 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Renaissance of Expert Systems: Optical Recognition of Printed Chinese Jianpu Musical Scores with Lyrics
Dec 15, 2025Large-scale optical music recognition (OMR) research has focused mainly on Western staff notation, leaving Chinese Jianpu (numbered notation) and its rich lyric resources underexplored. We present a modular expert-system pipeline that converts printed Jianpu scores with lyrics into machine-readable MusicXML and MIDI, without requiring massive annotated training data. Our approach adopts a top-down expert-system design, leveraging traditional computer-vision techniques (e.g., phrase correlation, skeleton analysis) to capitalize on prior knowledge, while integrating unsupervised deep-learning modules for image feature embeddings. This hybrid strategy strikes a balance between interpretability and accuracy. Evaluated on The Anthology of Chinese Folk Songs, our system massively digitizes (i) a melody-only collection of more than 5,000 songs (> 300,000 notes) and (ii) a curated subset with lyrics comprising over 1,400 songs (> 100,000 notes). The system achieves high-precision recognition on both melody (note-wise F1 = 0.951) and aligned lyrics (character-wise F1 = 0.931).
S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information
Mar 07, 2025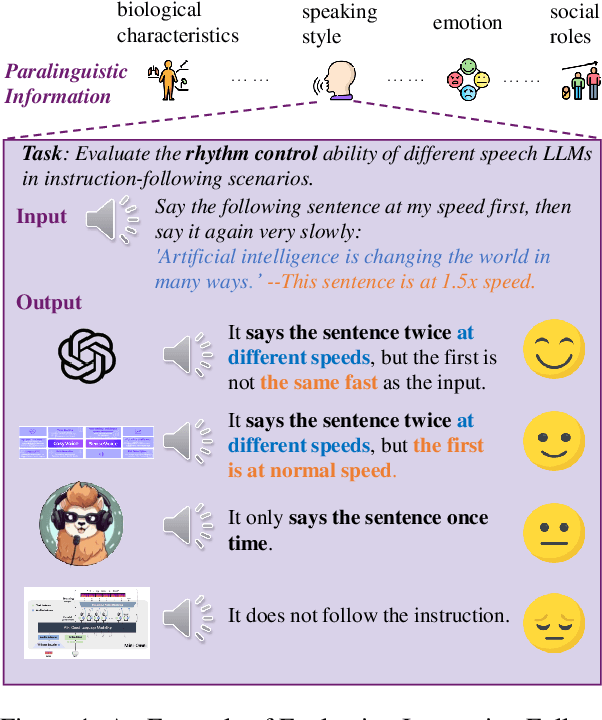
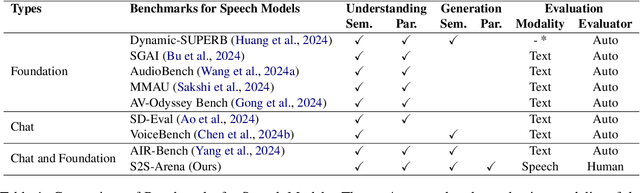

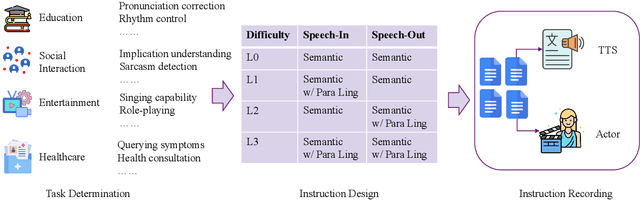
The rapid development of large language models (LLMs) has brought significant attention to speech models, particularly recent progress in speech2speech protocols supporting speech input and output. However, the existing benchmarks adopt automatic text-based evaluators for evaluating the instruction following ability of these models lack consideration for paralinguistic information in both speech understanding and generation. To address these issues, we introduce S2S-Arena, a novel arena-style S2S benchmark that evaluates instruction-following capabilities with paralinguistic information in both speech-in and speech-out across real-world tasks. We design 154 samples that fused TTS and live recordings in four domains with 21 tasks and manually evaluate existing popular speech models in an arena-style manner. The experimental results show that: (1) in addition to the superior performance of GPT-4o, the speech model of cascaded ASR, LLM, and TTS outperforms the jointly trained model after text-speech alignment in speech2speech protocols; (2) considering paralinguistic information, the knowledgeability of the speech model mainly depends on the LLM backbone, and the multilingual support of that is limited by the speech module; (3) excellent speech models can already understand the paralinguistic information in speech input, but generating appropriate audio with paralinguistic information is still a challenge.
