 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboStereo: Dual-Tower 4D Embodied World Models for Unified Policy Optimization
Mar 13, 2026Scalable Embodied AI faces fundamental constraints due to prohibitive costs and safety risks of real-world interaction. While Embodied World Models (EWMs) offer promise through imagined rollouts, existing approaches suffer from geometric hallucinations and lack unified optimization frameworks for practical policy improvement. We introduce RoboStereo, a symmetric dual-tower 4D world model that employs bidirectional cross-modal enhancement to ensure spatiotemporal geometric consistency and alleviate physics hallucinations. Building upon this high-fidelity 4D simulator, we present the first unified framework for world-model-based policy optimization: (1) Test-Time Policy Augmentation (TTPA) for pre-execution verification, (2) Imitative-Evolutionary Policy Learning (IEPL) leveraging visual perceptual rewards to learn from expert demonstrations, and (3) Open-Exploration Policy Learning (OEPL) enabling autonomous skill discovery and self-correction. Comprehensive experiments demonstrate RoboStereo achieves state-of-the-art generation quality, with our unified framework delivering >97% average relative improvement on fine-grained manipulation tasks.
Learning Personalized Agents from Human Feedback
Feb 18, 2026Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.
A Spatial-Spectral-Frequency Interactive Network for Multimodal Remote Sensing Classification
Oct 06, 2025Deep learning-based methods have achieved significant success in remote sensing Earth observation data analysis. Numerous feature fusion techniques address multimodal remote sensing image classification by integrating global and local features. However, these techniques often struggle to extract structural and detail features from heterogeneous and redundant multimodal images. With the goal of introducing frequency domain learning to model key and sparse detail features, this paper introduces the spatial-spectral-frequency interaction network (S$^2$Fin), which integrates pairwise fusion modules across the spatial, spectral, and frequency domains. Specifically, we propose a high-frequency sparse enhancement transformer that employs sparse spatial-spectral attention to optimize the parameters of the high-frequency filter. Subsequently, a two-level spatial-frequency fusion strategy is introduced, comprising an adaptive frequency channel module that fuses low-frequency structures with enhanced high-frequency details, and a high-frequency resonance mask that emphasizes sharp edges via phase similarity. In addition, a spatial-spectral attention fusion module further enhances feature extraction at intermediate layers of the network. Experiments on four benchmark multimodal datasets with limited labeled data demonstrate that S$^2$Fin performs superior classification, outperforming state-of-the-art methods. The code is available at https://github.com/HaoLiu-XDU/SSFin.
Consistency Trajectory Matching for One-Step Generative Super-Resolution
Mar 27, 2025Current diffusion-based super-resolution (SR) approaches achieve commendable performance at the cost of high inference overhead. Therefore, distillation techniques are utilized to accelerate the multi-step teacher model into one-step student model. Nevertheless, these methods significantly raise training costs and constrain the performance of the student model by the teacher model. To overcome these tough challenges, we propose Consistency Trajectory Matching for Super-Resolution (CTMSR), a distillation-free strategy that is able to generate photo-realistic SR results in one step. Concretely, we first formulate a Probability Flow Ordinary Differential Equation (PF-ODE) trajectory to establish a deterministic mapping from low-resolution (LR) images with noise to high-resolution (HR) images. Then we apply the Consistency Training (CT) strategy to directly learn the mapping in one step, eliminating the necessity of pre-trained diffusion model. To further enhance the performance and better leverage the ground-truth during the training process, we aim to align the distribution of SR results more closely with that of the natural images. To this end, we propose to minimize the discrepancy between their respective PF-ODE trajectories from the LR image distribution by our meticulously designed Distribution Trajectory Matching (DTM) loss, resulting in improved realism of our recovered HR images. Comprehensive experimental results demonstrate that the proposed methods can attain comparable or even superior capabilities on both synthetic and real datasets while maintaining minimal inference latency.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.
