 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-view Landmark Representation Approach with Application to GNSS-Visual-Inertial Odometry
Aug 07, 2025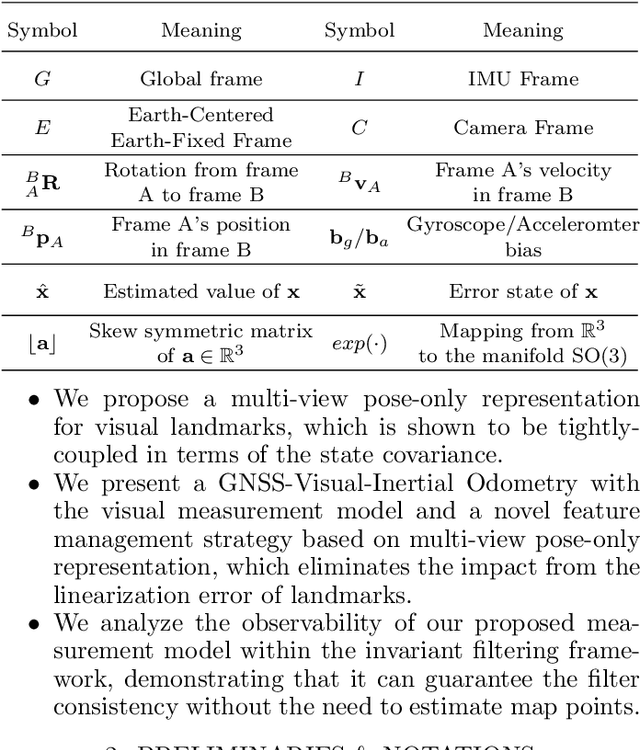
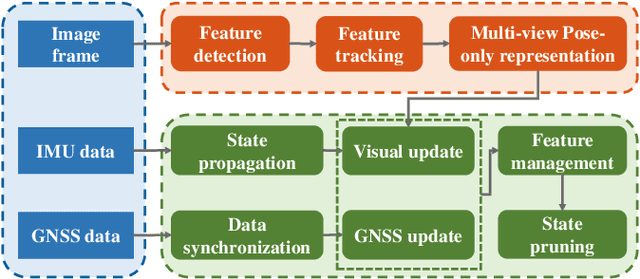
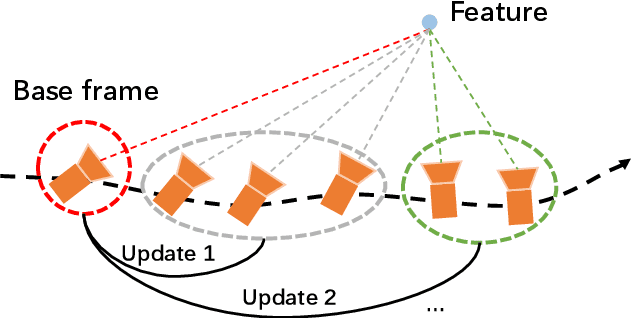
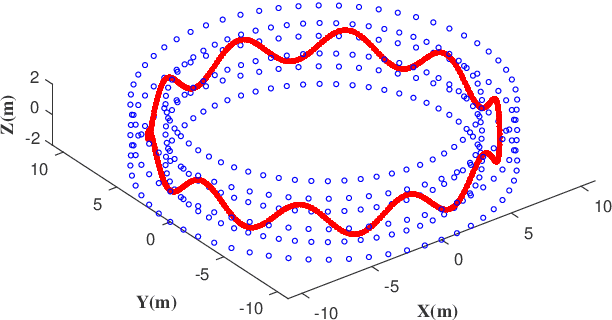
Invariant Extended Kalman Filter (IEKF) has been a significant technique in vision-aided sensor fusion. However, it usually suffers from high computational burden when jointly optimizing camera poses and the landmarks. To improve its efficiency and applicability for multi-sensor fusion, we present a multi-view pose-only estimation approach with its application to GNSS-Visual-Inertial Odometry (GVIO) in this paper. Our main contribution is deriving a visual measurement model which directly associates landmark representation with multiple camera poses and observations. Such a pose-only measurement is proven to be tightly-coupled between landmarks and poses, and maintain a perfect null space that is independent of estimated poses. Finally, we apply the proposed approach to a filter based GVIO with a novel feature management strategy. Both simulation tests and real-world experiments are conducted to demonstrate the superiority of the proposed method in terms of efficiency and accuracy.
