 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Nonparametric learning of covariate-based Markov jump processes using RKHS techniques
May 06, 2025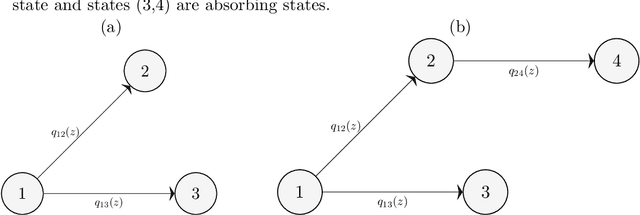



We propose a novel nonparametric approach for linking covariates to Continuous Time Markov Chains (CTMCs) using the mathematical framework of Reproducing Kernel Hilbert Spaces (RKHS). CTMCs provide a robust framework for modeling transitions across clinical or behavioral states, but traditional multistate models often rely on linear relationships. In contrast, we use a generalized Representer Theorem to enable tractable inference in functional space. For the Frequentist version, we apply normed square penalties, while for the Bayesian version, we explore sparsity inducing spike and slab priors. Due to the computational challenges posed by high-dimensional spaces, we successfully adapt the Expectation Maximization Variable Selection (EMVS) algorithm to efficiently identify the posterior mode. We demonstrate the effectiveness of our method through extensive simulation studies and an application to follicular cell lymphoma data. Our performance metrics include the normalized difference between estimated and true nonlinear transition functions, as well as the difference in the probability of getting absorbed in one the final states, capturing the ability of our approach to predict long-term behaviors.
Effect of Selection Format on LLM Performance
Mar 10, 2025This paper investigates a critical aspect of large language model (LLM) performance: the optimal formatting of classification task options in prompts. Through an extensive experimental study, we compared two selection formats -- bullet points and plain English -- to determine their impact on model performance. Our findings suggest that presenting options via bullet points generally yields better results, although there are some exceptions. Furthermore, our research highlights the need for continued exploration of option formatting to drive further improvements in model performance.
Optimizing Speech Multi-View Feature Fusion through Conditional Computation
Jan 14, 2025Recent advancements have highlighted the efficacy of self-supervised learning (SSL) features in various speech-related tasks, providing lightweight and versatile multi-view speech representations. However, our study reveals that while SSL features expedite model convergence, they conflict with traditional spectral features like FBanks in terms of update directions. In response, we propose a novel generalized feature fusion framework grounded in conditional computation, featuring a gradient-sensitive gating network and a multi-stage dropout strategy. This framework mitigates feature conflicts and bolsters model robustness to multi-view input features. By integrating SSL and spectral features, our approach accelerates convergence and maintains performance on par with spectral models across multiple speech translation tasks on the MUSTC dataset.
Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction
Feb 29, 2024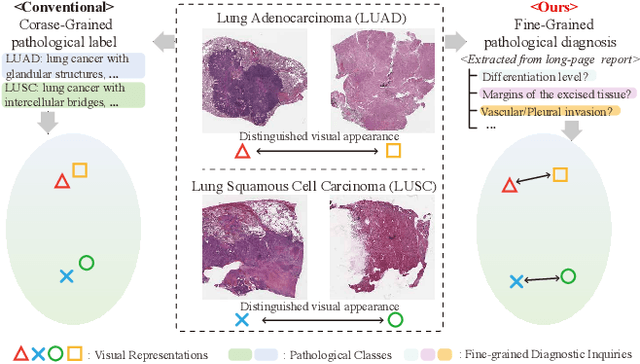

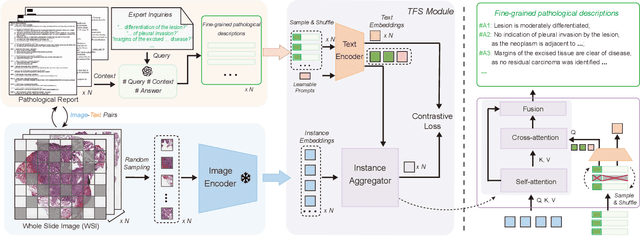
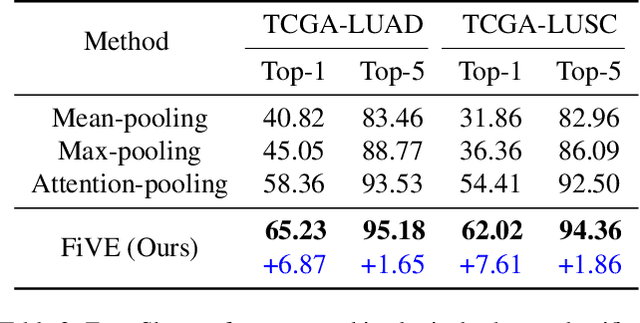
Whole Slide Image (WSI) classification is often formulated as a Multiple Instance Learning (MIL) problem. Recently, Vision-Language Models (VLMs) have demonstrated remarkable performance in WSI classification. However, existing methods leverage coarse-grained pathogenetic descriptions for visual representation supervision, which are insufficient to capture the complex visual appearance of pathogenetic images, hindering the generalizability of models on diverse downstream tasks. Additionally, processing high-resolution WSIs can be computationally expensive. In this paper, we propose a novel "Fine-grained Visual-Semantic Interaction" (FiVE) framework for WSI classification. It is designed to enhance the model's generalizability by leveraging the interplay between localized visual patterns and fine-grained pathological semantics. Specifically, with meticulously designed queries, we start by utilizing a large language model to extract fine-grained pathological descriptions from various non-standardized raw reports. The output descriptions are then reconstructed into fine-grained labels used for training. By introducing a Task-specific Fine-grained Semantics (TFS) module, we enable prompts to capture crucial visual information in WSIs, which enhances representation learning and augments generalization capabilities significantly. Furthermore, given that pathological visual patterns are redundantly distributed across tissue slices, we sample a subset of visual instances during training. Our method demonstrates robust generalizability and strong transferability, dominantly outperforming the counterparts on the TCGA Lung Cancer dataset with at least 9.19% higher accuracy in few-shot experiments.
Modality Adaption or Regularization? A Case Study on End-to-End Speech Translation
Jun 13, 2023Pre-training and fine-tuning is a paradigm for alleviating the data scarcity problem in end-to-end speech translation (E2E ST). The commonplace "modality gap" between speech and text data often leads to inconsistent inputs between pre-training and fine-tuning. However, we observe that this gap occurs in the early stages of fine-tuning, but does not have a major impact on the final performance. On the other hand, we find that there has another gap, which we call the "capacity gap": high resource tasks (such as ASR and MT) always require a large model to fit, when the model is reused for a low resource task (E2E ST), it will get a sub-optimal performance due to the over-fitting. In a case study, we find that the regularization plays a more important role than the well-designed modality adaption method, which achieves 29.0 for en-de and 40.3 for en-fr on the MuST-C dataset. Code and models are available at https://github.com/hannlp/TAB.