 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Language Models Know the Answer Before Decoding
Aug 27, 2025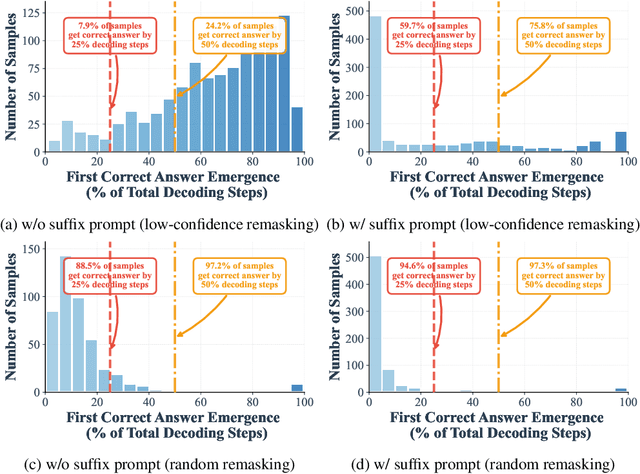
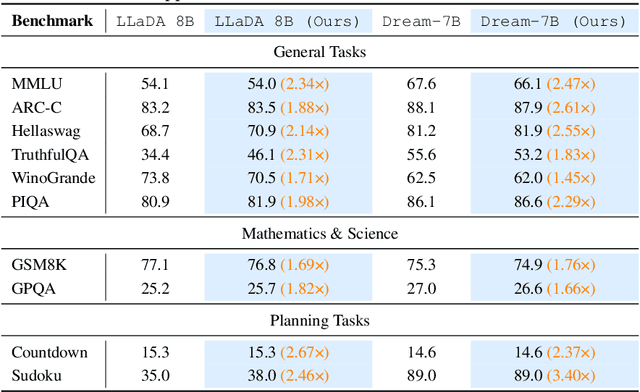
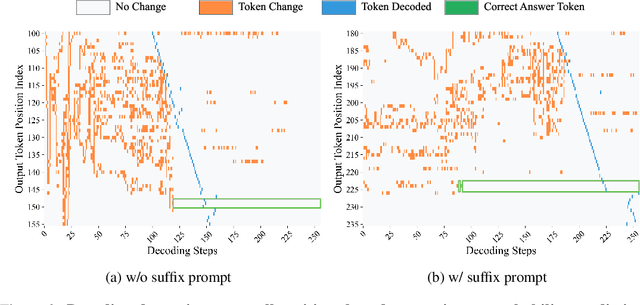
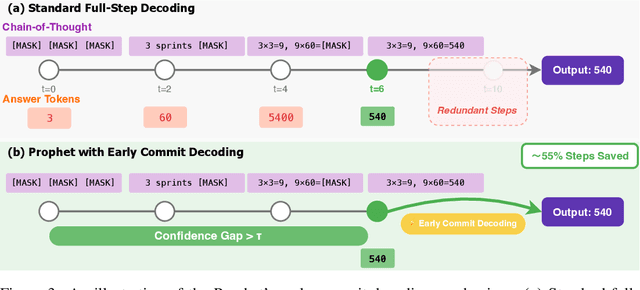
Diffusion language models (DLMs) have recently emerged as an alternative to autoregressive approaches, offering parallel sequence generation and flexible token orders. However, their inference remains slower than that of autoregressive models, primarily due to the cost of bidirectional attention and the large number of refinement steps required for high quality outputs. In this work, we highlight and leverage an overlooked property of DLMs early answer convergence: in many cases, the correct answer can be internally identified by half steps before the final decoding step, both under semi-autoregressive and random remasking schedules. For example, on GSM8K and MMLU, up to 97% and 99% of instances, respectively, can be decoded correctly using only half of the refinement steps. Building on this observation, we introduce Prophet, a training-free fast decoding paradigm that enables early commit decoding. Specifically, Prophet dynamically decides whether to continue refinement or to go "all-in" (i.e., decode all remaining tokens in one step), using the confidence gap between the top-2 prediction candidates as the criterion. It integrates seamlessly into existing DLM implementations, incurs negligible overhead, and requires no additional training. Empirical evaluations of LLaDA-8B and Dream-7B across multiple tasks show that Prophet reduces the number of decoding steps by up to 3.4x while preserving high generation quality. These results recast DLM decoding as a problem of when to stop sampling, and demonstrate that early decode convergence provides a simple yet powerful mechanism for accelerating DLM inference, complementary to existing speedup techniques. Our code is publicly available at https://github.com/pixeli99/Prophet.
Integrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024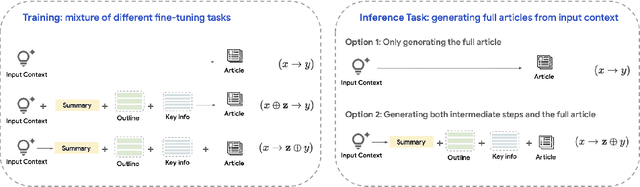

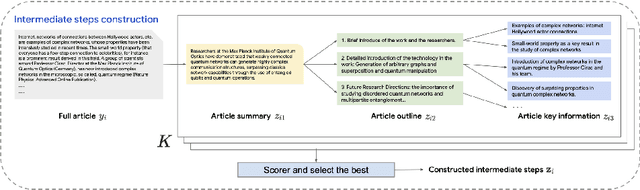
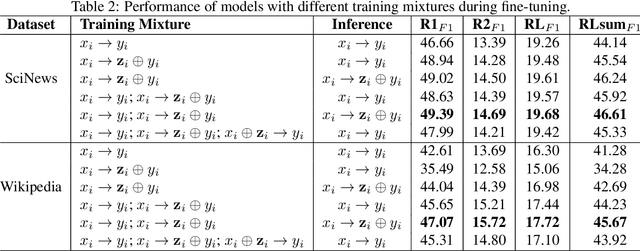
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Model-GLUE: Democratized LLM Scaling for A Large Model Zoo in the Wild
Oct 07, 2024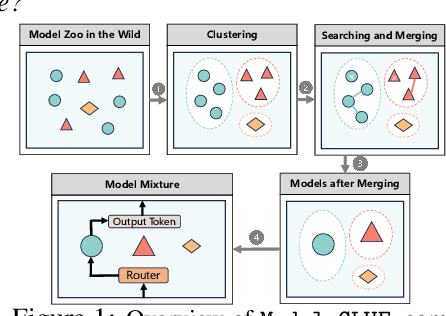

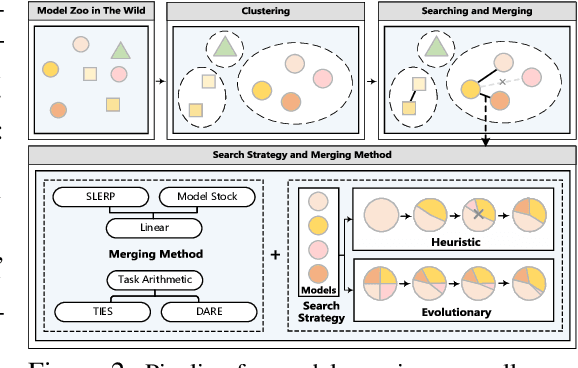
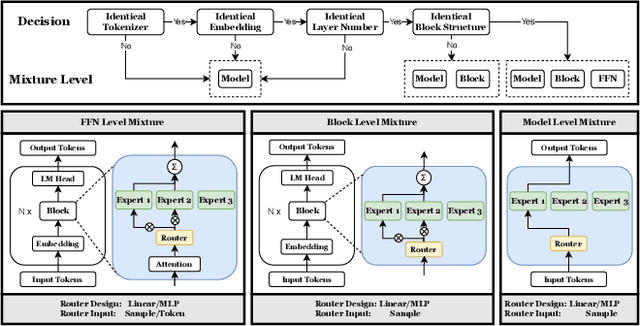
As Large Language Models (LLMs) excel across tasks and specialized domains, scaling LLMs based on existing models has garnered significant attention, which faces the challenge of decreasing performance when combining disparate models. Various techniques have been proposed for the aggregation of pre-trained LLMs, including model merging, Mixture-of-Experts, and stacking. Despite their merits, a comprehensive comparison and synergistic application of them to a diverse model zoo is yet to be adequately addressed. In light of this research gap, this paper introduces Model-GLUE, a holistic LLM scaling guideline. First, our work starts with a benchmarking of existing LLM scaling techniques, especially selective merging, and variants of mixture. Utilizing the insights from the benchmark results, we formulate an strategy for the selection and aggregation of a heterogeneous model zoo characterizing different architectures and initialization. Our methodology involves the clustering of mergeable models and optimal merging strategy selection, and the integration of clusters through a model mixture. Finally, evidenced by our experiments on a diverse Llama-2-based model zoo, Model-GLUE shows an average performance enhancement of 5.61%, achieved without additional training. Codes are available at: https://github.com/Model-GLUE/Model-GLUE.
Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation
Jul 22, 2024



Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. They are trained using preference datasets where each example consists of one input prompt, two responses, and a preference label. As curating a high-quality human labeled preference dataset is both time-consuming and expensive, people often rely on existing powerful LLMs for preference label generation. This can potentially introduce noise and impede RM training. In this work, we present RMBoost, a novel synthetic preference data generation paradigm to boost reward model quality. Unlike traditional methods, which generate two responses before obtaining the preference label, RMBoost first generates one response and selects a preference label, followed by generating the second more (or less) preferred response conditioned on the pre-selected preference label and the first response. This approach offers two main advantages. First, RMBoost reduces labeling noise since preference pairs are constructed intentionally. Second, RMBoost facilitates the creation of more diverse responses by incorporating various quality aspects (e.g., helpfulness, relevance, completeness) into the prompts. We conduct extensive experiments across three diverse datasets and demonstrate that RMBoost outperforms other synthetic preference data generation techniques and significantly boosts the performance of four distinct reward models.
Online Drift Detection with Maximum Concept Discrepancy
Jul 07, 2024Continuous learning from an immense volume of data streams becomes exceptionally critical in the internet era. However, data streams often do not conform to the same distribution over time, leading to a phenomenon called concept drift. Since a fixed static model is unreliable for inferring concept-drifted data streams, establishing an adaptive mechanism for detecting concept drift is crucial. Current methods for concept drift detection primarily assume that the labels or error rates of downstream models are given and/or underlying statistical properties exist in data streams. These approaches, however, struggle to address high-dimensional data streams with intricate irregular distribution shifts, which are more prevalent in real-world scenarios. In this paper, we propose MCD-DD, a novel concept drift detection method based on maximum concept discrepancy, inspired by the maximum mean discrepancy. Our method can adaptively identify varying forms of concept drift by contrastive learning of concept embeddings without relying on labels or statistical properties. With thorough experiments under synthetic and real-world scenarios, we demonstrate that the proposed method outperforms existing baselines in identifying concept drifts and enables qualitative analysis with high explainability.