DLP: Dynamic Layerwise Pruning in Large Language Models
May 27, 2025Pruning has recently been widely adopted to reduce the parameter scale and improve the inference efficiency of Large Language Models (LLMs). Mainstream pruning techniques often rely on uniform layerwise pruning strategies, which can lead to severe performance degradation at high sparsity levels. Recognizing the varying contributions of different layers in LLMs, recent studies have shifted their focus toward non-uniform layerwise pruning. However, these approaches often rely on pre-defined values, which can result in suboptimal performance. To overcome these limitations, we propose a novel method called Dynamic Layerwise Pruning (DLP). This approach adaptively determines the relative importance of each layer by integrating model weights with input activation information, assigning pruning rates accordingly. Experimental results show that DLP effectively preserves model performance at high sparsity levels across multiple LLMs. Specifically, at 70% sparsity, DLP reduces the perplexity of LLaMA2-7B by 7.79 and improves the average accuracy by 2.7% compared to state-of-the-art methods. Moreover, DLP is compatible with various existing LLM compression techniques and can be seamlessly integrated into Parameter-Efficient Fine-Tuning (PEFT). We release the code at https://github.com/ironartisan/DLP to facilitate future research.
Incentivizing Truthful Language Models via Peer Elicitation Games
May 19, 2025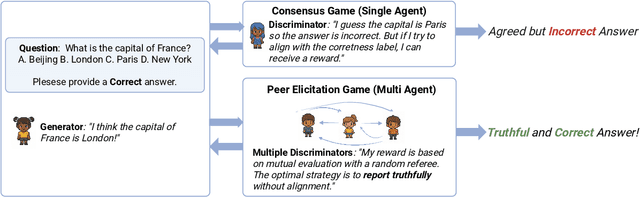
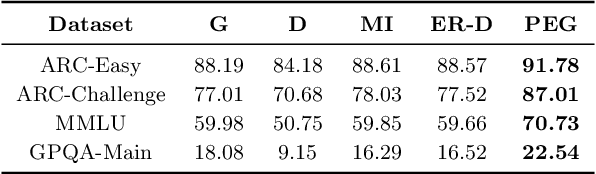
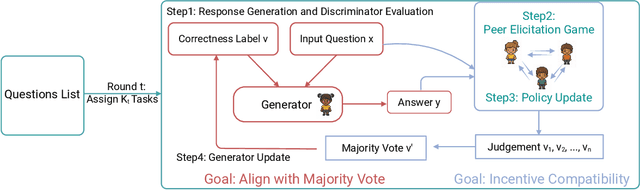

Large Language Models (LLMs) have demonstrated strong generative capabilities but remain prone to inconsistencies and hallucinations. We introduce Peer Elicitation Games (PEG), a training-free, game-theoretic framework for aligning LLMs through a peer elicitation mechanism involving a generator and multiple discriminators instantiated from distinct base models. Discriminators interact in a peer evaluation setting, where rewards are computed using a determinant-based mutual information score that provably incentivizes truthful reporting without requiring ground-truth labels. We establish theoretical guarantees showing that each agent, via online learning, achieves sublinear regret in the sense their cumulative performance approaches that of the best fixed truthful strategy in hindsight. Moreover, we prove last-iterate convergence to a truthful Nash equilibrium, ensuring that the actual policies used by agents converge to stable and truthful behavior over time. Empirical evaluations across multiple benchmarks demonstrate significant improvements in factual accuracy. These results position PEG as a practical approach for eliciting truthful behavior from LLMs without supervision or fine-tuning.
