 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRI: SVD-Partitioned Residual Initialization for Data-Constrained MoE Upcycling
Jun 15, 2026Mixture-of-Experts (MoE) models enable efficient scaling, but training them from scratch remains prohibitively expensive. MoE upcycling mitigates this cost by converting pretrained dense models into sparse MoE models. However, existing upcycling methods typically rely on large-scale continued training and often perform poorly under data-constrained supervised adaptation, due to either homogeneous experts or overly disruptive perturbations to pretrained parameters. In this setting, effective upcycling must leverage pretrained weight structure while introducing sufficient diversity among routed experts. To this end, we propose SVD-Partitioned Residual Initialization (SPRI), which distributes SVD-partitioned residuals derived from pretrained feed-forward network (FFN) weights across routed experts, introducing controlled expert diversity grounded in pretrained spectral structure. We further introduce a two-stage training strategy to improve adaptation stability. We evaluate SPRI on multilingual speech-to-text translation, where limited supervised data challenges MoE upcycling and multiple target languages provide natural routing heterogeneity. On CoVoST2 across 15 En-to-XX directions, SPRI improves average BLEU and COMET over fully fine-tuned dense models by 2.58 and 3.32 points, respectively, and outperforms the prior best MoE upcycling baseline by 3.39 BLEU and 4.34 COMET points.
AdapShot: Adaptive Many-Shot In-Context Learning with Semantic-Aware KV Cache Reuse
May 05, 2026Many-Shot In-Context Learning (ICL) has emerged as a promising paradigm, leveraging extensive examples to unlock the reasoning potential of Large Language Models (LLMs). However, existing methods typically rely on a predetermined, fixed number of shots. This static approach often fails to adapt to the varying difficulty of different queries, leading to either insufficient context or interference from noise. Furthermore, the prohibitive computational and memory costs of long contexts severely limit Many-Shot's feasibility. To address the above limitations, we propose AdapShot, which dynamically optimizes shot counts and leverages KV cache reuse for efficient inference. Specifically, we design a probe-based evaluation mechanism that utilizes output entropy to determine the optimal number of shots. To bypass the redundant prefilling computation during both the probing and inference phases, we incorporate a semantics-aware KV cache reuse strategy. Within this reuse strategy, to address positional encoding incompatibilities, we introduce a decoupling and re-encoding method that enables the flexible reordering of cached key-value pairs. Extensive experiments demonstrate that AdapShot achieves an average performance gain of around 10% and a 4.64x speedup compared to state-of-the-art DBSA.
ALTER: Asymmetric LoRA for Token-Entropy-Guided Unlearning of LLMs
Mar 02, 2026Large language models (LLMs) have advanced to encompass extensive knowledge across diverse domains. Yet controlling what a LLMs should not know is important for ensuring alignment and thus safe use. However, effective unlearning in LLMs is difficult due to the fuzzy boundary between knowledge retention and forgetting. This challenge is exacerbated by entangled parameter spaces from continuous multi-domain training, often resulting in collateral damage, especially under aggressive unlearning strategies. Furthermore, the computational overhead required to optimize State-of-the-Art (SOTA) models with billions of parameters poses an additional barrier. In this work, we present ALTER, a lightweight unlearning framework for LLMs to address both the challenges of knowledge entanglement and unlearning efficiency. ALTER operates through two phases: (I) high entropy tokens are captured and learned via the shared A matrix in LoRA, followed by (II) an asymmetric LoRA architecture that achieves a specified forgetting objective by parameter isolation and unlearning tokens within the target subdomains. Serving as a new research direction for achieving unlearning via token-level isolation in the asymmetric framework. ALTER achieves SOTA performance on TOFU, WMDP, and MUSE benchmarks with over 95% forget quality and shows minimal side effects through preserving foundational tokens. By decoupling unlearning from LLMs' billion-scale parameters, this framework delivers excellent efficiency while preserving over 90% of model utility, exceeding baseline preservation rates of 47.8-83.6%.
DoCIA: An Online Document-Level Context Incorporation Agent for Speech Translation
Apr 07, 2025Document-level context is crucial for handling discourse challenges in text-to-text document-level machine translation (MT). Despite the increased discourse challenges introduced by noise from automatic speech recognition (ASR), the integration of document-level context in speech translation (ST) remains insufficiently explored. In this paper, we develop DoCIA, an online framework that enhances ST performance by incorporating document-level context. DoCIA decomposes the ST pipeline into four stages. Document-level context is integrated into the ASR refinement, MT, and MT refinement stages through auxiliary LLM (large language model)-based modules. Furthermore, DoCIA leverages document-level information in a multi-level manner while minimizing computational overhead. Additionally, a simple yet effective determination mechanism is introduced to prevent hallucinations from excessive refinement, ensuring the reliability of the final results. Experimental results show that DoCIA significantly outperforms traditional ST baselines in both sentence and discourse metrics across four LLMs, demonstrating its effectiveness in improving ST performance.
Enhancing Speech Large Language Models with Prompt-Aware Mixture of Audio Encoders
Feb 21, 2025Connecting audio encoders with large language models (LLMs) allows the LLM to perform various audio understanding tasks, such as automatic speech recognition (ASR) and audio captioning (AC). Most research focuses on training an adapter layer to generate a unified audio feature for the LLM. However, different tasks may require distinct features that emphasize either semantic or acoustic aspects, making task-specific audio features more desirable. In this paper, we propose Prompt-aware Mixture (PaM) to enhance the Speech LLM that uses multiple audio encoders. Our approach involves using different experts to extract different features based on the prompt that indicates different tasks. Experiments demonstrate that with PaM, only one Speech LLM surpasses the best performances achieved by all single-encoder Speech LLMs on ASR, Speaker Number Verification, and AC tasks. PaM also outperforms other feature fusion baselines, such as concatenation and averaging.
Optimizing Speech Multi-View Feature Fusion through Conditional Computation
Jan 14, 2025Recent advancements have highlighted the efficacy of self-supervised learning (SSL) features in various speech-related tasks, providing lightweight and versatile multi-view speech representations. However, our study reveals that while SSL features expedite model convergence, they conflict with traditional spectral features like FBanks in terms of update directions. In response, we propose a novel generalized feature fusion framework grounded in conditional computation, featuring a gradient-sensitive gating network and a multi-stage dropout strategy. This framework mitigates feature conflicts and bolsters model robustness to multi-view input features. By integrating SSL and spectral features, our approach accelerates convergence and maintains performance on par with spectral models across multiple speech translation tasks on the MUSTC dataset.
Investigating Numerical Translation with Large Language Models
Jan 09, 2025