Making Pre-trained Language Models Better Continual Few-Shot Relation Extractors
Feb 24, 2024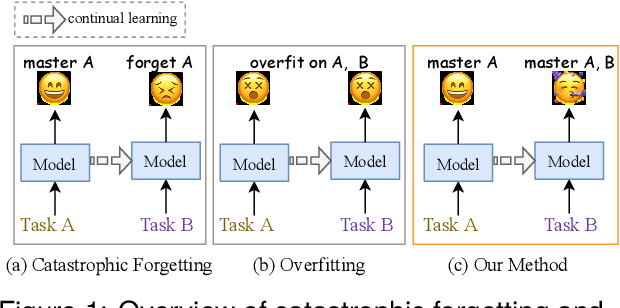
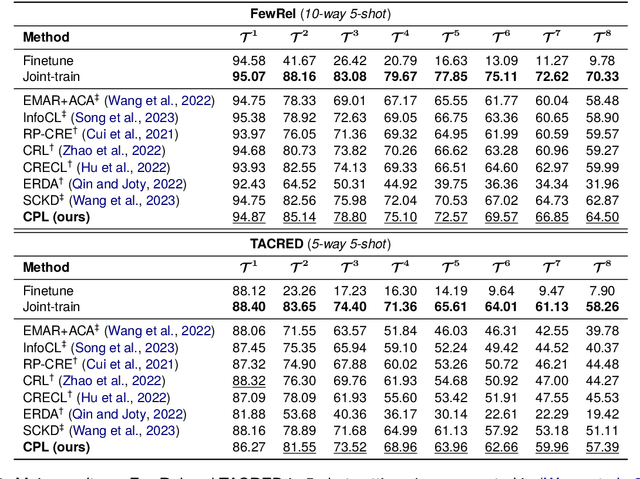


Continual Few-shot Relation Extraction (CFRE) is a practical problem that requires the model to continuously learn novel relations while avoiding forgetting old ones with few labeled training data. The primary challenges are catastrophic forgetting and overfitting. This paper harnesses prompt learning to explore the implicit capabilities of pre-trained language models to address the above two challenges, thereby making language models better continual few-shot relation extractors. Specifically, we propose a Contrastive Prompt Learning framework, which designs prompt representation to acquire more generalized knowledge that can be easily adapted to old and new categories, and margin-based contrastive learning to focus more on hard samples, therefore alleviating catastrophic forgetting and overfitting issues. To further remedy overfitting in low-resource scenarios, we introduce an effective memory augmentation strategy that employs well-crafted prompts to guide ChatGPT in generating diverse samples. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin and significantly mitigates catastrophic forgetting and overfitting in low-resource scenarios.
Non-Intrusive Adaptation: Input-Centric Parameter-efficient Fine-Tuning for Versatile Multimodal Modeling
Oct 18, 2023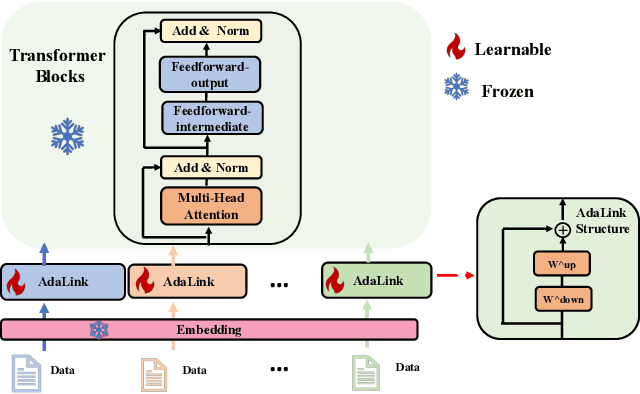



Large language models (LLMs) and vision language models (VLMs) demonstrate excellent performance on a wide range of tasks by scaling up parameter counts from O(10^9) to O(10^{12}) levels and further beyond. These large scales make it impossible to adapt and deploy fully specialized models given a task of interest. Parameter-efficient fine-tuning (PEFT) emerges as a promising direction to tackle the adaptation and serving challenges for such large models. We categorize PEFT techniques into two types: intrusive and non-intrusive. Intrusive PEFT techniques directly change a model's internal architecture. Though more flexible, they introduce significant complexities for training and serving. Non-intrusive PEFT techniques leave the internal architecture unchanged and only adapt model-external parameters, such as embeddings for input. In this work, we describe AdaLink as a non-intrusive PEFT technique that achieves competitive performance compared to SoTA intrusive PEFT (LoRA) and full model fine-tuning (FT) on various tasks. We evaluate using both text-only and multimodal tasks, with experiments that account for both parameter-count scaling and training regime (with and without instruction tuning).