DialogueAgents: A Hybrid Agent-Based Speech Synthesis Framework for Multi-Party Dialogue
Apr 20, 2025Speech synthesis is crucial for human-computer interaction, enabling natural and intuitive communication. However, existing datasets involve high construction costs due to manual annotation and suffer from limited character diversity, contextual scenarios, and emotional expressiveness. To address these issues, we propose DialogueAgents, a novel hybrid agent-based speech synthesis framework, which integrates three specialized agents -- a script writer, a speech synthesizer, and a dialogue critic -- to collaboratively generate dialogues. Grounded in a diverse character pool, the framework iteratively refines dialogue scripts and synthesizes speech based on speech review, boosting emotional expressiveness and paralinguistic features of the synthesized dialogues. Using DialogueAgent, we contribute MultiTalk, a bilingual, multi-party, multi-turn speech dialogue dataset covering diverse topics. Extensive experiments demonstrate the effectiveness of our framework and the high quality of the MultiTalk dataset. We release the dataset and code https://github.com/uirlx/DialogueAgents to facilitate future research on advanced speech synthesis models and customized data generation.
CEFW: A Comprehensive Evaluation Framework for Watermark in Large Language Models
Mar 24, 2025Text watermarking provides an effective solution for identifying synthetic text generated by large language models. However, existing techniques often focus on satisfying specific criteria while ignoring other key aspects, lacking a unified evaluation. To fill this gap, we propose the Comprehensive Evaluation Framework for Watermark (CEFW), a unified framework that comprehensively evaluates watermarking methods across five key dimensions: ease of detection, fidelity of text quality, minimal embedding cost, robustness to adversarial attacks, and imperceptibility to prevent imitation or forgery. By assessing watermarks according to all these key criteria, CEFW offers a thorough evaluation of their practicality and effectiveness. Moreover, we introduce a simple and effective watermarking method called Balanced Watermark (BW), which guarantees robustness and imperceptibility through balancing the way watermark information is added. Extensive experiments show that BW outperforms existing methods in overall performance across all evaluation dimensions. We release our code to the community for future research. https://github.com/DrankXs/BalancedWatermark.
An Immediate Update Strategy of Multi-State Constraint Kalman Filter
