysis with no changes to the underlying model. To further enhance reasoning depth, we apply a reasoning budget forcing strategy that adjusts the model's inference depth at test time by dynamically extending its generation process. This simple yet powerful combination allows a frozen radiology VLLM to self-correct and generate more accurate, consistent chest X-ray reports. Our method outperforms baseline prompting approaches on standard benchmarks, and also reveals dataset biases through traceable reasoning paths. Code and prompts are open-sourced for reproducibility at https://github.com/glerium/Thought-Graph-Traversal.
Conditional Data Synthesis Augmentation
Apr 10, 2025Reliable machine learning and statistical analysis rely on diverse, well-distributed training data. However, real-world datasets are often limited in size and exhibit underrepresentation across key subpopulations, leading to biased predictions and reduced performance, particularly in supervised tasks such as classification. To address these challenges, we propose Conditional Data Synthesis Augmentation (CoDSA), a novel framework that leverages generative models, such as diffusion models, to synthesize high-fidelity data for improving model performance across multimodal domains including tabular, textual, and image data. CoDSA generates synthetic samples that faithfully capture the conditional distributions of the original data, with a focus on under-sampled or high-interest regions. Through transfer learning, CoDSA fine-tunes pre-trained generative models to enhance the realism of synthetic data and increase sample density in sparse areas. This process preserves inter-modal relationships, mitigates data imbalance, improves domain adaptation, and boosts generalization. We also introduce a theoretical framework that quantifies the statistical accuracy improvements enabled by CoDSA as a function of synthetic sample volume and targeted region allocation, providing formal guarantees of its effectiveness. Extensive experiments demonstrate that CoDSA consistently outperforms non-adaptive augmentation strategies and state-of-the-art baselines in both supervised and unsupervised settings.
Identifying and Mitigating Position Bias of Multi-image Vision-Language Models
Mar 18, 2025



The evolution of Large Vision-Language Models (LVLMs) has progressed from single to multi-image reasoning. Despite this advancement, our findings indicate that LVLMs struggle to robustly utilize information across multiple images, with predictions significantly affected by the alteration of image positions. To further explore this issue, we introduce Position-wise Question Answering (PQA), a meticulously designed task to quantify reasoning capabilities at each position. Our analysis reveals a pronounced position bias in LVLMs: open-source models excel in reasoning with images positioned later but underperform with those in the middle or at the beginning, while proprietary models show improved comprehension for images at the beginning and end but struggle with those in the middle. Motivated by this, we propose SoFt Attention (SoFA), a simple, training-free approach that mitigates this bias by employing linear interpolation between inter-image causal attention and bidirectional counterparts. Experimental results demonstrate that SoFA reduces position bias and enhances the reasoning performance of existing LVLMs.
Black Sheep in the Herd: Playing with Spuriously Correlated Attributes for Vision-Language Recognition
Feb 19, 2025



Few-shot adaptation for Vision-Language Models (VLMs) presents a dilemma: balancing in-distribution accuracy with out-of-distribution generalization. Recent research has utilized low-level concepts such as visual attributes to enhance generalization. However, this study reveals that VLMs overly rely on a small subset of attributes on decision-making, which co-occur with the category but are not inherently part of it, termed spuriously correlated attributes. This biased nature of VLMs results in poor generalization. To address this, 1) we first propose Spurious Attribute Probing (SAP), identifying and filtering out these problematic attributes to significantly enhance the generalization of existing attribute-based methods; 2) We introduce Spurious Attribute Shielding (SAS), a plug-and-play module that mitigates the influence of these attributes on prediction, seamlessly integrating into various Parameter-Efficient Fine-Tuning (PEFT) methods. In experiments, SAP and SAS significantly enhance accuracy on distribution shifts across 11 datasets and 3 generalization tasks without compromising downstream performance, establishing a new state-of-the-art benchmark.