The inaccurate translation of numbers can lead to significant security issues, ranging from financial setbacks to medical inaccuracies. While large language models (LLMs) have made significant advancements in machine translation, their capacity for translating numbers has not been thoroughly explored. This study focuses on evaluating the reliability of LLM-based machine translation systems when handling numerical data. In order to systematically test the numerical translation capabilities of currently open source LLMs, we have constructed a numerical translation dataset between Chinese and English based on real business data, encompassing ten types of numerical translation. Experiments on the dataset indicate that errors in numerical translation are a common issue, with most open-source LLMs faltering when faced with our test scenarios. Especially when it comes to numerical types involving large units like ``million", ``billion", and "yi", even the latest llama3.1 8b model can have error rates as high as 20%. Finally, we introduce three potential strategies to mitigate the numerical mistranslations for large units.
"I've Heard of You!": Generate Spoken Named Entity Recognition Data for Unseen Entities
Dec 26, 2024



Spoken named entity recognition (NER) aims to identify named entities from speech, playing an important role in speech processing. New named entities appear every day, however, annotating their Spoken NER data is costly. In this paper, we demonstrate that existing Spoken NER systems perform poorly when dealing with previously unseen named entities. To tackle this challenge, we propose a method for generating Spoken NER data based on a named entity dictionary (NED) to reduce costs. Specifically, we first use a large language model (LLM) to generate sentences from the sampled named entities and then use a text-to-speech (TTS) system to generate the speech. Furthermore, we introduce a noise metric to filter out noisy data. To evaluate our approach, we release a novel Spoken NER benchmark along with a corresponding NED containing 8,853 entities. Experiment results show that our method achieves state-of-the-art (SOTA) performance in the in-domain, zero-shot domain adaptation, and fully zero-shot settings. Our data will be available at https://github.com/DeepLearnXMU/HeardU.
Hard-Synth: Synthesizing Diverse Hard Samples for ASR using Zero-Shot TTS and LLM
Nov 20, 2024



Text-to-speech (TTS) models have been widely adopted to enhance automatic speech recognition (ASR) systems using text-only corpora, thereby reducing the cost of labeling real speech data. Existing research primarily utilizes additional text data and predefined speech styles supported by TTS models. In this paper, we propose Hard-Synth, a novel ASR data augmentation method that leverages large language models (LLMs) and advanced zero-shot TTS. Our approach employs LLMs to generate diverse in-domain text through rewriting, without relying on additional text data. Rather than using predefined speech styles, we introduce a hard prompt selection method with zero-shot TTS to clone speech styles that the ASR model finds challenging to recognize. Experiments demonstrate that Hard-Synth significantly enhances the Conformer model, achieving relative word error rate (WER) reductions of 6.5\%/4.4\% on LibriSpeech dev/test-other subsets. Additionally, we show that Hard-Synth is data-efficient and capable of reducing bias in ASR.
Why Not Transform Chat Large Language Models to Non-English?
May 22, 2024
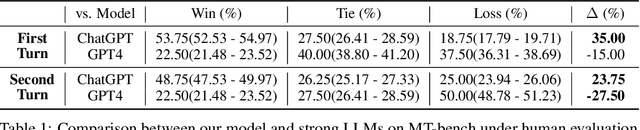


The scarcity of non-English data limits the development of non-English large language models (LLMs). Transforming English-centric LLMs to non-English has been identified as an effective and resource-efficient method. Previous works start from base LLMs and perform knowledge distillation (KD) with data generated by stronger LLMs, e.g. GPT-4. Compared to base LLMs, chat LLMs are further optimized for advanced abilities, e.g. multi-turn conversation and human preference alignment, and thus more powerful in both helpfulness and safety. However, transforming a chat LLM involves two critical issues: (1) How can we effectively transfer advanced abilities without their supervised data? (2) How can we prevent the original knowledge from catastrophic forgetting during transformation? We target these issues by introducing a simple framework called TransLLM. For the first issue, TransLLM divides the transfer problem into some common sub-tasks with the translation chain-of-thought, which uses the translation as the bridge between English and non-English step-by-step. We further enhance the performance of sub-tasks with publicly available data. For the second issue, we propose a method comprising two synergistic components: low-rank adaptation for training to maintain the original LLM parameters, and recovery KD, which utilizes data generated by the chat LLM itself to recover the original knowledge from the frozen parameters. In the experiments, we transform the LLaMA-2-chat-7B to the Thai language. Our method, using only single-turn data, outperforms strong baselines and ChatGPT on multi-turn benchmark MT-bench. Furthermore, our method, without safety data, rejects more harmful queries of safety benchmark AdvBench than both ChatGPT and GPT-4.