Nov 04, 2024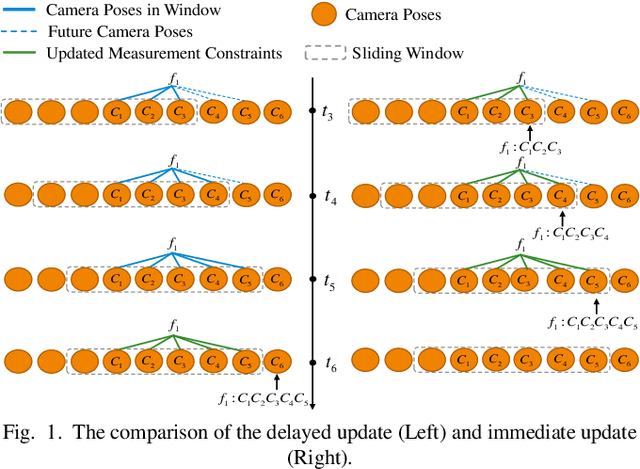
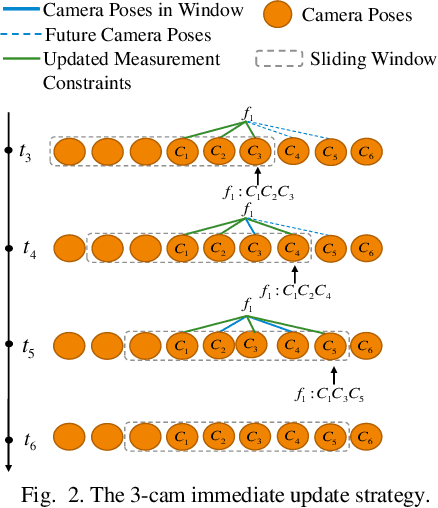
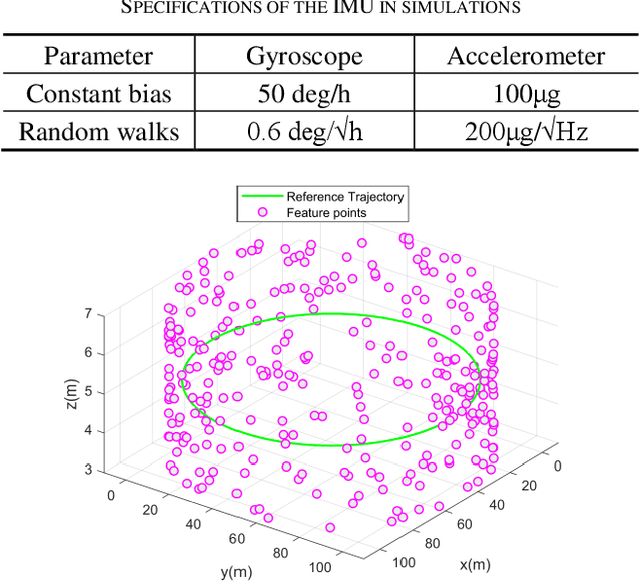
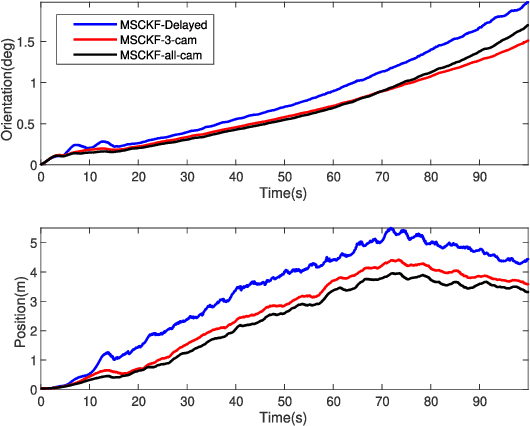
The lightweight Multi-state Constraint Kalman Filter (MSCKF) has been well-known for its high efficiency, in which the delayed update has been usually adopted since its proposal. This work investigates the immediate update strategy of MSCKF based on timely reconstructed 3D feature points and measurement constraints. The differences between the delayed update and the immediate update are theoretically analyzed in detail. It is found that the immediate update helps construct more observation constraints and employ more filtering updates than the delayed update, which improves the linearization point of the measurement model and therefore enhances the estimation accuracy. Numerical simulations and experiments show that the immediate update strategy significantly enhances MSCKF even with a small amount of feature observations.
Conformal Online Auction Design
May 11, 2024



This paper proposes the conformal online auction design (COAD), a novel mechanism for maximizing revenue in online auctions by quantifying the uncertainty in bidders' values without relying on assumptions about value distributions. COAD incorporates both the bidder and item features and leverages historical data to provide an incentive-compatible mechanism for online auctions. Unlike traditional methods for online auctions, COAD employs a distribution-free, prediction interval-based approach using conformal prediction techniques. This novel approach ensures that the expected revenue from our mechanism can achieve at least a constant fraction of the revenue generated by the optimal mechanism. Additionally, COAD admits the use of a broad array of modern machine-learning methods, including random forests, kernel methods, and deep neural nets, for predicting bidders' values. It ensures revenue performance under any finite sample of historical data. Moreover, COAD introduces bidder-specific reserve prices based on the lower confidence bounds of bidders' valuations, which is different from the uniform reserve prices commonly used in the literature. We validate our theoretical predictions through extensive simulations and a real-data application. All code for using COAD and reproducing results is made available on GitHub.
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024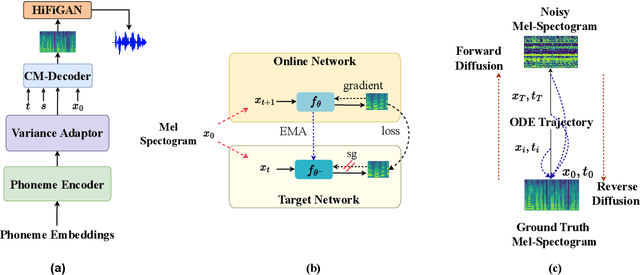
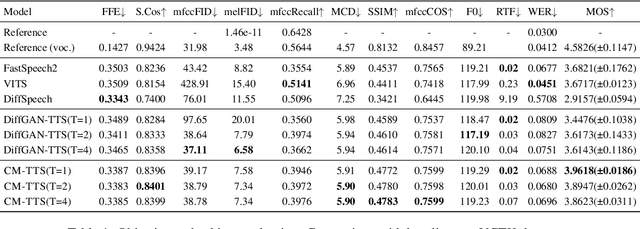
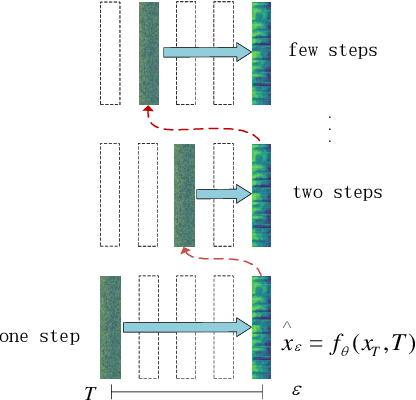

Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.
