 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
Dec 12, 2025Diffusion models have significantly advanced the field of talking head generation. However, the slow inference speeds and non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, the first diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through high spatiotemporal VAE compression. Additionally, to enable autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles to key-value caching for maintaining temporal consistency and identity coherence during long-time streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) training strategy is proposed to mitigate error accumulation in autoregressive generation and enhance temporal consistency, which leverages a non-streaming teacher with an asynchronous noise schedule to supervise the training of the streaming student model. REST bridges the gap between autoregressive and diffusion-based approaches, demonstrating substantial value for applications requiring real-time talking head generation. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.
ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025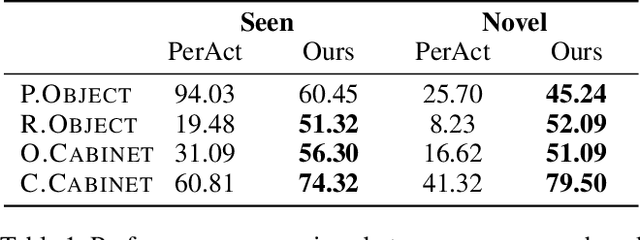
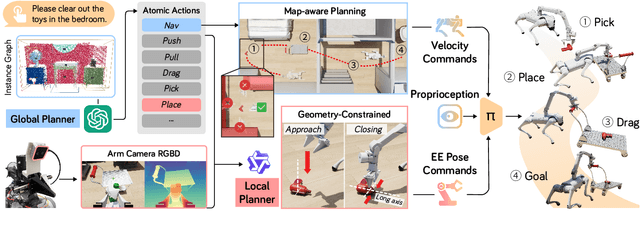


Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time Distillation
Jun 24, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency. Project page: https://euminds.github.io/motionecho/
UP-SLAM: Adaptively Structured Gaussian SLAM with Uncertainty Prediction in Dynamic Environments
May 28, 2025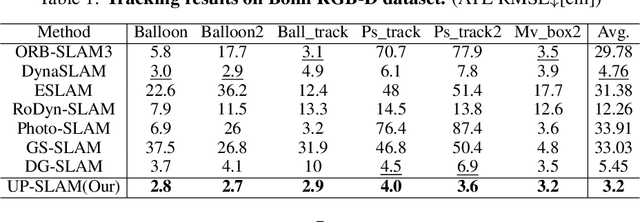
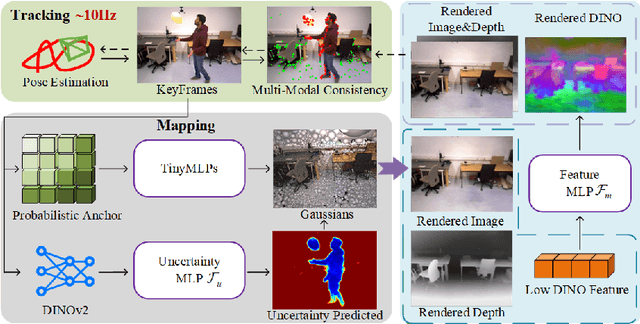

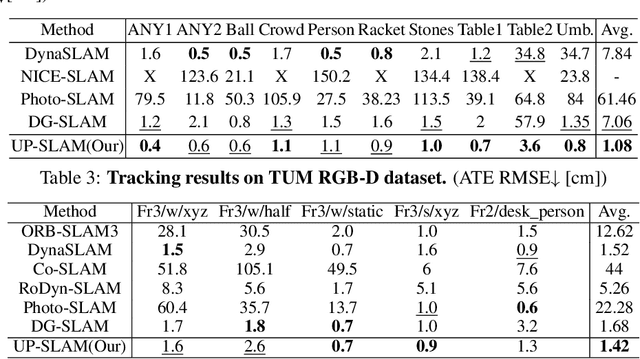
Recent 3D Gaussian Splatting (3DGS) techniques for Visual Simultaneous Localization and Mapping (SLAM) have significantly progressed in tracking and high-fidelity mapping. However, their sequential optimization framework and sensitivity to dynamic objects limit real-time performance and robustness in real-world scenarios. We present UP-SLAM, a real-time RGB-D SLAM system for dynamic environments that decouples tracking and mapping through a parallelized framework. A probabilistic octree is employed to manage Gaussian primitives adaptively, enabling efficient initialization and pruning without hand-crafted thresholds. To robustly filter dynamic regions during tracking, we propose a training-free uncertainty estimator that fuses multi-modal residuals to estimate per-pixel motion uncertainty, achieving open-set dynamic object handling without reliance on semantic labels. Furthermore, a temporal encoder is designed to enhance rendering quality. Concurrently, low-dimensional features are efficiently transformed via a shallow multilayer perceptron to construct DINO features, which are then employed to enrich the Gaussian field and improve the robustness of uncertainty prediction. Extensive experiments on multiple challenging datasets suggest that UP-SLAM outperforms state-of-the-art methods in both localization accuracy (by 59.8%) and rendering quality (by 4.57 dB PSNR), while maintaining real-time performance and producing reusable, artifact-free static maps in dynamic environments.The project: https://aczheng-cai.github.io/up_slam.github.io/
Channel Merging: Preserving Specialization for Merged Experts
Dec 18, 2024Lately, the practice of utilizing task-specific fine-tuning has been implemented to improve the performance of large language models (LLM) in subsequent tasks. Through the integration of diverse LLMs, the overall competency of LLMs is significantly boosted. Nevertheless, traditional ensemble methods are notably memory-intensive, necessitating the simultaneous loading of all specialized models into GPU memory. To address the inefficiency, model merging strategies have emerged, merging all LLMs into one model to reduce the memory footprint during inference. Despite these advances, model merging often leads to parameter conflicts and performance decline as the number of experts increases. Previous methods to mitigate these conflicts include post-pruning and partial merging. However, both approaches have limitations, particularly in terms of performance and storage efficiency