 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMCP-Bench: Benchmarking LLM Agents for Real-World Financial Tool Use under the Model Context Protocol
Mar 26, 2026This paper introduces \textbf{FinMCP-Bench}, a novel benchmark for evaluating large language models (LLMs) in solving real-world financial problems through tool invocation of financial model context protocols. FinMCP-Bench contains 613 samples spanning 10 main scenarios and 33 sub-scenarios, featuring both real and synthetic user queries to ensure diversity and authenticity. It incorporates 65 real financial MCPs and three types of samples, single tool, multi-tool, and multi-turn, allowing evaluation of models across different levels of task complexity. Using this benchmark, we systematically assess a range of mainstream LLMs and propose metrics that explicitly measure tool invocation accuracy and reasoning capabilities. FinMCP-Bench provides a standardized, practical, and challenging testbed for advancing research on financial LLM agents.
Fin-PRM: A Domain-Specialized Process Reward Model for Financial Reasoning in Large Language Models
Aug 21, 2025Process Reward Models (PRMs) have emerged as a promising framework for supervising intermediate reasoning in large language models (LLMs), yet existing PRMs are primarily trained on general or Science, Technology, Engineering, and Mathematics (STEM) domains and fall short in domain-specific contexts such as finance, where reasoning is more structured, symbolic, and sensitive to factual and regulatory correctness. We introduce \textbf{Fin-PRM}, a domain-specialized, trajectory-aware PRM tailored to evaluate intermediate reasoning steps in financial tasks. Fin-PRM integrates step-level and trajectory-level reward supervision, enabling fine-grained evaluation of reasoning traces aligned with financial logic. We apply Fin-PRM in both offline and online reward learning settings, supporting three key applications: (i) selecting high-quality reasoning trajectories for distillation-based supervised fine-tuning, (ii) providing dense process-level rewards for reinforcement learning, and (iii) guiding reward-informed Best-of-N inference at test time. Experimental results on financial reasoning benchmarks, including CFLUE and FinQA, demonstrate that Fin-PRM consistently outperforms general-purpose PRMs and strong domain baselines in trajectory selection quality. Downstream models trained with Fin-PRM yield substantial improvements with baselines, with gains of 12.9\% in supervised learning, 5.2\% in reinforcement learning, and 5.1\% in test-time performance. These findings highlight the value of domain-specialized reward modeling for aligning LLMs with expert-level financial reasoning. Our project resources will be available at https://github.com/aliyun/qwen-dianjin.
DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
Apr 22, 2025

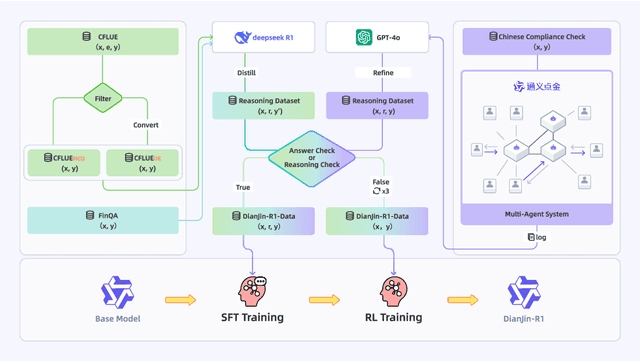

Effective reasoning remains a core challenge for large language models (LLMs) in the financial domain, where tasks often require domain-specific knowledge, precise numerical calculations, and strict adherence to compliance rules. We propose DianJin-R1, a reasoning-enhanced framework designed to address these challenges through reasoning-augmented supervision and reinforcement learning. Central to our approach is DianJin-R1-Data, a high-quality dataset constructed from CFLUE, FinQA, and a proprietary compliance corpus (Chinese Compliance Check, CCC), combining diverse financial reasoning scenarios with verified annotations. Our models, DianJin-R1-7B and DianJin-R1-32B, are fine-tuned from Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct using a structured format that generates both reasoning steps and final answers. To further refine reasoning quality, we apply Group Relative Policy Optimization (GRPO), a reinforcement learning method that incorporates dual reward signals: one encouraging structured outputs and another rewarding answer correctness. We evaluate our models on five benchmarks: three financial datasets (CFLUE, FinQA, and CCC) and two general reasoning benchmarks (MATH-500 and GPQA-Diamond). Experimental results show that DianJin-R1 models consistently outperform their non-reasoning counterparts, especially on complex financial tasks. Moreover, on the real-world CCC dataset, our single-call reasoning models match or even surpass the performance of multi-agent systems that require significantly more computational cost. These findings demonstrate the effectiveness of DianJin-R1 in enhancing financial reasoning through structured supervision and reward-aligned learning, offering a scalable and practical solution for real-world applications.
Speech Translation Refinement using Large Language Models
Jan 25, 2025



Recent advancements in large language models (LLMs) have demonstrated their remarkable capabilities across various language tasks. Inspired by the success of text-to-text translation refinement, this paper investigates how LLMs can improve the performance of speech translation by introducing a joint refinement process. Through the joint refinement of speech translation (ST) and automatic speech recognition (ASR) transcription via LLMs, the performance of the ST model is significantly improved in both training-free in-context learning and parameter-efficient fine-tuning scenarios. Additionally, we explore the effect of document-level context on refinement under the context-aware fine-tuning scenario. Experimental results on the MuST-C and CoVoST 2 datasets, which include seven translation tasks, demonstrate the effectiveness of the proposed approach using several popular LLMs including GPT-3.5-turbo, LLaMA3-8B, and Mistral-12B. Further analysis further suggests that jointly refining both transcription and translation yields better performance compared to refining translation alone. Meanwhile, incorporating document-level context significantly enhances refinement performance. We release our code and datasets on GitHub.
Benchmarking Large Language Models on CFLUE -- A Chinese Financial Language Understanding Evaluation Dataset
May 17, 2024In light of recent breakthroughs in large language models (LLMs) that have revolutionized natural language processing (NLP), there is an urgent need for new benchmarks to keep pace with the fast development of LLMs. In this paper, we propose CFLUE, the Chinese Financial Language Understanding Evaluation benchmark, designed to assess the capability of LLMs across various dimensions. Specifically, CFLUE provides datasets tailored for both knowledge assessment and application assessment. In knowledge assessment, it consists of 38K+ multiple-choice questions with associated solution explanations. These questions serve dual purposes: answer prediction and question reasoning. In application assessment, CFLUE features 16K+ test instances across distinct groups of NLP tasks such as text classification, machine translation, relation extraction, reading comprehension, and text generation. Upon CFLUE, we conduct a thorough evaluation of representative LLMs. The results reveal that only GPT-4 and GPT-4-turbo achieve an accuracy exceeding 60\% in answer prediction for knowledge assessment, suggesting that there is still substantial room for improvement in current LLMs. In application assessment, although GPT-4 and GPT-4-turbo are the top two performers, their considerable advantage over lightweight LLMs is noticeably diminished. The datasets and scripts associated with CFLUE are openly accessible at https://github.com/aliyun/cflue.
* Accepted by ACL 2024