 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIESR:Efficient MCTS-Based Modular Reasoning for Text-to-SQL with Large Language Models
Feb 05, 2026Text-to-SQL is a key natural language processing task that maps natural language questions to SQL queries, enabling intuitive interaction with web-based databases. Although current methods perform well on benchmarks like BIRD and Spider, they struggle with complex reasoning, domain knowledge, and hypothetical queries, and remain costly in enterprise deployment. To address these issues, we propose a framework named IESR(Information Enhanced Structured Reasoning) for lightweight large language models: (i) leverages LLMs for key information understanding and schema linking, and decoupling mathematical computation and SQL generation, (ii) integrates a multi-path reasoning mechanism based on Monte Carlo Tree Search (MCTS) with majority voting, and (iii) introduces a trajectory consistency verification module with a discriminator model to ensure accuracy and consistency. Experimental results demonstrate that IESR achieves state-of-the-art performance on the complex reasoning benchmark LogicCat (24.28 EX) and the Archer dataset (37.28 EX) using only compact lightweight models without fine-tuning. Furthermore, our analysis reveals that current coder models exhibit notable biases and deficiencies in physical knowledge, mathematical computation, and common-sense reasoning, highlighting important directions for future research. We released code at https://github.com/Ffunkytao/IESR-SLM.
Two Intermediate Translations Are Better Than One: Fine-tuning LLMs for Document-level Translation Refinement
Apr 08, 2025Recent research has shown that large language models (LLMs) can enhance translation quality through self-refinement. In this paper, we build on this idea by extending the refinement from sentence-level to document-level translation, specifically focusing on document-to-document (Doc2Doc) translation refinement. Since sentence-to-sentence (Sent2Sent) and Doc2Doc translation address different aspects of the translation process, we propose fine-tuning LLMs for translation refinement using two intermediate translations, combining the strengths of both Sent2Sent and Doc2Doc. Additionally, recognizing that the quality of intermediate translations varies, we introduce an enhanced fine-tuning method with quality awareness that assigns lower weights to easier translations and higher weights to more difficult ones, enabling the model to focus on challenging translation cases. Experimental results across ten translation tasks with LLaMA-3-8B-Instruct and Mistral-Nemo-Instruct demonstrate the effectiveness of our approach.
DoCIA: An Online Document-Level Context Incorporation Agent for Speech Translation
Apr 07, 2025Document-level context is crucial for handling discourse challenges in text-to-text document-level machine translation (MT). Despite the increased discourse challenges introduced by noise from automatic speech recognition (ASR), the integration of document-level context in speech translation (ST) remains insufficiently explored. In this paper, we develop DoCIA, an online framework that enhances ST performance by incorporating document-level context. DoCIA decomposes the ST pipeline into four stages. Document-level context is integrated into the ASR refinement, MT, and MT refinement stages through auxiliary LLM (large language model)-based modules. Furthermore, DoCIA leverages document-level information in a multi-level manner while minimizing computational overhead. Additionally, a simple yet effective determination mechanism is introduced to prevent hallucinations from excessive refinement, ensuring the reliability of the final results. Experimental results show that DoCIA significantly outperforms traditional ST baselines in both sentence and discourse metrics across four LLMs, demonstrating its effectiveness in improving ST performance.
Improving LLM-based Document-level Machine Translation with Multi-Knowledge Fusion
Mar 15, 2025
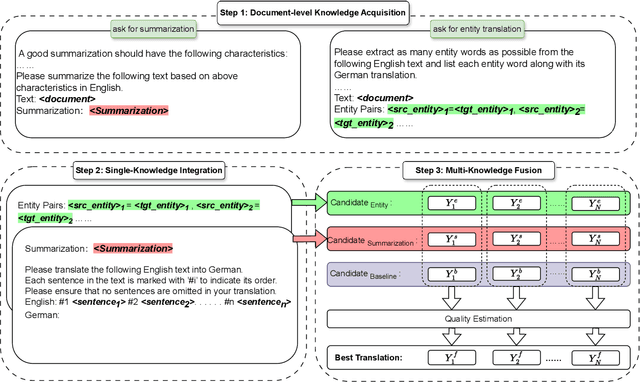
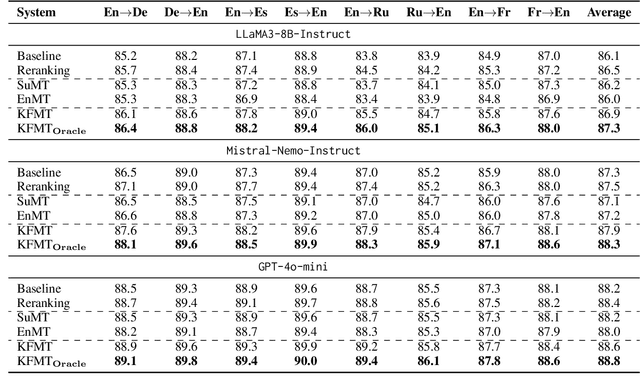
Recent studies in prompting large language model (LLM) for document-level machine translation (DMT) primarily focus on the inter-sentence context by flatting the source document into a long sequence. This approach relies solely on the sequence of sentences within the document. However, the complexity of document-level sequences is greater than that of shorter sentence-level sequences, which may limit LLM's ability in DMT when only this single-source knowledge is used. In this paper, we propose an enhanced approach by incorporating multiple sources of knowledge, including both the document summarization and entity translation, to enhance the performance of LLM-based DMT. Given a source document, we first obtain its summarization and translation of entities via LLM as the additional knowledge. We then utilize LLMs to generate two translations of the source document by fusing these two single knowledge sources, respectively. Finally, recognizing that different sources of knowledge may aid or hinder the translation of different sentences, we refine and rank the translations by leveraging a multi-knowledge fusion strategy to ensure the best results. Experimental results in eight document-level translation tasks show that our approach achieves an average improvement of 0.8, 0.6, and 0.4 COMET scores over the baseline without extra knowledge for LLaMA3-8B-Instruct, Mistral-Nemo-Instruct, and GPT-4o-mini, respectively.
Speech Translation Refinement using Large Language Models
Jan 25, 2025