Channel Merging: Preserving Specialization for Merged Experts
Dec 18, 2024Lately, the practice of utilizing task-specific fine-tuning has been implemented to improve the performance of large language models (LLM) in subsequent tasks. Through the integration of diverse LLMs, the overall competency of LLMs is significantly boosted. Nevertheless, traditional ensemble methods are notably memory-intensive, necessitating the simultaneous loading of all specialized models into GPU memory. To address the inefficiency, model merging strategies have emerged, merging all LLMs into one model to reduce the memory footprint during inference. Despite these advances, model merging often leads to parameter conflicts and performance decline as the number of experts increases. Previous methods to mitigate these conflicts include post-pruning and partial merging. However, both approaches have limitations, particularly in terms of performance and storage efficiency when merged experts increase. To address these challenges, we introduce Channel Merging, a novel strategy designed to minimize parameter conflicts while enhancing storage efficiency. This method clusters and merges channel parameters based on their similarity to form several groups offline. By ensuring that only highly similar parameters are merged within each group, it significantly reduces parameter conflicts. During inference, we can instantly look up the expert parameters from the merged groups, preserving specialized knowledge. Our experiments demonstrate that Channel Merging consistently delivers high performance, matching unmerged models in tasks like English and Chinese reasoning, mathematical reasoning, and code generation. Moreover, it obtains results comparable to model ensemble with just 53% parameters when used with a task-specific router.
Disentangling the Prosody and Semantic Information with Pre-trained Model for In-Context Learning based Zero-Shot Voice Conversion
Sep 10, 2024Voice conversion (VC) aims to modify the speaker's timbre while retaining speech content. Previous approaches have tokenized the outputs from self-supervised into semantic tokens, facilitating disentanglement of speech content information. Recently, in-context learning (ICL) has emerged in text-to-speech (TTS) systems for effectively modeling specific characteristics such as timbre through context conditioning. This paper proposes an ICL capability enhanced VC system (ICL-VC) employing a mask and reconstruction training strategy based on flow-matching generative models. Augmented with semantic tokens, our experiments on the LibriTTS dataset demonstrate that ICL-VC improves speaker similarity. Additionally, we find that k-means is a versatile tokenization method applicable to various pre-trained models. However, the ICL-VC system faces challenges in preserving the prosody of the source speech. To mitigate this issue, we propose incorporating prosody embeddings extracted from a pre-trained emotion recognition model into our system. Integration of prosody embeddings notably enhances the system's capability to preserve source speech prosody, as validated on the Emotional Speech Database.
DTFormer: A Transformer-Based Method for Discrete-Time Dynamic Graph Representation Learning
Jul 26, 2024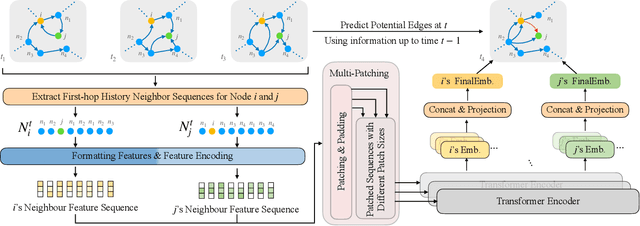
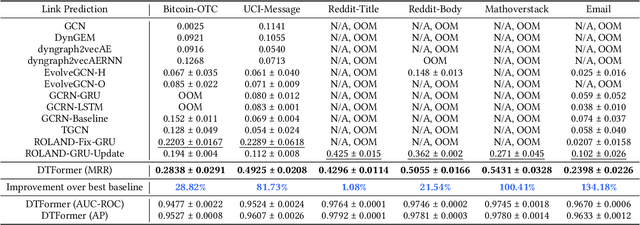
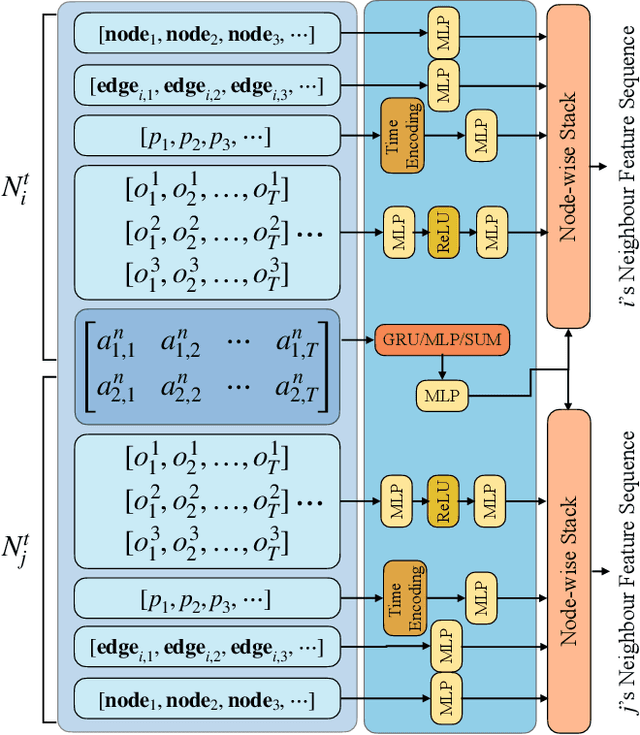
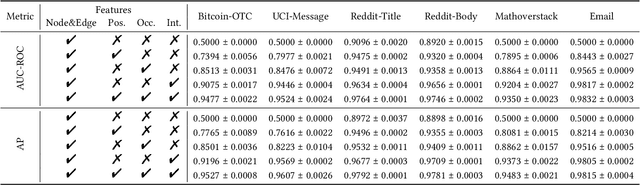
