 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Adaptive Prototype Manifolds for Out-of-Distribution Detection
Feb 05, 2026Out-of-distribution (OOD) detection is a critical task for the safe deployment of machine learning models in the real world. Existing prototype-based representation learning methods have demonstrated exceptional performance. Specifically, we identify two fundamental flaws that universally constrain these methods: the Static Homogeneity Assumption (fixed representational resources for all classes) and the Learning-Inference Disconnect (discarding rich prototype quality knowledge at inference). These flaws fundamentally limit the model's capacity and performance. To address these issues, we propose APEX (Adaptive Prototype for eXtensive OOD Detection), a novel OOD detection framework designed via a Two-Stage Repair process to optimize the learned feature manifold. APEX introduces two key innovations to address these respective flaws: (1) an Adaptive Prototype Manifold (APM), which leverages the Minimum Description Length (MDL) principle to automatically determine the optimal prototype complexity $K_c^*$ for each class, thereby fundamentally resolving prototype collision; and (2) a Posterior-Aware OOD Scoring (PAOS) mechanism, which quantifies prototype quality (cohesion and separation) to bridge the learning-inference disconnect. Comprehensive experiments on benchmarks such as CIFAR-100 validate the superiority of our method, where APEX achieves new state-of-the-art performance.
Breaking Semantic Hegemony: Decoupling Principal and Residual Subspaces for Generalized OOD Detection
Feb 05, 2026While feature-based post-hoc methods have made significant strides in Out-of-Distribution (OOD) detection, we uncover a counter-intuitive Simplicity Paradox in existing state-of-the-art (SOTA) models: these models exhibit keen sensitivity in distinguishing semantically subtle OOD samples but suffer from severe Geometric Blindness when confronting structurally distinct yet semantically simple samples or high-frequency sensor noise. We attribute this phenomenon to Semantic Hegemony within the deep feature space and reveal its mathematical essence through the lens of Neural Collapse. Theoretical analysis demonstrates that the spectral concentration bias, induced by the high variance of the principal subspace, numerically masks the structural distribution shift signals that should be significant in the residual subspace. To address this issue, we propose D-KNN, a training-free, plug-and-play geometric decoupling framework. This method utilizes orthogonal decomposition to explicitly separate semantic components from structural residuals and introduces a dual-space calibration mechanism to reactivate the model's sensitivity to weak residual signals. Extensive experiments demonstrate that D-KNN effectively breaks Semantic Hegemony, establishing new SOTA performance on both CIFAR and ImageNet benchmarks. Notably, in resolving the Simplicity Paradox, it reduces the FPR95 from 31.3% to 2.3%; when addressing sensor failures such as Gaussian noise, it boosts the detection performance (AUROC) from a baseline of 79.7% to 94.9%.
VMF-GOS: Geometry-guided virtual Outlier Synthesis for Long-Tailed OOD Detection
Feb 05, 2026Out-of-Distribution (OOD) detection under long-tailed distributions is a highly challenging task because the scarcity of samples in tail classes leads to blurred decision boundaries in the feature space. Current state-of-the-art (sota) methods typically employ Outlier Exposure (OE) strategies, relying on large-scale real external datasets (such as 80 Million Tiny Images) to regularize the feature space. However, this dependence on external data often becomes infeasible in practical deployment due to high data acquisition costs and privacy sensitivity. To this end, we propose a novel data-free framework aimed at completely eliminating reliance on external datasets while maintaining superior detection performance. We introduce a Geometry-guided virtual Outlier Synthesis (GOS) strategy that models statistical properties using the von Mises-Fisher (vMF) distribution on a hypersphere. Specifically, we locate a low-likelihood annulus in the feature space and perform directional sampling of virtual outliers in this region. Simultaneously, we introduce a new Dual-Granularity Semantic Loss (DGS) that utilizes contrastive learning to maximize the distinction between in-distribution (ID) features and these synthesized boundary outliers. Extensive experiments on benchmarks such as CIFAR-LT demonstrate that our method outperforms sota approaches that utilize external real images.