Recent advancements in large language models (LLMs) have demonstrated their remarkable capabilities across various language tasks. Inspired by the success of text-to-text translation refinement, this paper investigates how LLMs can improve the performance of speech translation by introducing a joint refinement process. Through the joint refinement of speech translation (ST) and automatic speech recognition (ASR) transcription via LLMs, the performance of the ST model is significantly improved in both training-free in-context learning and parameter-efficient fine-tuning scenarios. Additionally, we explore the effect of document-level context on refinement under the context-aware fine-tuning scenario. Experimental results on the MuST-C and CoVoST 2 datasets, which include seven translation tasks, demonstrate the effectiveness of the proposed approach using several popular LLMs including GPT-3.5-turbo, LLaMA3-8B, and Mistral-12B. Further analysis further suggests that jointly refining both transcription and translation yields better performance compared to refining translation alone. Meanwhile, incorporating document-level context significantly enhances refinement performance. We release our code and datasets on GitHub.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
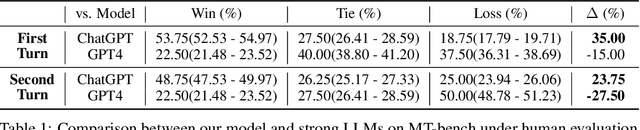


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.
DeMPT: Decoding-enhanced Multi-phase Prompt Tuning for Making LLMs Be Better Context-aware Translators
Feb 23, 2024

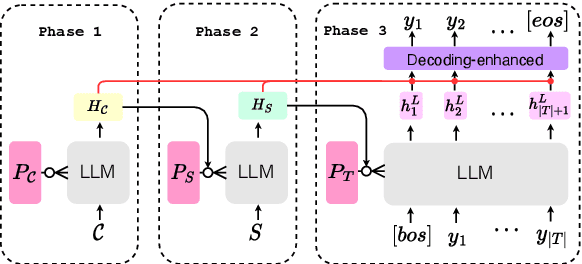

Generally, the decoder-only large language models (LLMs) are adapted to context-aware neural machine translation (NMT) in a concatenating way, where LLMs take the concatenation of the source sentence (i.e., intra-sentence context) and the inter-sentence context as the input, and then to generate the target tokens sequentially. This adaptation strategy, i.e., concatenation mode, considers intra-sentence and inter-sentence contexts with the same priority, despite an apparent difference between the two kinds of contexts. In this paper, we propose an alternative adaptation approach, named Decoding-enhanced Multi-phase Prompt Tuning (DeMPT), to make LLMs discriminately model and utilize the inter- and intra-sentence context and more effectively adapt LLMs to context-aware NMT. First, DeMPT divides the context-aware NMT process into three separate phases. During each phase, different continuous prompts are introduced to make LLMs discriminately model various information. Second, DeMPT employs a heuristic way to further discriminately enhance the utilization of the source-side inter- and intra-sentence information at the final decoding phase. Experiments show that our approach significantly outperforms the concatenation method, and further improves the performance of LLMs in discourse modeling.