when merged experts increase. To address these challenges, we introduce Channel Merging, a novel strategy designed to minimize parameter conflicts while enhancing storage efficiency. This method clusters and merges channel parameters based on their similarity to form several groups offline. By ensuring that only highly similar parameters are merged within each group, it significantly reduces parameter conflicts. During inference, we can instantly look up the expert parameters from the merged groups, preserving specialized knowledge. Our experiments demonstrate that Channel Merging consistently delivers high performance, matching unmerged models in tasks like English and Chinese reasoning, mathematical reasoning, and code generation. Moreover, it obtains results comparable to model ensemble with just 53% parameters when used with a task-specific router.
GSORB-SLAM: Gaussian Splatting SLAM benefits from ORB features and Transmittance information
Oct 15, 2024The emergence of 3D Gaussian Splatting (3DGS) has recently sparked a renewed wave of dense visual SLAM research. However, current methods face challenges such as sensitivity to artifacts and noise, sub-optimal selection of training viewpoints, and a lack of light global optimization. In this paper, we propose a dense SLAM system that tightly couples 3DGS with ORB features. We design a joint optimization approach for robust tracking and effectively reducing the impact of noise and artifacts. This involves combining novel geometric observations, derived from accumulated transmittance, with ORB features extracted from pixel data. Furthermore, to improve mapping quality, we propose an adaptive Gaussian expansion and regularization method that enables Gaussian primitives to represent the scene compactly. This is coupled with a viewpoint selection strategy based on the hybrid graph to mitigate over-fitting effects and enhance convergence quality. Finally, our approach achieves compact and high-quality scene representations and accurate localization. GSORB-SLAM has been evaluated on different datasets, demonstrating outstanding performance. The code will be available.
Formal Verification and Control with Conformal Prediction
Aug 31, 2024
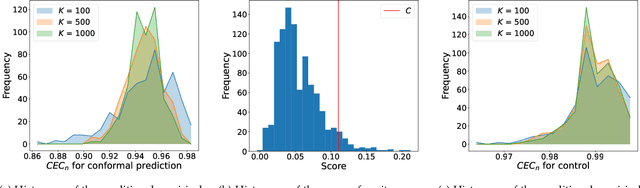
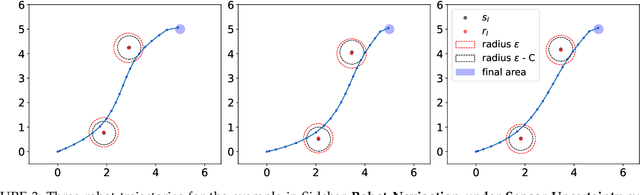
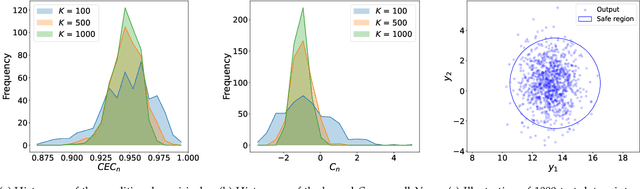
In this survey, we design formal verification and control algorithms for autonomous systems with practical safety guarantees using conformal prediction (CP), a statistical tool for uncertainty quantification. We focus on learning-enabled autonomous systems (LEASs) in which the complexity of learning-enabled components (LECs) is a major bottleneck that hampers the use of existing model-based verification and design techniques. Instead, we advocate for the use of CP, and we will demonstrate its use in formal verification, systems and control theory, and robotics. We argue that CP is specifically useful due to its simplicity (easy to understand, use, and modify), generality (requires no assumptions on learned models and data distributions, i.e., is distribution-free), and efficiency (real-time capable and accurate). We pursue the following goals with this survey. First, we provide an accessible introduction to CP for non-experts who are interested in using CP to solve problems in autonomy. Second, we show how to use CP for the verification of LECs, e.g., for verifying input-output properties of neural networks. Third and fourth, we review recent articles that use CP for safe control design as well as offline and online verification of LEASs. We summarize their ideas in a unifying framework that can deal with the complexity of LEASs in a computationally efficient manner. In our exposition, we consider simple system specifications, e.g., robot navigation tasks, as well as complex specifications formulated in temporal logic formalisms. Throughout our survey, we compare to other statistical techniques (e.g., scenario optimization, PAC-Bayes theory, etc.) and how these techniques have been used in verification and control. Lastly, we point the reader to open problems and future research directions.