Robust Uncertainty Quantification for Factual Generation of Large Language Models
Jan 01, 2026The rapid advancement of large language model(LLM) technology has facilitated its integration into various domains of professional and daily life. However, the persistent challenge of LLM hallucination has emerged as a critical limitation, significantly compromising the reliability and trustworthiness of AI-generated content. This challenge has garnered significant attention within the scientific community, prompting extensive research efforts in hallucination detection and mitigation strategies. Current methodological frameworks reveal a critical limitation: traditional uncertainty quantification approaches demonstrate effectiveness primarily within conventional question-answering paradigms, yet exhibit notable deficiencies when confronted with non-canonical or adversarial questioning strategies. This performance gap raises substantial concerns regarding the dependability of LLM responses in real-world applications requiring robust critical thinking capabilities. This study aims to fill this gap by proposing an uncertainty quantification scenario in the task of generating with multiple facts. We have meticulously constructed a set of trap questions contained with fake names. Based on this scenario, we innovatively propose a novel and robust uncertainty quantification method(RU). A series of experiments have been conducted to verify its effectiveness. The results show that the constructed set of trap questions performs excellently. Moreover, when compared with the baseline methods on four different models, our proposed method has demonstrated great performance, with an average increase of 0.1-0.2 in ROCAUC values compared to the best performing baseline method, providing new sights and methods for addressing the hallucination issue of LLMs.
* 9 pages, 5 tables, 5 figures, accepted to IJCNN 2025
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
LLM$^3$-DTI: A Large Language Model and Multi-modal data co-powered framework for Drug-Target Interaction prediction
Nov 09, 2025Drug-target interaction (DTI) prediction is of great significance for drug discovery and drug repurposing. With the accumulation of a large volume of valuable data, data-driven methods have been increasingly harnessed to predict DTIs, reducing costs across various dimensions. Therefore, this paper proposes a $\textbf{L}$arge $\textbf{L}$anguage $\textbf{M}$odel and $\textbf{M}$ulti-$\textbf{M}$odel data co-powered $\textbf{D}$rug $\textbf{T}$arget $\textbf{I}$nteraction prediction framework, named LLM$^3$-DTI. LLM$^3$-DTI constructs multi-modal data embedding to enhance DTI prediction performance. In this framework, the text semantic embeddings of drugs and targets are encoded by a domain-specific LLM. To effectively align and fuse multi-modal embedding. We propose the dual cross-attention mechanism and the TSFusion module. Finally, these multi-modal data are utilized for the DTI task through an output network. The experimental results indicate that LLM$^3$-DTI can proficiently identify validated DTIs, surpassing the performance of the models employed for comparison across diverse scenarios. Consequently, LLM$^3$-DTI is adept at fulfilling the task of DTI prediction with excellence. The data and code are available at https://github.com/chaser-gua/LLM3DTI.
GeoFM: Enhancing Geometric Reasoning of MLLMs via Synthetic Data Generation through Formal Language
Oct 31, 2025



Multi-modal Large Language Models (MLLMs) have gained significant attention in both academia and industry for their capabilities in handling multi-modal tasks. However, these models face challenges in mathematical geometric reasoning due to the scarcity of high-quality geometric data. To address this issue, synthetic geometric data has become an essential strategy. Current methods for generating synthetic geometric data involve rephrasing or expanding existing problems and utilizing predefined rules and templates to create geometric images and problems. However, these approaches often produce data that lacks diversity or is prone to noise. Additionally, the geometric images synthesized by existing methods tend to exhibit limited variation and deviate significantly from authentic geometric diagrams. To overcome these limitations, we propose GeoFM, a novel method for synthesizing geometric data. GeoFM uses formal languages to explore combinations of conditions within metric space, generating high-fidelity geometric problems that differ from the originals while ensuring correctness through a symbolic engine. Experimental results show that our synthetic data significantly outperforms existing methods. The model trained with our data surpass the proprietary GPT-4o model by 18.7\% on geometry problem-solving tasks in MathVista and by 16.5\% on GeoQA. Additionally, it exceeds the performance of a leading open-source model by 5.7\% on MathVista and by 2.7\% on GeoQA.
