 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSDNet: Raw Domain Demoiréing via Dual Color-Space Synergy
Apr 22, 2025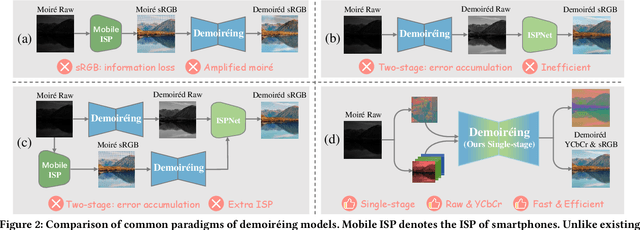
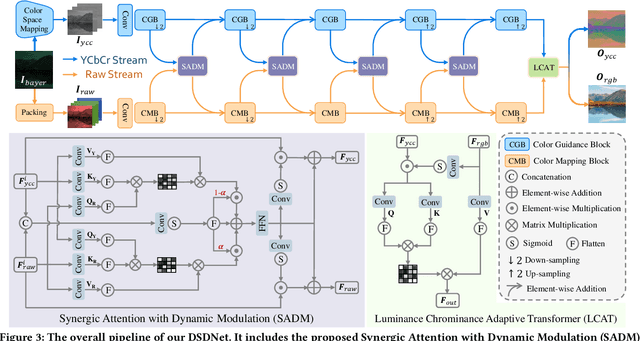
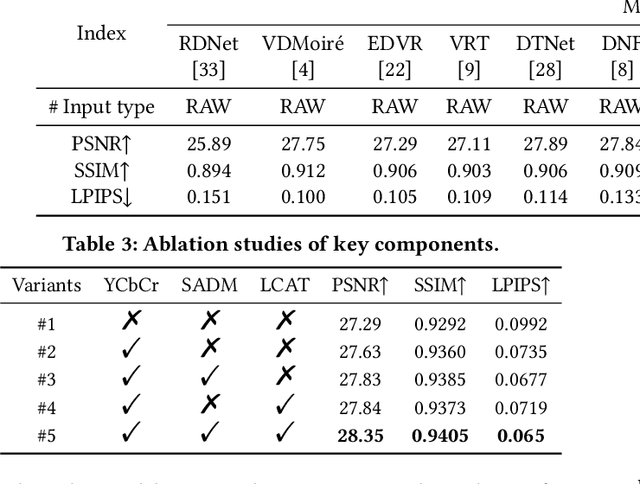
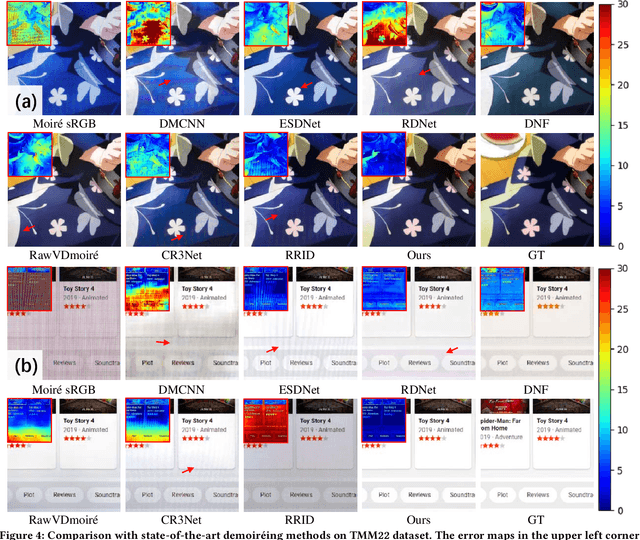
With the rapid advancement of mobile imaging, capturing screens using smartphones has become a prevalent practice in distance learning and conference recording. However, moir\'e artifacts, caused by frequency aliasing between display screens and camera sensors, are further amplified by the image signal processing pipeline, leading to severe visual degradation. Existing sRGB domain demoir\'eing methods struggle with irreversible information loss, while recent two-stage raw domain approaches suffer from information bottlenecks and inference inefficiency. To address these limitations, we propose a single-stage raw domain demoir\'eing framework, Dual-Stream Demoir\'eing Network (DSDNet), which leverages the synergy of raw and YCbCr images to remove moir\'e while preserving luminance and color fidelity. Specifically, to guide luminance correction and moir\'e removal, we design a raw-to-YCbCr mapping pipeline and introduce the Synergic Attention with Dynamic Modulation (SADM) module. This module enriches the raw-to-sRGB conversion with cross-domain contextual features. Furthermore, to better guide color fidelity, we develop a Luminance-Chrominance Adaptive Transformer (LCAT), which decouples luminance and chrominance representations. Extensive experiments demonstrate that DSDNet outperforms state-of-the-art methods in both visual quality and quantitative evaluation, and achieves an inference speed $\mathrm{\textbf{2.4x}}$ faster than the second-best method, highlighting its practical advantages. We provide an anonymous online demo at https://xxxxxxxxdsdnet.github.io/DSDNet/.
Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
Dec 16, 2024



Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image's aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.
CPA: Camera-pose-awareness Diffusion Transformer for Video Generation
Dec 02, 2024Despite the significant advancements made by Diffusion Transformer (DiT)-based methods in video generation, there remains a notable gap with controllable camera pose perspectives. Existing works such as OpenSora do NOT adhere precisely to anticipated trajectories and physical interactions, thereby limiting the flexibility in downstream applications. To alleviate this issue, we introduce CPA, a unified camera-pose-awareness text-to-video generation approach that elaborates the camera movement and integrates the textual, visual, and spatial conditions. Specifically, we deploy the Sparse Motion Encoding (SME) module to transform camera pose information into a spatial-temporal embedding and activate the Temporal Attention Injection (TAI) module to inject motion patches into each ST-DiT block. Our plug-in architecture accommodates the original DiT parameters, facilitating diverse types of camera poses and flexible object movement. Extensive qualitative and quantitative experiments demonstrate that our method outperforms LDM-based methods for long video generation while achieving optimal performance in trajectory consistency and object consistency.
DGCformer: Deep Graph Clustering Transformer for Multivariate Time Series Forecasting
May 14, 2024



Multivariate time series forecasting tasks are usually conducted in a channel-dependent (CD) way since it can incorporate more variable-relevant information. However, it may also involve a lot of irrelevant variables, and this even leads to worse performance than the channel-independent (CI) strategy. This paper combines the strengths of both strategies and proposes the Deep Graph Clustering Transformer (DGCformer) for multivariate time series forecasting. Specifically, it first groups these relevant variables by a graph convolutional network integrated with an autoencoder, and a former-latter masked self-attention mechanism is then considered with the CD strategy being applied to each group of variables while the CI one for different groups. Extensive experimental results on eight datasets demonstrate the superiority of our method against state-of-the-art models, and our code will be publicly available upon acceptance.
Clinical Domain Knowledge-Derived Template Improves Post Hoc AI Explanations in Pneumothorax Classification
Mar 26, 2024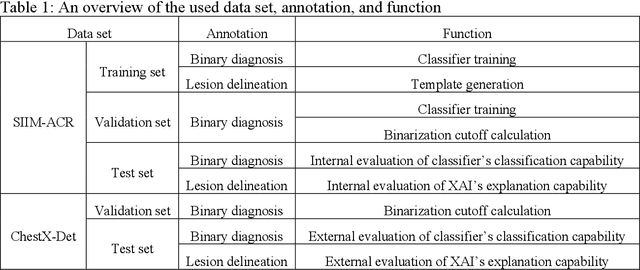



Background: Pneumothorax is an acute thoracic disease caused by abnormal air collection between the lungs and chest wall. To address the opaqueness often associated with deep learning (DL) models, explainable artificial intelligence (XAI) methods have been introduced to outline regions related to pneumothorax diagnoses made by DL models. However, these explanations sometimes diverge from actual lesion areas, highlighting the need for further improvement. Method: We propose a template-guided approach to incorporate the clinical knowledge of pneumothorax into model explanations generated by XAI methods, thereby enhancing the quality of these explanations. Utilizing one lesion delineation created by radiologists, our approach first generates a template that represents potential areas of pneumothorax occurrence. This template is then superimposed on model explanations to filter out extraneous explanations that fall outside the template's boundaries. To validate its efficacy, we carried out a comparative analysis of three XAI methods with and without our template guidance when explaining two DL models in two real-world datasets. Results: The proposed approach consistently improved baseline XAI methods across twelve benchmark scenarios built on three XAI methods, two DL models, and two datasets. The average incremental percentages, calculated by the performance improvements over the baseline performance, were 97.8% in Intersection over Union (IoU) and 94.1% in Dice Similarity Coefficient (DSC) when comparing model explanations and ground-truth lesion areas. Conclusions: In the context of pneumothorax diagnoses, we proposed a template-guided approach for improving AI explanations. We anticipate that our template guidance will forge a fresh approach to elucidating AI models by integrating clinical domain expertise.
Boosting Box-supervised Instance Segmentation with Pseudo Depth
Mar 02, 2024The realm of Weakly Supervised Instance Segmentation (WSIS) under box supervision has garnered substantial attention, showcasing remarkable advancements in recent years. However, the limitations of box supervision become apparent in its inability to furnish effective information for distinguishing foreground from background within the specified target box. This research addresses this challenge by introducing pseudo-depth maps into the training process of the instance segmentation network, thereby boosting its performance by capturing depth differences between instances. These pseudo-depth maps are generated using a readily available depth predictor and are not necessary during the inference stage. To enable the network to discern depth features when predicting masks, we integrate a depth prediction layer into the mask prediction head. This innovative approach empowers the network to simultaneously predict masks and depth, enhancing its ability to capture nuanced depth-related information during the instance segmentation process. We further utilize the mask generated in the training process as supervision to distinguish the foreground from the background. When selecting the best mask for each box through the Hungarian algorithm, we use depth consistency as one calculation cost item. The proposed method achieves significant improvements on Cityscapes and COCO dataset.