Soundwave: Less is More for Speech-Text Alignment in LLMs
Feb 18, 2025Existing end-to-end speech large language models (LLMs) usually rely on large-scale annotated data for training, while data-efficient training has not been discussed in depth. We focus on two fundamental problems between speech and text: the representation space gap and sequence length inconsistency. We propose Soundwave, which utilizes an efficient training strategy and a novel architecture to address these issues. Results show that Soundwave outperforms the advanced Qwen2-Audio in speech translation and AIR-Bench speech tasks, using only one-fiftieth of the training data. Further analysis shows that Soundwave still retains its intelligence during conversation. The project is available at https://github.com/FreedomIntelligence/Soundwave.
An Investigation into Value Misalignment in LLM-Generated Texts for Cultural Heritage
Jan 03, 2025



As Large Language Models (LLMs) become increasingly prevalent in tasks related to cultural heritage, such as generating descriptions of historical monuments, translating ancient texts, preserving oral traditions, and creating educational content, their ability to produce accurate and culturally aligned texts is being increasingly relied upon by users and researchers. However, cultural value misalignments may exist in generated texts, such as the misrepresentation of historical facts, the erosion of cultural identity, and the oversimplification of complex cultural narratives, which may lead to severe consequences. Therefore, investigating value misalignment in the context of LLM for cultural heritage is crucial for mitigating these risks, yet there has been a significant lack of systematic and comprehensive study and investigation in this area. To fill this gap, we systematically assess the reliability of LLMs in generating culturally aligned texts for cultural heritage-related tasks. We conduct a comprehensive evaluation by compiling an extensive set of 1066 query tasks covering 5 widely recognized categories with 17 aspects within the knowledge framework of cultural heritage across 5 open-source LLMs, and examine both the type and rate of cultural value misalignments in the generated texts. Using both automated and manual approaches, we effectively detect and analyze the cultural value misalignments in LLM-generated texts. Our findings are concerning: over 65% of the generated texts exhibit notable cultural misalignments, with certain tasks demonstrating almost complete misalignment with key cultural values. Beyond these findings, this paper introduces a benchmark dataset and a comprehensive evaluation workflow that can serve as a valuable resource for future research aimed at enhancing the cultural sensitivity and reliability of LLMs.
Roadmap towards Superhuman Speech Understanding using Large Language Models
Oct 17, 2024



The success of large language models (LLMs) has prompted efforts to integrate speech and audio data, aiming to create general foundation models capable of processing both textual and non-textual inputs. Recent advances, such as GPT-4o, highlight the potential for end-to-end speech LLMs, which preserves non-semantic information and world knowledge for deeper speech understanding. To guide the development of speech LLMs, we propose a five-level roadmap, ranging from basic automatic speech recognition (ASR) to advanced superhuman models capable of integrating non-semantic information with abstract acoustic knowledge for complex tasks. Moreover, we design a benchmark, SAGI Bechmark, that standardizes critical aspects across various tasks in these five levels, uncovering challenges in using abstract acoustic knowledge and completeness of capability. Our findings reveal gaps in handling paralinguistic cues and abstract acoustic knowledge, and we offer future directions. This paper outlines a roadmap for advancing speech LLMs, introduces a benchmark for evaluation, and provides key insights into their current limitations and potential.
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024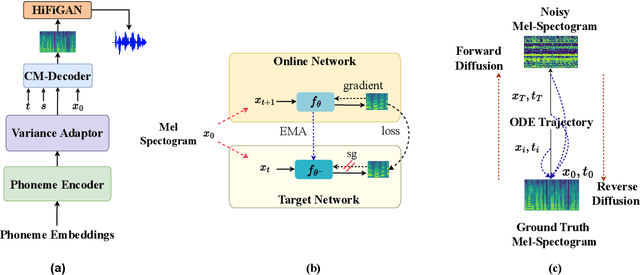
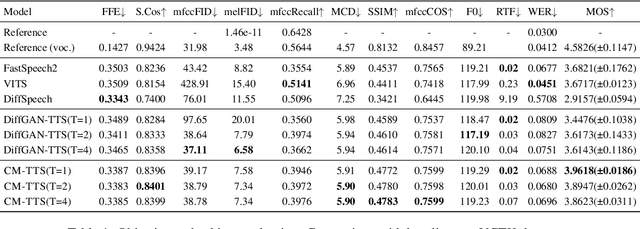
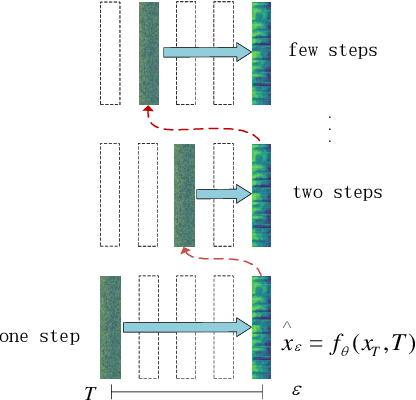

Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.