UNILocPro: Unified Localization Integrating Model-Based Geometry and Channel Charting
Oct 31, 2025In this paper, we propose a unified localization framework (called UNILocPro) that integrates model-based localization and channel charting (CC) for mixed line-of-sight (LoS)/non-line-of-sight (NLoS) scenarios. Specifically, based on LoS/NLoS identification, an adaptive activation between the model-based and CC-based methods is conducted. Aiming for unsupervised learning, information obtained from the model-based method is utilized to train the CC model, where a pairwise distance loss (involving a new dissimilarity metric design), a triplet loss (if timestamps are available), a LoS-based loss, and an optimal transport (OT)-based loss are jointly employed such that the global geometry can be well preserved. To reduce the training complexity of UNILocPro, we propose a low-complexity implementation (called UNILoc), where the CC model is trained with self-generated labels produced by a single pre-training OT transformation, which avoids iterative Sinkhorn updates involved in the OT-based loss computation. Extensive numerical experiments demonstrate that the proposed unified frameworks achieve significantly improved positioning accuracy compared to both model-based and CC-based methods. Notably, UNILocPro with timestamps attains performance on par with fully-supervised fingerprinting despite operating without labelled training data. It is also shown that the low-complexity UNILoc can substantially reduce training complexity with only marginal performance degradation.
EchoMind: An Interrelated Multi-level Benchmark for Evaluating Empathetic Speech Language Models
Oct 26, 2025Speech Language Models (SLMs) have made significant progress in spoken language understanding. Yet it remains unclear whether they can fully perceive non lexical vocal cues alongside spoken words, and respond with empathy that aligns with both emotional and contextual factors. Existing benchmarks typically evaluate linguistic, acoustic, reasoning, or dialogue abilities in isolation, overlooking the integration of these skills that is crucial for human-like, emotionally intelligent conversation. We present EchoMind, the first interrelated, multi-level benchmark that simulates the cognitive process of empathetic dialogue through sequential, context-linked tasks: spoken-content understanding, vocal-cue perception, integrated reasoning, and response generation. All tasks share identical and semantically neutral scripts that are free of explicit emotional or contextual cues, and controlled variations in vocal style are used to test the effect of delivery independent of the transcript. EchoMind is grounded in an empathy-oriented framework spanning 3 coarse and 12 fine-grained dimensions, encompassing 39 vocal attributes, and evaluated using both objective and subjective metrics. Testing 12 advanced SLMs reveals that even state-of-the-art models struggle with high-expressive vocal cues, limiting empathetic response quality. Analyses of prompt strength, speech source, and ideal vocal cue recognition reveal persistent weaknesses in instruction-following, resilience to natural speech variability, and effective use of vocal cues for empathy. These results underscore the need for SLMs that integrate linguistic content with diverse vocal cues to achieve truly empathetic conversational ability.
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search
Oct 21, 2025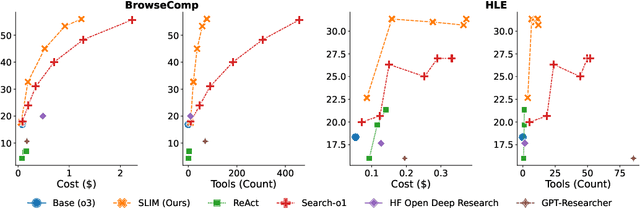



Long-horizon agentic search requires iteratively exploring the web over long trajectories and synthesizing information across many sources, and is the foundation for enabling powerful applications like deep research systems. In this work, we show that popular agentic search frameworks struggle to scale to long trajectories primarily due to context limitations-they accumulate long, noisy content, hit context window and tool budgets, or stop early. Then, we introduce SLIM (Simple Lightweight Information Management), a simple framework that separates retrieval into distinct search and browse tools, and periodically summarizes the trajectory, keeping context concise while enabling longer, more focused searches. On long-horizon tasks, SLIM achieves comparable performance at substantially lower cost and with far fewer tool calls than strong open-source baselines across multiple base models. Specifically, with o3 as the base model, SLIM achieves 56% on BrowseComp and 31% on HLE, outperforming all open-source frameworks by 8 and 4 absolute points, respectively, while incurring 4-6x fewer tool calls. Finally, we release an automated fine-grained trajectory analysis pipeline and error taxonomy for characterizing long-horizon agentic search frameworks; SLIM exhibits fewer hallucinations than prior systems. We hope our analysis framework and simple tool design inform future long-horizon agents.