Generative Distribution Prediction: A Unified Approach to Multimodal Learning
Feb 10, 2025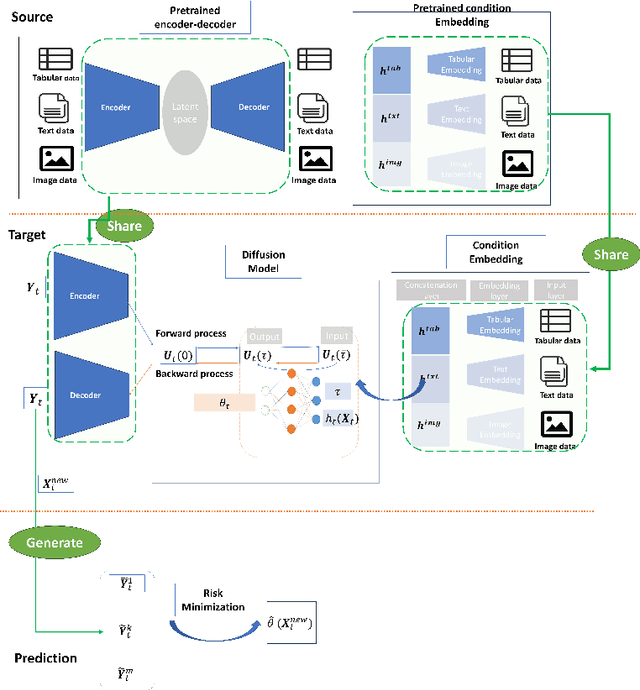
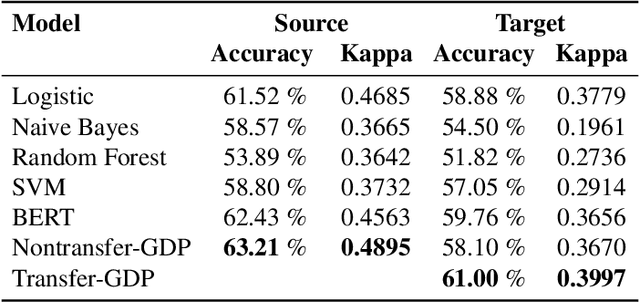
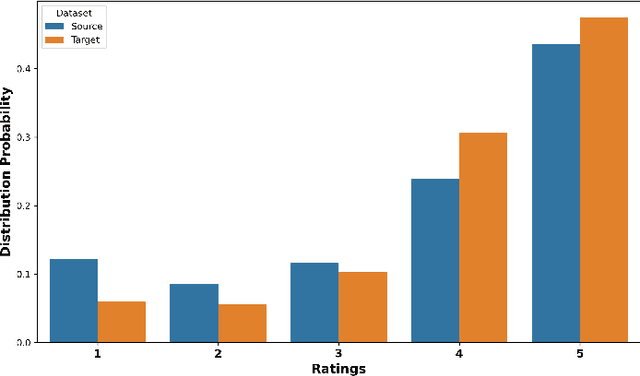
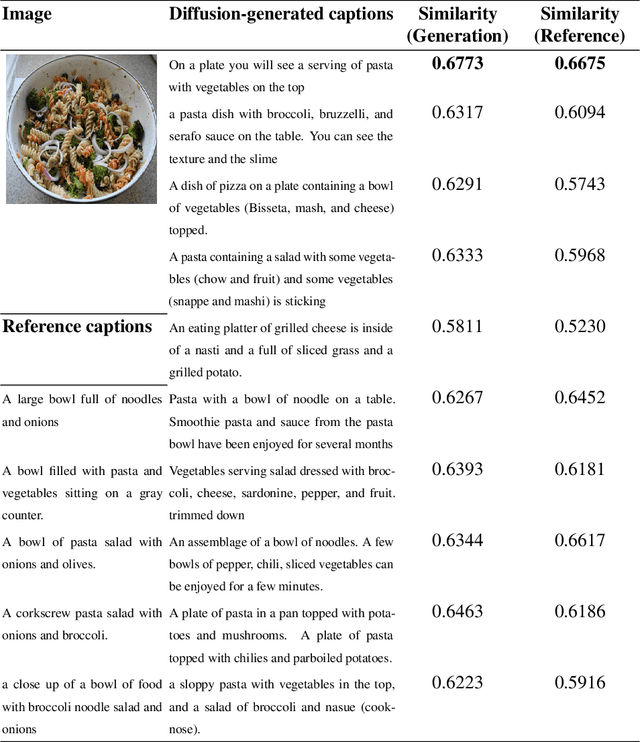
Accurate prediction with multimodal data-encompassing tabular, textual, and visual inputs or outputs-is fundamental to advancing analytics in diverse application domains. Traditional approaches often struggle to integrate heterogeneous data types while maintaining high predictive accuracy. We introduce Generative Distribution Prediction (GDP), a novel framework that leverages multimodal synthetic data generation-such as conditional diffusion models-to enhance predictive performance across structured and unstructured modalities. GDP is model-agnostic, compatible with any high-fidelity generative model, and supports transfer learning for domain adaptation. We establish a rigorous theoretical foundation for GDP, providing statistical guarantees on its predictive accuracy when using diffusion models as the generative backbone. By estimating the data-generating distribution and adapting to various loss functions for risk minimization, GDP enables accurate point predictions across multimodal settings. We empirically validate GDP on four supervised learning tasks-tabular data prediction, question answering, image captioning, and adaptive quantile regression-demonstrating its versatility and effectiveness across diverse domains.