Discrete-Time Dynamic Graphs (DTDGs), which are prevalent in real-world implementations and notable for their ease of data acquisition, have garnered considerable attention from both academic researchers and industry practitioners. The representation learning of DTDGs has been extensively applied to model the dynamics of temporally changing entities and their evolving connections. Currently, DTDG representation learning predominantly relies on GNN+RNN architectures, which manifest the inherent limitations of both Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs). GNNs suffer from the over-smoothing issue as the models architecture goes deeper, while RNNs struggle to capture long-term dependencies effectively. GNN+RNN architectures also grapple with scaling to large graph sizes and long sequences. Additionally, these methods often compute node representations separately and focus solely on individual node characteristics, thereby overlooking the behavior intersections between the two nodes whose link is being predicted, such as instances where the two nodes appear together in the same context or share common neighbors. This paper introduces a novel representation learning method DTFormer for DTDGs, pivoting from the traditional GNN+RNN framework to a Transformer-based architecture. Our approach exploits the attention mechanism to concurrently process topological information within the graph at each timestamp and temporal dynamics of graphs along the timestamps, circumventing the aforementioned fundamental weakness of both GNNs and RNNs. Moreover, we enhance the model's expressive capability by incorporating the intersection relationships among nodes and integrating a multi-patching module. Extensive experiments conducted on six public dynamic graph benchmark datasets confirm our model's efficacy, achieving the SOTA performance.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Jul 23, 2024Retrieval Augmented Generation (RAG) has been a powerful tool for Large Language Models (LLMs) to efficiently process overly lengthy contexts. However, recent LLMs like Gemini-1.5 and GPT-4 show exceptional capabilities to understand long contexts directly. We conduct a comprehensive comparison between RAG and long-context (LC) LLMs, aiming to leverage the strengths of both. We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG's significantly lower cost remains a distinct advantage. Based on this observation, we propose Self-Route, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. Self-Route significantly reduces the computation cost while maintaining a comparable performance to LC. Our findings provide a guideline for long-context applications of LLMs using RAG and LC.
RefXVC: Cross-Lingual Voice Conversion with Enhanced Reference Leveraging
Jun 24, 2024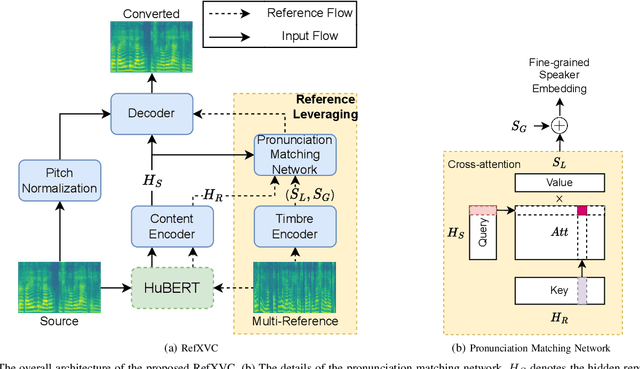

This paper proposes RefXVC, a method for cross-lingual voice conversion (XVC) that leverages reference information to improve conversion performance. Previous XVC works generally take an average speaker embedding to condition the speaker identity, which does not account for the changing timbre of speech that occurs with different pronunciations. To address this, our method uses both global and local speaker embeddings to capture the timbre changes during speech conversion. Additionally, we observed a connection between timbre and pronunciation in different languages and utilized this by incorporating a timbre encoder and a pronunciation matching network into our model. Furthermore, we found that the variation in tones is not adequately reflected in a sentence, and therefore, we used multiple references to better capture the range of a speaker's voice. The proposed method outperformed existing systems in terms of both speech quality and speaker similarity, highlighting the effectiveness of leveraging reference information in cross-lingual voice conversion. The converted speech samples can be found on the website: \url{http://refxvc.dn3point.com}