Making Pre-trained Language Models Better Continual Few-Shot Relation Extractors
Feb 24, 2024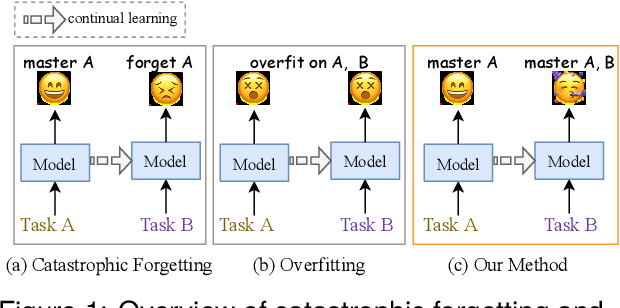
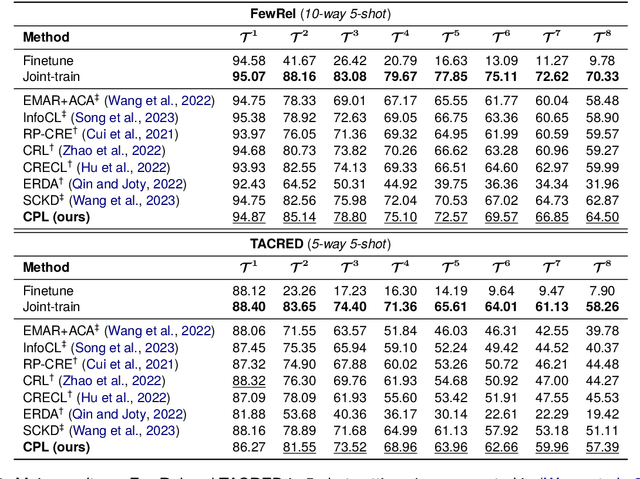


Continual Few-shot Relation Extraction (CFRE) is a practical problem that requires the model to continuously learn novel relations while avoiding forgetting old ones with few labeled training data. The primary challenges are catastrophic forgetting and overfitting. This paper harnesses prompt learning to explore the implicit capabilities of pre-trained language models to address the above two challenges, thereby making language models better continual few-shot relation extractors. Specifically, we propose a Contrastive Prompt Learning framework, which designs prompt representation to acquire more generalized knowledge that can be easily adapted to old and new categories, and margin-based contrastive learning to focus more on hard samples, therefore alleviating catastrophic forgetting and overfitting issues. To further remedy overfitting in low-resource scenarios, we introduce an effective memory augmentation strategy that employs well-crafted prompts to guide ChatGPT in generating diverse samples. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin and significantly mitigates catastrophic forgetting and overfitting in low-resource scenarios.
Robust multi-item auction design using statistical learning: Overcoming uncertainty in bidders' types distributions
Feb 10, 2023



This paper presents a novel mechanism design for multi-item auction settings with uncertain bidders' type distributions. Our proposed approach utilizes nonparametric density estimation to accurately estimate bidders' types from historical bids, and is built upon the Vickrey-Clarke-Groves (VCG) mechanism, ensuring satisfaction of Bayesian incentive compatibility (BIC) and $\delta$-individual rationality (IR). To further enhance the efficiency of our mechanism, we introduce two novel strategies for query reduction: a filtering method that screens potential winners' value regions within the confidence intervals generated by our estimated distribution, and a classification strategy that designates the lower bound of an interval as the estimated type when the length is below a threshold value. Simulation experiments conducted on both small-scale and large-scale data demonstrate that our mechanism consistently outperforms existing methods in terms of revenue maximization and query reduction, particularly in large-scale scenarios. This makes our proposed mechanism a highly desirable and effective option for sellers in the realm of multi-item auctions.