Boosting Box-supervised Instance Segmentation with Pseudo Depth
Mar 02, 2024The realm of Weakly Supervised Instance Segmentation (WSIS) under box supervision has garnered substantial attention, showcasing remarkable advancements in recent years. However, the limitations of box supervision become apparent in its inability to furnish effective information for distinguishing foreground from background within the specified target box. This research addresses this challenge by introducing pseudo-depth maps into the training process of the instance segmentation network, thereby boosting its performance by capturing depth differences between instances. These pseudo-depth maps are generated using a readily available depth predictor and are not necessary during the inference stage. To enable the network to discern depth features when predicting masks, we integrate a depth prediction layer into the mask prediction head. This innovative approach empowers the network to simultaneously predict masks and depth, enhancing its ability to capture nuanced depth-related information during the instance segmentation process. We further utilize the mask generated in the training process as supervision to distinguish the foreground from the background. When selecting the best mask for each box through the Hungarian algorithm, we use depth consistency as one calculation cost item. The proposed method achieves significant improvements on Cityscapes and COCO dataset.
Conformal Predictive Programming for Chance Constrained Optimization
Feb 12, 2024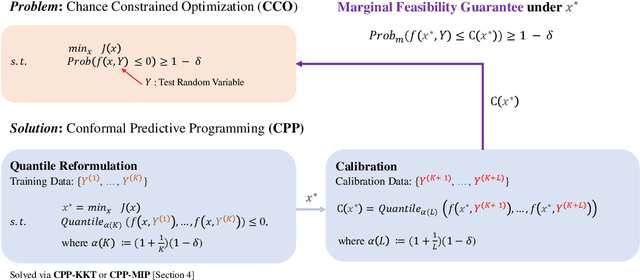


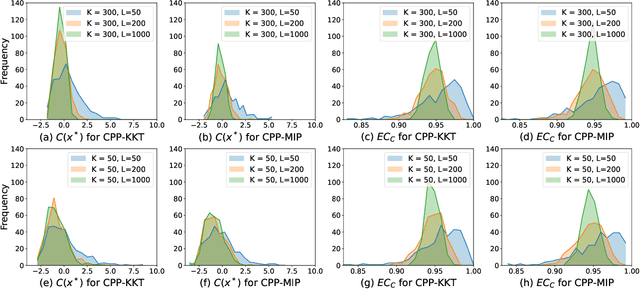
Motivated by the advances in conformal prediction (CP), we propose conformal predictive programming (CPP), an approach to solve chance constrained optimization (CCO) problems, i.e., optimization problems with nonlinear constraint functions affected by arbitrary random parameters. CPP utilizes samples from these random parameters along with the quantile lemma -- which is central to CP -- to transform the CCO problem into a deterministic optimization problem. We then present two tractable reformulations of CPP by: (1) writing the quantile as a linear program along with its KKT conditions (CPP-KKT), and (2) using mixed integer programming (CPP-MIP). CPP comes with marginal probabilistic feasibility guarantees for the CCO problem that are conceptually different from existing approaches, e.g., the sample approximation and the scenario approach. While we explore algorithmic similarities with the sample approximation approach, we emphasize that the strength of CPP is that it can easily be extended to incorporate different variants of CP. To illustrate this, we present robust conformal predictive programming to deal with distribution shifts in the uncertain parameters of the CCO problem.
Diffusion-based Data Augmentation for Nuclei Image Segmentation
Oct 22, 2023Nuclei segmentation is a fundamental but challenging task in the quantitative analysis of histopathology images. Although fully-supervised deep learning-based methods have made significant progress, a large number of labeled images are required to achieve great segmentation performance. Considering that manually labeling all nuclei instances for a dataset is inefficient, obtaining a large-scale human-annotated dataset is time-consuming and labor-intensive. Therefore, augmenting a dataset with only a few labeled images to improve the segmentation performance is of significant research and application value. In this paper, we introduce the first diffusion-based augmentation method for nuclei segmentation. The idea is to synthesize a large number of labeled images to facilitate training the segmentation model. To achieve this, we propose a two-step strategy. In the first step, we train an unconditional diffusion model to synthesize the Nuclei Structure that is defined as the representation of pixel-level semantic and distance transform. Each synthetic nuclei structure will serve as a constraint on histopathology image synthesis and is further post-processed to be an instance map. In the second step, we train a conditioned diffusion model to synthesize histopathology images based on nuclei structures. The synthetic histopathology images paired with synthetic instance maps will be added to the real dataset for training the segmentation model. The experimental results show that by augmenting 10% labeled real dataset with synthetic samples, one can achieve comparable segmentation results with the fully-supervised baseline.