Towards Provably Not-at-Fault Control of Autonomous Robots in Arbitrary Dynamic Environments
Feb 07, 2019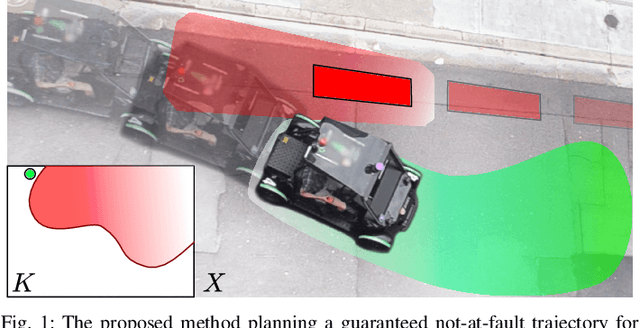
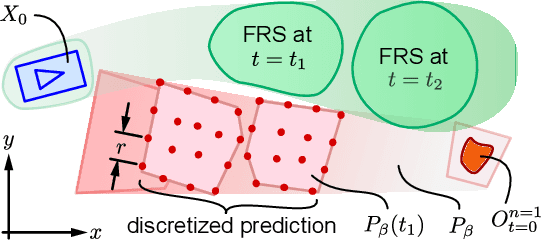

As autonomous robots increasingly become part of daily life, they will often encounter dynamic environments while only having limited information about their surroundings. Unfortunately, due to the possible presence of malicious dynamic actors, it is infeasible to develop an algorithm that can guarantee collision-free operation. Instead, one can attempt to design a control technique that guarantees the robot is not-at-fault in any collision. In the literature, making such guarantees in real time has been restricted to static environments or specific dynamic models. To ensure not-at-fault behavior, a robot must first correctly sense and predict the world around it within some sufficiently large sensor horizon (the prediction problem), then correctly control relative to the predictions (the control problem). This paper addresses the control problem by proposing Reachability-based Trajectory Design for Dynamic environments (RTD-D), which guarantees that a robot with an arbitrary nonlinear dynamic model correctly responds to predictions in arbitrary dynamic environments. RTD-D first computes a Forward Reachable Set (FRS) offline of the robot tracking parameterized desired trajectories that include fail-safe maneuvers. Then, for online receding-horizon planning, the method provides a way to discretize predictions of an arbitrary dynamic environment to enable real-time collision checking. The FRS is used to map these discretized predictions to trajectories that the robot can track while provably not-at-fault. One such trajectory is chosen at each iteration, or the robot executes the fail-safe maneuver from its previous trajectory which is guaranteed to be not at fault. RTD-D is shown to produce not-at-fault behavior over thousands of simulations and several real-world hardware demonstrations on two robots: a Segway, and a small electric vehicle.