Automated Evaluation of Personalized Text Generation using Large Language Models
Oct 17, 2023



Personalized text generation presents a specialized mechanism for delivering content that is specific to a user's personal context. While the research progress in this area has been rapid, evaluation still presents a challenge. Traditional automated metrics such as BLEU and ROUGE primarily measure lexical similarity to human-written references, and are not able to distinguish personalization from other subtle semantic aspects, thus falling short of capturing the nuances of personalized generated content quality. On the other hand, human judgments are costly to obtain, especially in the realm of personalized evaluation. Inspired by these challenges, we explore the use of large language models (LLMs) for evaluating personalized text generation, and examine their ability to understand nuanced user context. We present AuPEL, a novel evaluation method that distills three major semantic aspects of the generated text: personalization, quality and relevance, and automatically measures these aspects. To validate the effectiveness of AuPEL, we design carefully controlled experiments and compare the accuracy of the evaluation judgments made by LLMs versus that of judgements made by human annotators, and conduct rigorous analyses of the consistency and sensitivity of the proposed metric. We find that, compared to existing evaluation metrics, AuPEL not only distinguishes and ranks models based on their personalization abilities more accurately, but also presents commendable consistency and efficiency for this task. Our work suggests that using LLMs as the evaluators of personalized text generation is superior to traditional text similarity metrics, even though interesting new challenges still remain.
Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity
Oct 08, 2023Large Language Models (LLMs), renowned for their remarkable performance, present a challenge due to their colossal model size when it comes to practical deployment. In response to this challenge, efforts have been directed toward the application of traditional network pruning techniques to LLMs, uncovering a massive number of parameters can be pruned in one-shot without hurting performance. Building upon insights gained from pre-LLM models, prevailing LLM pruning strategies have consistently adhered to the practice of uniformly pruning all layers at equivalent sparsity. However, this observation stands in contrast to the prevailing trends observed in the field of vision models, where non-uniform layerwise sparsity typically yields substantially improved results. To elucidate the underlying reasons for this disparity, we conduct a comprehensive analysis of the distribution of token features within LLMs. In doing so, we discover a strong correlation with the emergence of outliers, defined as features exhibiting significantly greater magnitudes compared to their counterparts in feature dimensions. Inspired by this finding, we introduce a novel LLM pruning methodology that incorporates a tailored set of non-uniform layerwise sparsity ratios specifically designed for LLM pruning, termed as Outlier Weighed Layerwise sparsity (OWL). The sparsity ratio of OWL is directly proportional to the outlier ratio observed within each layer, facilitating a more effective alignment between layerwise weight sparsity and outlier ratios. Our empirical evaluation, conducted across the LLaMA-V1 family and OPT, spanning various benchmarks, demonstrates the distinct advantages offered by OWL over previous methods. For instance, our approach exhibits a remarkable performance gain, surpassing the state-of-the-art Wanda and SparseGPT by 61.22 and 6.80 perplexity at a high sparsity level of 70%, respectively.
DeeDiff: Dynamic Uncertainty-Aware Early Exiting for Accelerating Diffusion Model Generation
Sep 29, 2023Diffusion models achieve great success in generating diverse and high-fidelity images. The performance improvements come with low generation speed per image, which hinders the application diffusion models in real-time scenarios. While some certain predictions benefit from the full computation of the model in each sample iteration, not every iteration requires the same amount of computation, potentially leading to computation waste. In this work, we propose DeeDiff, an early exiting framework that adaptively allocates computation resources in each sampling step to improve the generation efficiency of diffusion models. Specifically, we introduce a timestep-aware uncertainty estimation module (UEM) for diffusion models which is attached to each intermediate layer to estimate the prediction uncertainty of each layer. The uncertainty is regarded as the signal to decide if the inference terminates. Moreover, we propose uncertainty-aware layer-wise loss to fill the performance gap between full models and early-exited models. With such loss strategy, our model is able to obtain comparable results as full-layer models. Extensive experiments of class-conditional, unconditional, and text-guided generation on several datasets show that our method achieves state-of-the-art performance and efficiency trade-off compared with existing early exiting methods on diffusion models. More importantly, our method even brings extra benefits to baseline models and obtains better performance on CIFAR-10 and Celeb-A datasets. Full code and model are released for reproduction.