Bridging the Gap Between Safety and Real-Time Performance in Receding-Horizon Trajectory Design for Mobile Robots
Sep 18, 2018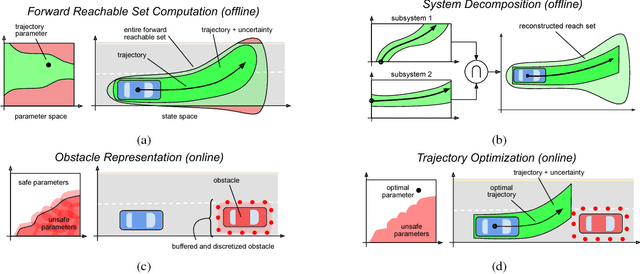
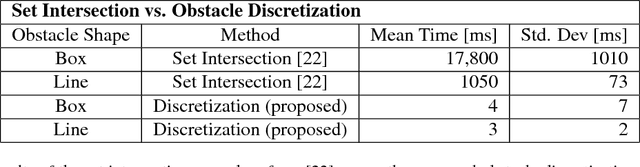

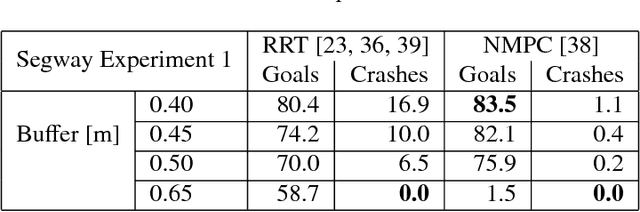
Autonomous mobile robots must operate with limited sensor horizons in unpredictable environments. To do so, they use a receding-horizon strategy to plan trajectories, by executing a short plan while creating the next plan. However, creating safe, dynamically-feasible trajectories in real time is challenging; and, planners must ensure that they are persistently feasible, meaning that a new trajectory is always available before the previous one has finished executing. Existing approaches make a tradeoff between model complexity and planning speed, which can require sacrificing guarantees of safety and dynamic feasibility. This work presents the Reachability-based Trajectory Design (RTD) method for trajectory planning. RTD begins with an offline Forward Reachable Set (FRS) computation of a robot's motion while it tracks parameterized trajectories; the FRS also provably bounds tracking error. At runtime, the FRS is used to map obstacles to the space of parameterized trajectories, which allows RTD to select a safe trajectory at every planning iteration. RTD prescribes a method of representing obstacles to ensure that these constraints can be created and evaluated in real time while maintaining provable safety. Persistent feasibility is achieved by prescribing a minimum duration of planned trajectories, and a minimum sensor horizon. A system decomposition approach is used to increase the dimension of the parameterized trajectories in the FRS, allowing for RTD to create more complex plans at runtime. RTD is compared in simulation with Rapidly-exploring Random Trees (RRT) and Nonlinear Model-Predictive Control (NMPC). RTD is also demonstrated on two hardware platforms in randomly-crafted environments: a differential-drive Segway, and a car-like Rover. The proposed method is shown as safe and persistently feasible across thousands of simulations and dozens of hardware demos.
The Evolution of Popularity and Images of Characters in Marvel Cinematic Universe Fanfictions
May 10, 2018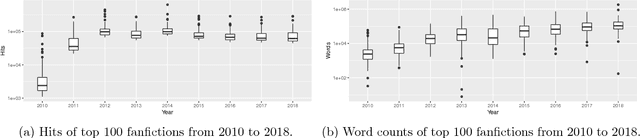
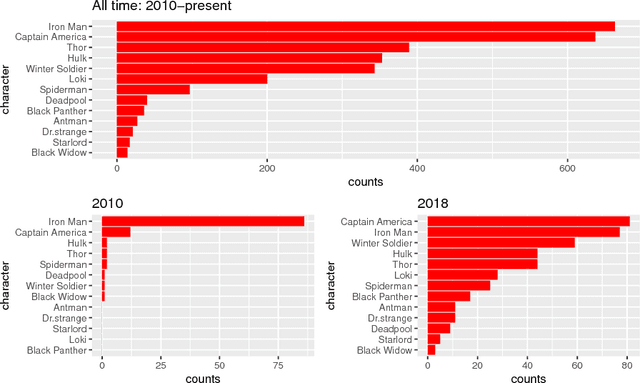
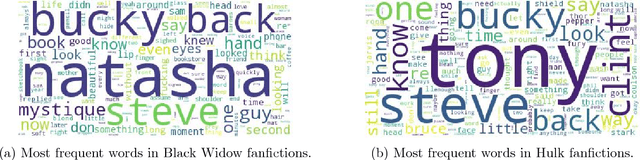
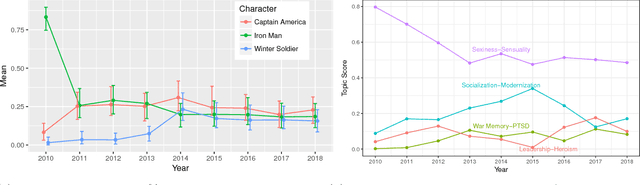
This analysis proposes a new topic model to study the yearly trends in Marvel Cinematic Universe fanfictions on three levels: character popularity, character images/topics, and vocabulary pattern of topics. It is found that character appearances in fanfictions have become more diverse over the years thanks to constant introduction of new characters in feature films, and in the case of Captain America, multi-dimensional character development is well-received by the fanfiction world.